Ley de Zipf en el blog
Estaba yo leyendo uno de mis blogs favoritos, Los días y las frases, que pese a lo que se pueda pensar de mí, no trata, ni remotamente de tecnología, programación, etc sino de aforismos e historia. Muy entretenido, siempre leo sus artículos nada más salir. Hace unos meses ya, el autor publicó una entrada sobre la ley de Zipf. Como él lo explica mejor que nadie, voy a copiar literalmente el texto:
George Kingsley Zipf fue un lingüista norteamericano de mediados del siglo XX que se dedicó a aplicar el análisis estadístico a las lenguas.Uno de los estudios que le reportó fama fue el descubrimiento de la ley que lleva su nombre, la "Ley de Zipf", según la cual la frecuencia con la que son utilizadas las palabras siguen una distribución estadística concreta. No entraremos en detalles técnicos de su formulación, pero básicamente nos dice que la palabra más usada en un idioma (the, en inglés) aparece el doble de veces que la segunda más usada (of), y el triple que la tercera, etc.Pero esta ley de la frecuencia de las apariciones no ocurre solo con las palabras, su ámbito es mucho mayor. Por ejemplo, en el de las poblaciones de las ciudades de un país: la ciudad más grande suele tener el doble de habitantes que la segunda población de ese país. Y en general es aplicable a la ordenación de grandes conjuntos de datos... E internet, que no deja de ser una base de datos enorme,no podría ser menos, también se puede describir el número de visitas a las páginas individuales de Internet en un intervalo de tiempo dado... (Artículo https://diasyfrases.blogspot.com/2019/09/cumple-este-blog-con-la-ley-de-zipf.html)

A continuación, prueba con los artículos del blog, según número de visitas, a ver si la popularidad sigue esta curiosa ley, a priori, relacionada con la lingüística. ¡Al parecer Los días y las frases sigue una distribución similar a la ley de Zipf! ¿Y mi blog, Adrianistán? ¿Seguirá también la ley de Zipf?
Experimento
Voy a tomar los datos del mes de octubre, ya que es el más próximo que ya ha acabado y considero que es un mes representativo, bastante normalillo. Además, las entradas que publiqué en octubre no parecen haber tenido demasiado impacto en general. También he decidido quitar la página de inicio, ya que no es un artículo como tal.
El artículo más visto del mes es Estadística en Python Parte 3 con 1327 visitas. A partir de aquí podemos calcular las visitas estimadas según la ley, dividiendo progresivamente.
| Artículos | Visitas Reales | Visitas Zipf |
|---|---|---|
| /estadistica-python-media-mediana-varianza-percentiles-parte-iii | 1327 | 1327 |
| /estadistica-python-distribucion-binomial-normal-poisson-parte-vi | 445 | 663.5 |
| /estadistica-python-pandas-numpy-scipy-parte-i | 434 | 442.333333333333 |
| /rust-101-tutorial-rust-espanol | 328 | 331.75 |
| /introduccion-a-prolog-tutorial-en-espanol | 233 | 265.4 |
| /tutorial-de-cmake | 199 | 221.166666666667 |
| /estadistica-python-analisis-datos-multidimensionales-regresion-lineal-parte-iv | 162 | 189.571428571429 |
| /cosas-no-sabias-python | 151 | 165.875 |
| /estadistica-python-ajustar-datos-una-distribucion-parte-vii | 134 | 147.444444444444 |
(veo que os gusta mucho la estadística con Python)
Vemos que hay números muy próximos a la estimación, pero mejor hagamos un gráfico.
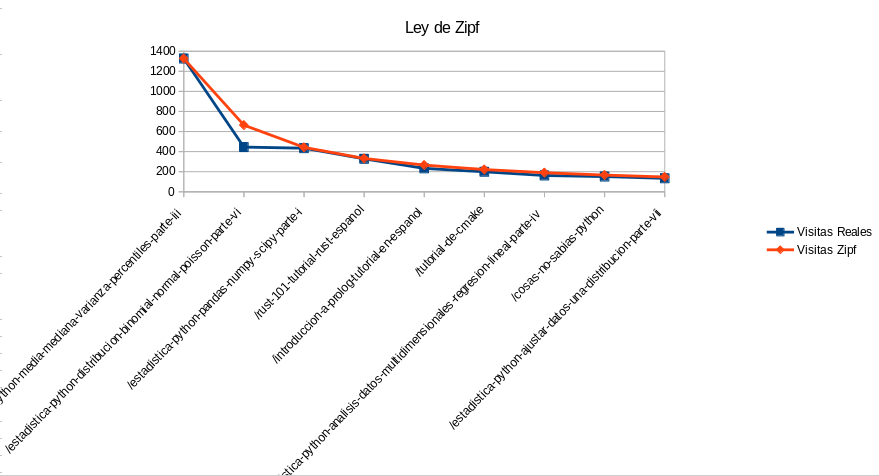
Vemos que la curva real se ajusta relativamente bien a la curva estimada por la ley de Zipf. El punto donde más se aleja (tanto absoluto como relativamente) es el segundo artículo.
Podríamos decir, que sí, en Adrianistán también se aplica la ley de Zipf. ¿Será, quizá, que esta ley se aplica en todos los sistemas de información? ¿Es parte intrínseca de la realidad? Os dejo reflexionar