Estadística en Python: análisis de datos multidimensionales y regresión lineal (Parte IV)
15/11/2017
Hasta ahora hemos tratado con una única variable por separado. Ahora vamos a ver qué podemos hacer con varias variables en la misma muestra (conjunto de datos). Nos interesará saber si están relacionadas o no (independencia o no). Si existe relación (estan correlacionadas) vamos a construir un modelo de regresión lineal.
En el caso de dos variables, podemos construir una distribución conjunta de frecuencias. Se trata de una tabla de doble entrada donde cada dimensión corresponde a cada variable y el valor de las celdas representa la frecuencia del par. Para ello podemos usar crosstab también (de hecho, su uso original es este).
Ejemplo: En las votaciones a alcalde de la ciudad de Valladolid se presentaban Rafael, Silvia y Olga. Analiza los resultados e informa de quién fue el ganador de las elecciones. ¿Quién fue el candidato favorito en el barrio de La Rondilla?
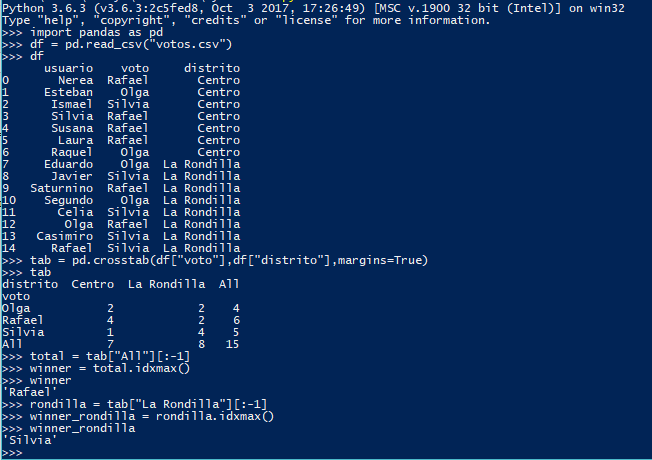 Como podéis ver, un humando podría haber sacado estas conclusiones observando simplemente la tabla conjunta de frecuencias. ¿Quién tiene más votos en total? Rafael, con 6 en All (la suma de los distritos). ¿Quién ha sacado más votos en La Rondilla? Silvia, con 4 en la columna de La Rondilla. Por último, ¿votó más gente en el Centro o en La Rondilla? Votaron más en La Rondilla (8 votos), que en el Centro (7 votos).
Como podéis ver, un humando podría haber sacado estas conclusiones observando simplemente la tabla conjunta de frecuencias. ¿Quién tiene más votos en total? Rafael, con 6 en All (la suma de los distritos). ¿Quién ha sacado más votos en La Rondilla? Silvia, con 4 en la columna de La Rondilla. Por último, ¿votó más gente en el Centro o en La Rondilla? Votaron más en La Rondilla (8 votos), que en el Centro (7 votos).
A las frecuencias All se las llama comúnmente distribuciones marginales. Cuando discriminamos las frecuencias a un solo valor de una variable, se habla de distribuciones condicionadas, en este caso hemos usado la distribución de votos condicionada al distrito La Rondilla. Estas distribuciones son univariantes como habréis sospechado.
Una manera muy útil de observar posibles correlaciones es con el gráfico XY, solamente disponible para distribuciones bivariantes. Cada observación se representa en el plano como un punto. En Matplotlib podemos dibujarlo con scatter.
Ejemplo: Represente el gráfico XY de las variables ingresos y gastos de las familias.
