Estadística en Python: manipulando datos en Pandas (Parte II)
01/11/2017
Antes de pasar a otros temas vamos a mencionar como podemos manipular los DataFrame en Pandas. Imaginemos que tenemos una tabla con datos de estatura y peso. Podemos generar una nueva columna con el índice de masa corporal. Veamos como se puede hacer
A veces queremos quedarnos con parte de los datos que cumplen una condición. Hay varias maneras de hacerlo.
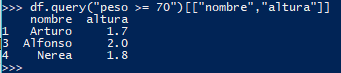
Ejemplo: Quédate con los datos de Nombre y Altura de los pacientes con peso igual o superior a 70
Cualquiera de estos tres métodos pueden usarse indistintamente.
Apply es una función de DataFrame muy potente que permite aplicar una función a todos las columnas o a todas las filas.
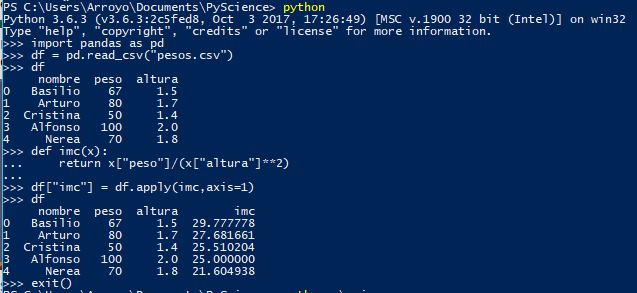
Ejemplo: Calcule el IMC (Índice de Masa Corporal) con los valores de la tabla
¿Qué pasa si queremos borrar algún dato o columna?
Si queremos borrar columnas:
Si queremos borrar datos:
Normalmente los datos los leeremos de algún archivo o base de datos (read_csv, read_json, read_html, read_sql, read_hdf, read_msgpack, read_excel, read_pickle, read_gbq, read_parquet, ...) pero puede darse el caso de que necesitemos ingresar los datos manualmente. El constructor de DataFrame admite diccionarios, arrays de NumPy y arrays de tuplas.
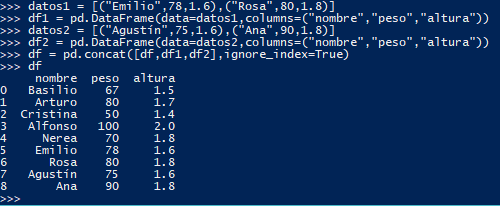
Si tenemos varios DataFrames de características similares (columnas iguales) podemos unirlos. Hay que tener cuidado con los índices. Si el tema de los índices te da igual, usa ignore_index.
Si vienes del mundo SQL quizá te suene el tema de los JOIN. En Pandas existe un potente sistema de join, similar al usado en las bases de datos SQL más importantes y con excelente rendimiento. Pandas soporta joins de tipo LEFT, RIGHT, OUTER e INNER.
 Con esto ya sabemos lo básico para manejarnos con DataFrames de Pandas
Con esto ya sabemos lo básico para manejarnos con DataFrames de Pandas
Fichero de ejemplo
nombre,peso,altura
Basilio,67,1.5
Arturo,80,1.7
Cristina,50,1.4
Alfonso,100,2.0
Nerea,70,1.8
Seleccionado datos
A veces queremos quedarnos con parte de los datos que cumplen una condición. Hay varias maneras de hacerlo.
Ejemplo: Quédate con los datos de Nombre y Altura de los pacientes con peso igual o superior a 70
import pandas as pd
df = pd.read_csv("pesos.csv")
tab = df.loc[df["peso"] >= 70,["nombre","altura"]]
import pandas as pd
df = pd.read_csv("pesos.csv")
tab = df[df["peso"] >= 70][["nombre","altura"]]
import pandas as pd
df = pd.read_csv("pesos.csv")
tab = df.query("peso >= 70")[["nombre","altura"]]
Cualquiera de estos tres métodos pueden usarse indistintamente.
Apply
Apply es una función de DataFrame muy potente que permite aplicar una función a todos las columnas o a todas las filas.
Ejemplo: Calcule el IMC (Índice de Masa Corporal) con los valores de la tabla
import pandas as pd
df = pd.read_csv("pesos.csv")
def imc(x):
return x["peso"]/(x["altura"]**2)
df["imc"] = df.apply(imc,axis=1)
print(df)
Drop
¿Qué pasa si queremos borrar algún dato o columna?
Si queremos borrar columnas:
df.drop(["peso"],axis=1)
Si queremos borrar datos:
df.drop(ELEMENTOS,inplace=True)
# puede haber una condicion compleja
df.drop(df[df["altura"] < 1.6].index,axis=0,inplace=True)
Construyendo el DataFrame a mano
Normalmente los datos los leeremos de algún archivo o base de datos (read_csv, read_json, read_html, read_sql, read_hdf, read_msgpack, read_excel, read_pickle, read_gbq, read_parquet, ...) pero puede darse el caso de que necesitemos ingresar los datos manualmente. El constructor de DataFrame admite diccionarios, arrays de NumPy y arrays de tuplas.
import pandas as pd
import numpy as np
datos_dict = {"peso": [50,60], "altura": [1.6,1.7]}
df = pd.DataFrame(data=datos_dict)
datos_numpy = np.array([[50,1.6],[70,1.7]])
df = pd.DataFrame(data=datos_numpy,columns=("peso","altura"))
datos_tuple = [(50,1.6),(70,1.7)]
df = pd.DataFrame(data=datos_tuple,columns=("peso","altura"))
Concatenar DataFrames
Si tenemos varios DataFrames de características similares (columnas iguales) podemos unirlos. Hay que tener cuidado con los índices. Si el tema de los índices te da igual, usa ignore_index.
import pandas as pd
df = pd.read_csv("pesos.csv")
datos1 = [("Emilio",78,1.6),("Rosa",80,1.8)]
df1 = pd.DataFrame(data=datos1,columns=("nombre","peso","altura"))
datos2 = [("Agustín",75,1.6),("Ana",90,1.8)]
df2 = pd.DataFrame(data=datos2,columns=("nombre","peso","altura"))
df = pd.concat([df,df1,df2],ignore_index=True)
Join DataFrames
Si vienes del mundo SQL quizá te suene el tema de los JOIN. En Pandas existe un potente sistema de join, similar al usado en las bases de datos SQL más importantes y con excelente rendimiento. Pandas soporta joins de tipo LEFT, RIGHT, OUTER e INNER.
import pandas as pd
df = pd.read_csv("pesos.csv")
otros_datos = [("Nerea",19),("Irena",21)]
tab_edad = pd.DataFrame(data=otros_datos,columns=("nombre","edad"))
tab_right = pd.merge(df,tab_edad,on="nombre",how="right")
tab_left = pd.merge(df,tab_edad,on="nombre",how="left")
tab_inner = pd.merge(df,tab_edad,on="nombre",how="inner")
tab_outer = pd.merge(df,tab_edad,on="nombre",how="outer")
Con esto ya sabemos lo básico para manejarnos con DataFrames de Pandas