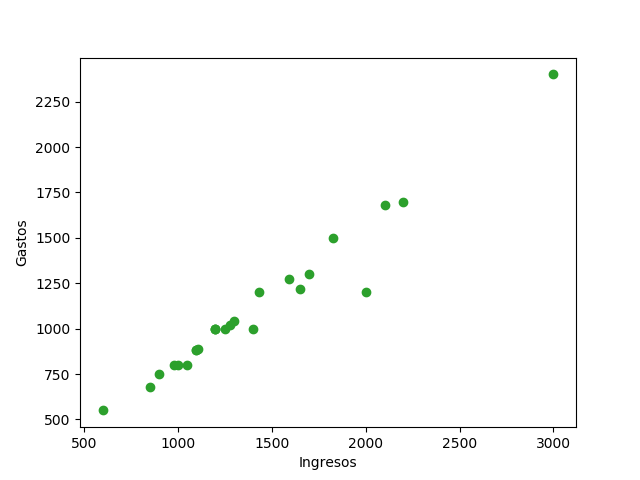 En la imagen podemos ver cada dato representado por un punto. En este ejemplo puede apreciarse como los puntos estan en torno a una línea recta invisible.
En la imagen podemos ver cada dato representado por un punto. En este ejemplo puede apreciarse como los puntos estan en torno a una línea recta invisible.
Para medir la relación entre dos variables podemos definir la covarianza:
Pandas trae el método cov para calcular la matriz de covarianzas. De esta matriz, obtendremos el valor que nos interesa.
¿Y la covarianza qué nos dice? Por si mismo, bastante poco. Como mucho, si es positivo nos dice que se relacionarían de forma directa y si es negativa de forma inversa. Pero la covarianza está presente en muchas fórmulas.
Uno de los métodos que usa la covarianza (aunque Pandas lo va a hacer solo) es el coeficiente de correlación lineal de Pearson. Cuanto más se acerque a 1 o -1 más correlacionadas están las variables. Su uso en Pandas es muy similar a la covarianza.
En este ejemplo concreto, el coeficiente de correlación de Pearson nos da 0.976175. Se trata de un valor lo suficientemente alto como para plantearnos una correlación lineal. Es decir, que pueda ser aproximado por una recta. Si este coeficiente es igual a 1 o -1, se puede decir que una variable es fruto de una transformación lineal de la otra.
Vamos a intentar encontrar un modelo lineal que se ajuste a nuestras observaciones y nos permita hacer predicciones. Esta recta se llamará recta de regresión y se calcula de la siguiente forma:
Usando las funciones de varianza, media y covarianza Pandas no es muy complicado hacer una recta de regresión:
Que podemos probar visualmente:
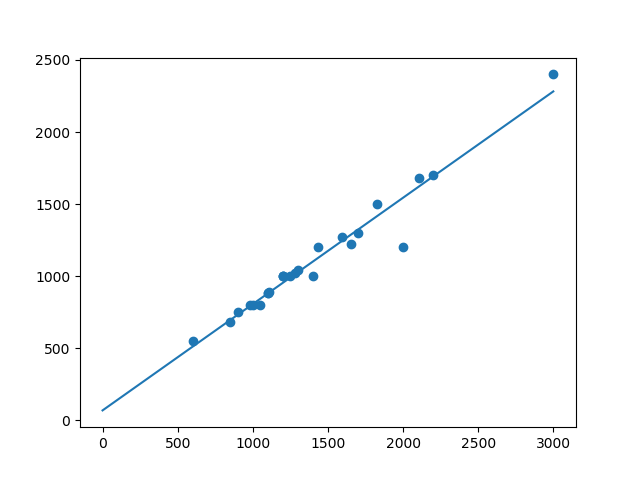 Sin embargo SciPy ya nos trae un método que calcula la pendiente, la ordenada en el origen, el coeficiente de correlación lineal de Pearson y mucho más en un solo lugar. Es mucho más eficiente, se trata de linregress.
Sin embargo SciPy ya nos trae un método que calcula la pendiente, la ordenada en el origen, el coeficiente de correlación lineal de Pearson y mucho más en un solo lugar. Es mucho más eficiente, se trata de linregress.
Además, para calcular los valores del gráfico, he usado vectorize de NumPy, que permite mapear los arrays nativos de NumPy. Más eficiente. Mismo resultado.
 ¿Quién no ha oído hablar de la Ley de Ohm? Se trata de una ley que relaciona la diferencia de potencial con el amperaje dando lugar a la resistencia. La ley fue enunciada por George Simon Ohm, aunque no exactamente como la conocemos hoy en día. En este ejemplo vamos a deducir de cero la ley de Ohm. Este ejercicio se puede hacer en casa con datos reales si se dispone de un polímetro (dos mejor) y una fuente de alimentación con tensión regulable. Este ejercicio pueden hacerlo niños sin problema.
¿Quién no ha oído hablar de la Ley de Ohm? Se trata de una ley que relaciona la diferencia de potencial con el amperaje dando lugar a la resistencia. La ley fue enunciada por George Simon Ohm, aunque no exactamente como la conocemos hoy en día. En este ejemplo vamos a deducir de cero la ley de Ohm. Este ejercicio se puede hacer en casa con datos reales si se dispone de un polímetro (dos mejor) y una fuente de alimentación con tensión regulable. Este ejercicio pueden hacerlo niños sin problema.
Olvida todo lo que sepas de la ley de Ohm
Es posible apreciar que en un circuito con una bombilla, si introducimos una pieza cerámica, la intensidad de la bombilla disminuye.
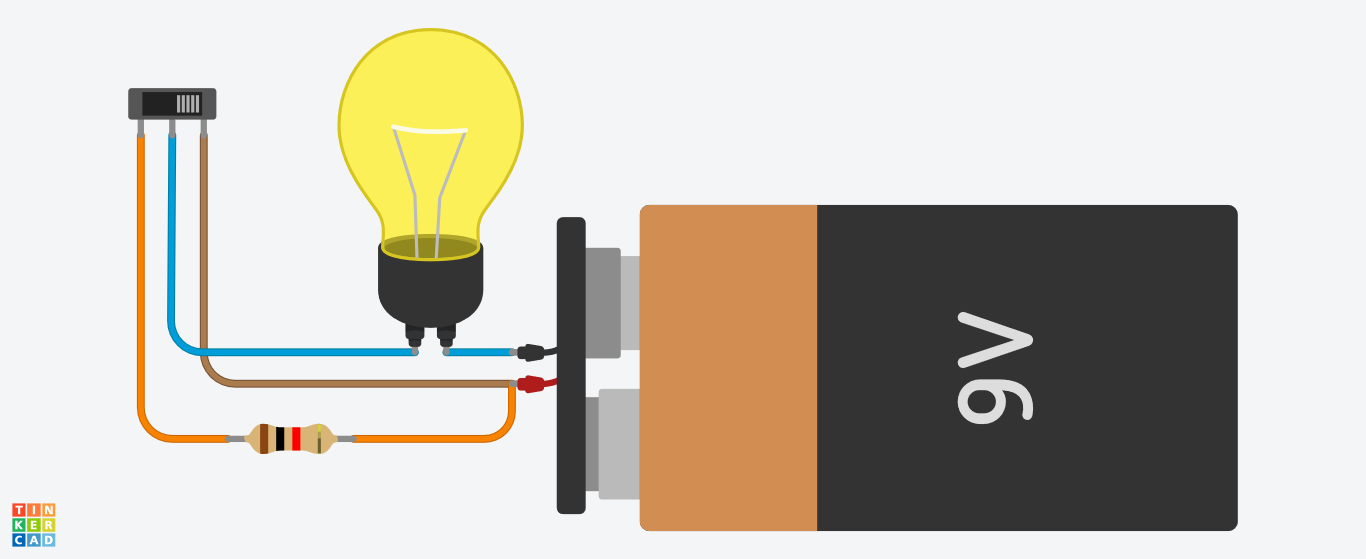
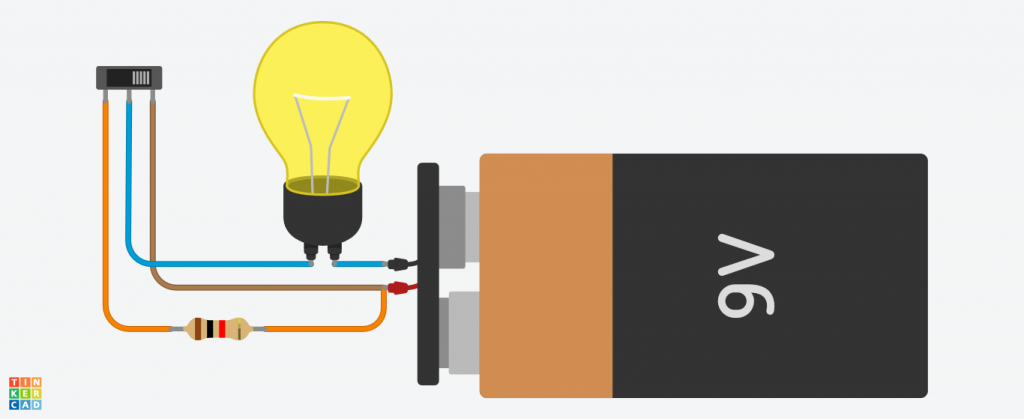 Cuando la corriente no atraviesa la resistencia
Cuando la corriente no atraviesa la resistencia
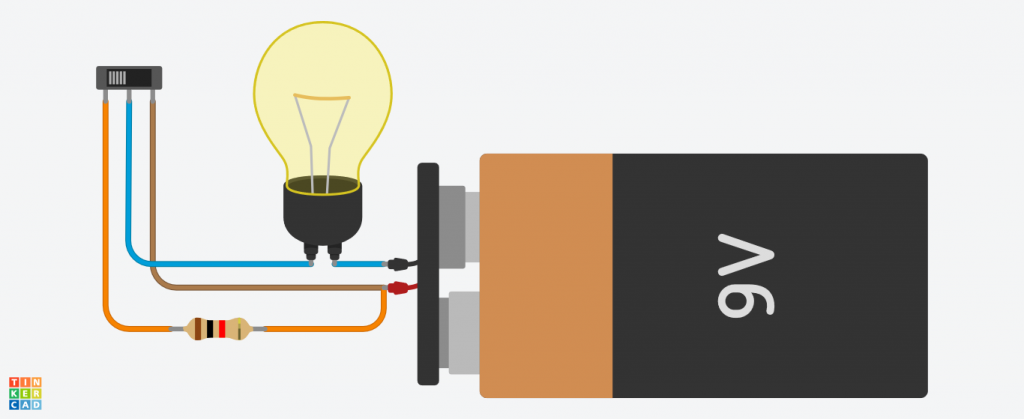 Cuando la corriente atraviesa la resistencia
Cuando la corriente atraviesa la resistencia
¿Qué ocurre exactamente? ¿Por qué la bombilla tiene menos intensidad en el segundo caso?
Vamos a aislar la resistencia. Ponemos un voltímetro y un amperímetro y vamos cambiando la tensión de entrada. Anotamos la corriente medida en cada caso.
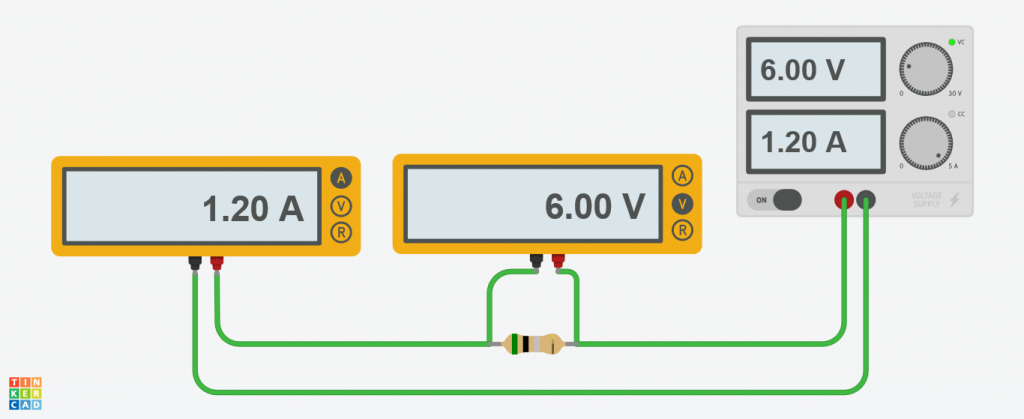
Podemos intentar hacer un ajuste lineal a estos datos. De modo, que una vez sepamos la intensidad, podamos predecir el voltaje.
Como Pearson nos da un número muy próximo a 1, podemos definir un modelo matemático siguiendo la regresión lineal.
Este modelo matemático se define así:
Y es lo que se conoce como la Ley de Ohm. En realidad, la ordenada en el origen tiene un valor muy cercano a cero, podemos quitarlo.
Así nos queda un modelo capaz de predecir lel voltaje en base a la intensidad y la pendiente de la recta. Ahora puedes probar cambiando la resistencia y observando que siempre ocurre lo mismo. Tenemos el voltaje por la pendiente del modelo. Este valor de la pendiente es lo que en física se llama resistencia y se mide en ohmios. Así se nos queda entonces la ley de Ohm que todos conocemos:
En este caso la pendiente equivalía a 4.94 Ω, valor muy cercano a los 5 Ω que dice el fabricante.
Distribución conjunta de frecuencias
En el caso de dos variables, podemos construir una distribución conjunta de frecuencias. Se trata de una tabla de doble entrada donde cada dimensión corresponde a cada variable y el valor de las celdas representa la frecuencia del par. Para ello podemos usar crosstab también (de hecho, su uso original es este).
Ejemplo: En las votaciones a alcalde de la ciudad de Valladolid se presentaban Rafael, Silvia y Olga. Analiza los resultados e informa de quién fue el ganador de las elecciones. ¿Quién fue el candidato favorito en el barrio de La Rondilla?
usuario,voto,distrito
Nerea,Rafael,Centro
Esteban,Olga,Centro
Ismael,Silvia,Centro
Silvia,Rafael,Centro
Susana,Rafael,Centro
Laura,Rafael,Centro
Raquel,Olga,Centro
Eduardo,Olga,La Rondilla
Javier,Silvia,La Rondilla
Saturnino,Rafael,La Rondilla
Segundo,Olga,La Rondilla
Celia,Silvia,La Rondilla
Olga,Rafael,La Rondilla
Casimiro,Silvia,La Rondilla
Rafael,Silvia,La Rondilla
import pandas as pd
df = pd.read_csv("votos.csv")
tab = pd.crosstab(df["voto"],df["distrito"],margins=True) # margins si queremos generar la fila y columna All
total = tab["All"][:-1]
winner = total.idxmax()
print("El ganador de las elecciones fue "+str(winner))
rondilla = tab["La Rondilla"][:-1]
winner_rondilla = rondilla.idxmax()
print("El ganador en el distrito de La Rondilla fue "+str(winner_rondilla))
Como podéis ver, un humando podría haber sacado estas conclusiones observando simplemente la tabla conjunta de frecuencias. ¿Quién tiene más votos en total? Rafael, con 6 en All (la suma de los distritos). ¿Quién ha sacado más votos en La Rondilla? Silvia, con 4 en la columna de La Rondilla. Por último, ¿votó más gente en el Centro o en La Rondilla? Votaron más en La Rondilla (8 votos), que en el Centro (7 votos).A las frecuencias All se las llama comúnmente distribuciones marginales. Cuando discriminamos las frecuencias a un solo valor de una variable, se habla de distribuciones condicionadas, en este caso hemos usado la distribución de votos condicionada al distrito La Rondilla. Estas distribuciones son univariantes como habréis sospechado.
Gráfico XY o bivariante
Una manera muy útil de observar posibles correlaciones es con el gráfico XY, solamente disponible para distribuciones bivariantes. Cada observación se representa en el plano como un punto. En Matplotlib podemos dibujarlo con scatter.
Ejemplo: Represente el gráfico XY de las variables ingresos y gastos de las familias.
id,ingresos,gastos
1,1000,800
2,1100,885
3,1100,880
4,1200,1000
5,1400,1000
6,900,750
7,600,550
8,2000,1200
9,1200,1000
10,1250,1000
11,3000,2400
12,2200,1700
13,1700,1300
14,1650,1220
15,1825,1500
16,1435,1200
17,980,800
18,1050,800
19,2105,1680
20,1280,1020
21,1590,1272
22,1300,1040
23,1200,1000
24,1110,890
25,850,680
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("ingresos_gastos.csv")
plt.scatter(df["ingresos"],df["gastos"])
plt.xlabel("Ingresos")
plt.ylabel("Gastos")
plt.show()
En la imagen podemos ver cada dato representado por un punto. En este ejemplo puede apreciarse como los puntos estan en torno a una línea recta invisible.Covarianza
Para medir la relación entre dos variables podemos definir la covarianza:
[latex]
cov_{x,y}=\frac{\sum_{i=1}^{N}(x_{i}-\bar{x})(y_{i}-\bar{y})}{N}
[/latex]
Pandas trae el método cov para calcular la matriz de covarianzas. De esta matriz, obtendremos el valor que nos interesa.
import pandas as pd
df = pd.read_csv("ingresos_gastos.csv")
covarianza = df.cov()["ingresos"]["gastos"]
¿Y la covarianza qué nos dice? Por si mismo, bastante poco. Como mucho, si es positivo nos dice que se relacionarían de forma directa y si es negativa de forma inversa. Pero la covarianza está presente en muchas fórmulas.
Coeficiente de correlación lineal de Pearson
[latex]
r_{x,y}=\frac{cov_{x,y}}{s_{x}s_{y}}
[/latex]
Uno de los métodos que usa la covarianza (aunque Pandas lo va a hacer solo) es el coeficiente de correlación lineal de Pearson. Cuanto más se acerque a 1 o -1 más correlacionadas están las variables. Su uso en Pandas es muy similar a la covarianza.
import pandas as pd
df = pd.read_csv("ingresos_gastos.csv")
r = df.corr(method="pearson")["ingresos"]["gastos"]
En este ejemplo concreto, el coeficiente de correlación de Pearson nos da 0.976175. Se trata de un valor lo suficientemente alto como para plantearnos una correlación lineal. Es decir, que pueda ser aproximado por una recta. Si este coeficiente es igual a 1 o -1, se puede decir que una variable es fruto de una transformación lineal de la otra.
Ajuste lineal
Vamos a intentar encontrar un modelo lineal que se ajuste a nuestras observaciones y nos permita hacer predicciones. Esta recta se llamará recta de regresión y se calcula de la siguiente forma:
[latex]
\hat{y}-\bar{y}=\frac{cov_{x,y}}{s_{x}^2}(x-\bar{x})
[/latex]
Usando las funciones de varianza, media y covarianza Pandas no es muy complicado hacer una recta de regresión:
def recta(x):
pendiente = df.cov()["ingresos"]["gastos"]/df["ingresos"].var()
return pendiente*(x-df["ingresos"].mean())+df["gastos"].mean()
Que podemos probar visualmente:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv("ingresos_gastos.csv")
def recta(x):
pendiente = df.cov()["ingresos"]["gastos"]/df["ingresos"].var()
return pendiente*(x-df["ingresos"].mean())+df["gastos"].mean()
line = [recta(x) for x in np.arange(3000)]
plt.scatter(df["ingresos"],df["gastos"])
plt.plot(line)
plt.show()
Sin embargo SciPy ya nos trae un método que calcula la pendiente, la ordenada en el origen, el coeficiente de correlación lineal de Pearson y mucho más en un solo lugar. Es mucho más eficiente, se trata de linregress.import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats as ss
df = pd.read_csv("ingresos_gastos.csv")
pendiente, ordenada, pearson, p, error = ss.linregress(df["ingresos"],df["gastos"])
def recta(x):
return pendiente*x + ordenada
recta = np.vectorize(recta)
linea = recta(np.arange(3000))
plt.scatter(df["ingresos"],df["gastos"])
plt.plot(linea)
plt.show()
Además, para calcular los valores del gráfico, he usado vectorize de NumPy, que permite mapear los arrays nativos de NumPy. Más eficiente. Mismo resultado.
La ley de Ohm
¿Quién no ha oído hablar de la Ley de Ohm? Se trata de una ley que relaciona la diferencia de potencial con el amperaje dando lugar a la resistencia. La ley fue enunciada por George Simon Ohm, aunque no exactamente como la conocemos hoy en día. En este ejemplo vamos a deducir de cero la ley de Ohm. Este ejercicio se puede hacer en casa con datos reales si se dispone de un polímetro (dos mejor) y una fuente de alimentación con tensión regulable. Este ejercicio pueden hacerlo niños sin problema.Olvida todo lo que sepas de la ley de Ohm
Es posible apreciar que en un circuito con una bombilla, si introducimos una pieza cerámica, la intensidad de la bombilla disminuye.
 Cuando la corriente no atraviesa la resistencia
Cuando la corriente no atraviesa la resistencia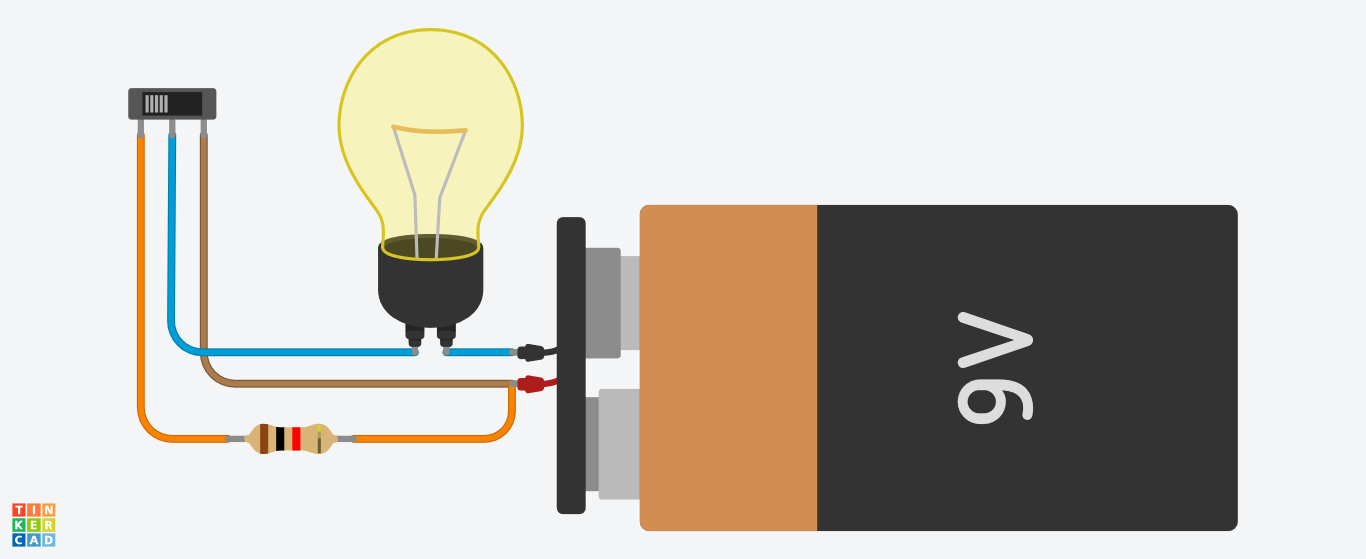 Cuando la corriente atraviesa la resistencia
Cuando la corriente atraviesa la resistencia¿Qué ocurre exactamente? ¿Por qué la bombilla tiene menos intensidad en el segundo caso?
Vamos a aislar la resistencia. Ponemos un voltímetro y un amperímetro y vamos cambiando la tensión de entrada. Anotamos la corriente medida en cada caso.
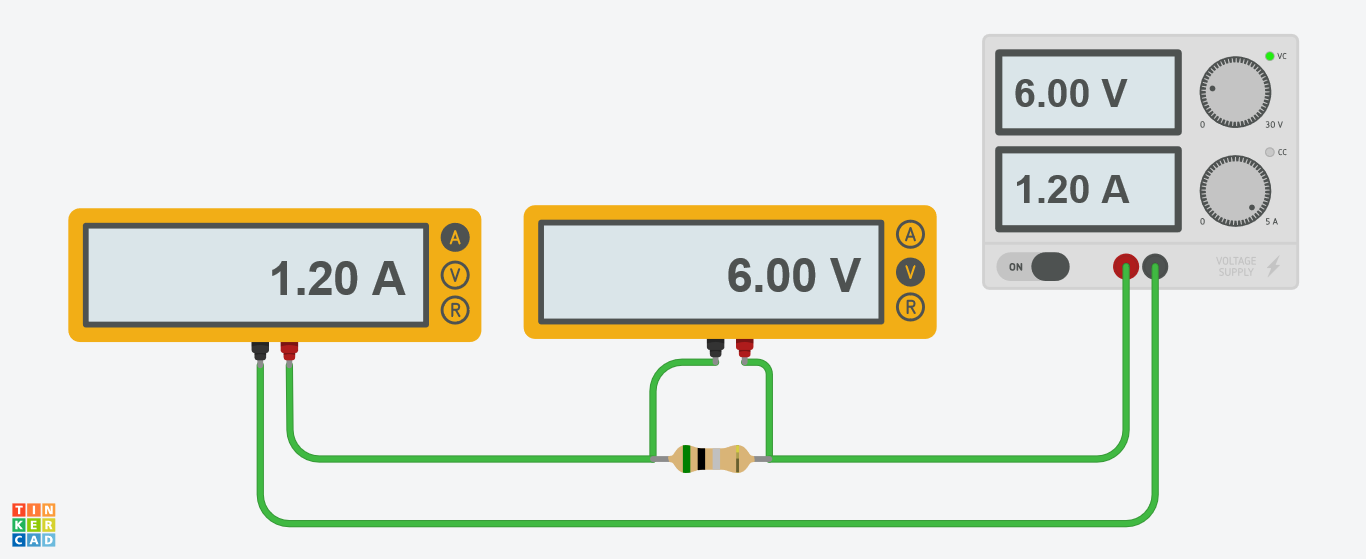
voltaje,intensidad
5,1.01
6,1.19
7,1.4
8,1.62
9,1.81
10,2.01
Podemos intentar hacer un ajuste lineal a estos datos. De modo, que una vez sepamos la intensidad, podamos predecir el voltaje.
import pandas as pd
from scipy import stats as ss
df = pd.read_csv("voltaje_intensidad.csv")
pendiente, ordenada_origen, pearson, p, error = ss.linregress(df["intensidad"],df["voltaje"])
print(pearson) # 0.99969158942375369 es un valor que indica una muy fuerte correlación lineal
Como Pearson nos da un número muy próximo a 1, podemos definir un modelo matemático siguiendo la regresión lineal.
Este modelo matemático se define así:
def voltaje(intensidad):
return intensidad*pendiente + ordenada_origen
Y es lo que se conoce como la Ley de Ohm. En realidad, la ordenada en el origen tiene un valor muy cercano a cero, podemos quitarlo.
Así nos queda un modelo capaz de predecir lel voltaje en base a la intensidad y la pendiente de la recta. Ahora puedes probar cambiando la resistencia y observando que siempre ocurre lo mismo. Tenemos el voltaje por la pendiente del modelo. Este valor de la pendiente es lo que en física se llama resistencia y se mide en ohmios. Así se nos queda entonces la ley de Ohm que todos conocemos:
[latex]
V= IR
[/latex]
En este caso la pendiente equivalía a 4.94 Ω, valor muy cercano a los 5 Ω que dice el fabricante.