Crónica de un vídeo de citas célebres
18/12/2016
Vuelvo a la carga con un problema que me ha tenido entretenido un rato y que me parece interesante contaros.
Como muchos sabréis, este año me pasé el videojuego The Witness. Es un juego muy interesante y que os recomiendo. El caso es que nunca llegué a escuchar todas las citas célebres del juego, y en YouTube solo encontré vídeos sueltos con subtítulos en... francés. Así que me propuse hacer un vídeo que recogiese todas las citas célebres del juego, con subtítulos en Español. Antes esta situación hay dos opciones:
Por supuesto, hice lo último.
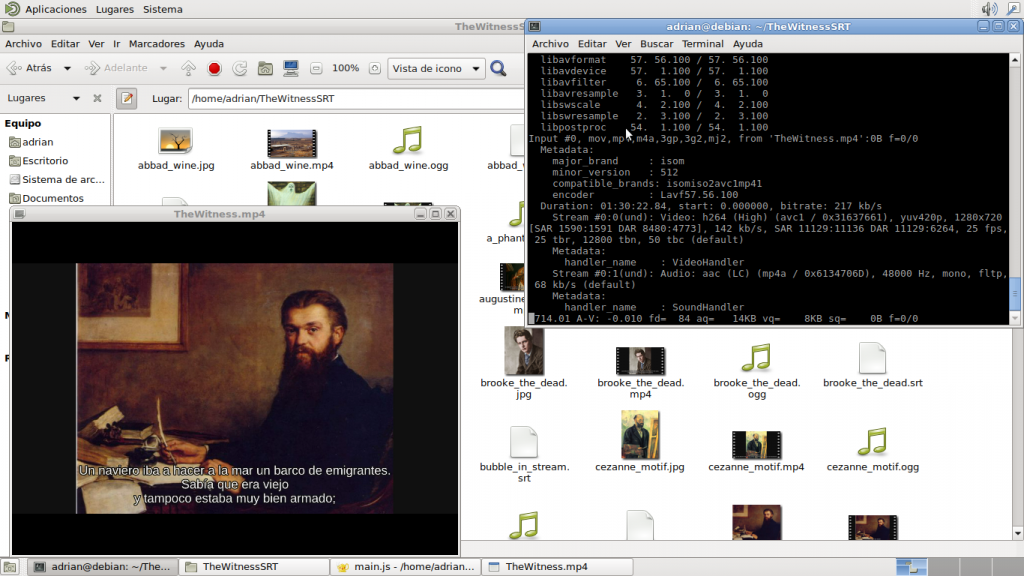
Los archivos del juego no están escondidos, se encuentran en un archivo llamado data-pc.zip. Hasta ahí fácil. Una vez dentro encontramos cientos de archivos con unas extensiones peculiares que nos informan de lo que hay dentro (.texture, .lightmap,...). Sin embargo los archivos de sonido no los encontramos de manera sencilla. Necesitan una conversión. Estaba ya buscando soluciones (sospecho que tiene que ver con Audiokinetic Wwise) cuando encontré en reddit a un buen samaritano que había subido, ya decodificados, los archivos de sonido a Mega.
Al ver los archivos observé cantidad de ficheros .WAV y muy poquitos .OGG. Eso ya nos da una pista, pues las citas célebres han tenido que ser codificadas como Ogg, ya que si fuesen con WAV el fichero sería demasiado grande. Extraigo los archivos y borro todos los WAV, pues sé que ahí no están.
Pero no hemos acabado. Los Ogg no solo eran de citas célebres, también había efectos de sonido largos. Afortunadamente, los archivos de efectos de sonido solían llevar un prefijo común (amb_, spec_,...).
Tenemos los ficheros de audio de las citas en formato Ogg. Ahora hacen falta los subtítulos. Están fuera de ese fichero ZIP gigante y no es difícil encontrarlos. En concreto el archivo es_ES.subtitles. Sin embargo, una vez lo abres descubres la primera sorpresa. Es un formato del que desconocía su existencia. Os pongo un poco para ver si alguien es capaz de saber el formato:
Pero no me iba a detener. Así que empecé a diseñar un programa que permitiese traducir este archivo a un archivo SRT normal y corriente. Para ello usaría Regex a saco (me leí el libro, para algo me tendría que servir).

Para hacer el programa usé Node.js. Sí, se que para este tipo de cosas el mejor lenguaje es Perl, o un derivado como Ruby pero todavía no he aprendido lo suficiente de Ruby como para plantearmelo. JavaScript cuenta de forma estándar (tanto Node.js como navegador) con la clase RegExp, que permite ejecutar expresiones regulares y esa es la que he usado.
Finalmente conseguí hacer un script de Node.js, sin dependencias externas, que traduciese este archivo subtitles en un SRT.
Ya tenemos el audio, tenemos los subtítulos en un formato conocido. Vamos ahora a generar un vídeo. Primero necesitaremos una imagen de fondo. Pillo una cualquiera de Internet y empiezo a hacer pruebas con ffmpeg. El formato de salida va a ser MP4 codificado con H264 porque realmente es el formato que más rápido se codifica en mi ordenador.
Nada más empezar empiezo a ver que los subtítulos no están funcionando, no se fusionan con la imagen y el audio. Al parecer es un problema que involucra a fontconfig, ffmpeg y Windows. Sí, estaba usando Windows hasta ahora.
Me muevo a Debian y ahora ya funciona bien el fusionado de subtítulos.
Ahora intento unir dos vídeos con ffmpeg también. Fracaso. Lo vuelvo a intentar, FRACASO. Si os digo que la mayor parte del tiempo que me ha llevado este proyecto ha sido encontrar como concatenar varios MP4 en ffmpeg sin que me diese errores extraños quizá no os lo creeríais, pero es verídico. No me creeríais porque la wiki de ffmpeg lo explica correctamente y si buscáis por Internet os van a decir lo mismo. ¿Qué era lo que pasaba?
Probé también con mkvmerge, pero me decía que la longitud de los códecs era distinta. No entendí el error hasta que no me enteré que había sido el formato de píxeles, cada vídeo usaba uno distinto en su codificación.
El comando necesario para generar cada vídeo fue entonces:
Para concatenar los vídeos es necesario tener un archivo de texto donde se indiquen los archivos y su orden, siguiendo este formato:
Luego, su uso es bastante sencillo:
Ahora solo hacía falta convertir todos los archivos de audio en vídeo con sus subtítulos. Usando un script de bash se puede hacer esto:
Y el código de main.js es el siguiente. main.js se encarga de traducir los ficheros subtitles a SRT, de llamar a ffmpeg y de añadir el vídeo a la lista de videos.txt para la posterior concatenación.
Se trata de un programa que hice deprisa y corriendo y aunque el código es feo (o eso me parece a mi), la verdad es que me ha servido.
Como muchos sabréis, este año me pasé el videojuego The Witness. Es un juego muy interesante y que os recomiendo. El caso es que nunca llegué a escuchar todas las citas célebres del juego, y en YouTube solo encontré vídeos sueltos con subtítulos en... francés. Así que me propuse hacer un vídeo que recogiese todas las citas célebres del juego, con subtítulos en Español. Antes esta situación hay dos opciones:
- Lo que una persona normal haría sería buscar en la guía las localizaciones de las citas e ir grabándolas.
- Lo que haría un perturbado sería meterse en los archivos del juego, decodificar los archivos e implementar un complejo sistema para generar el vídeo.
Por supuesto, hice lo último.
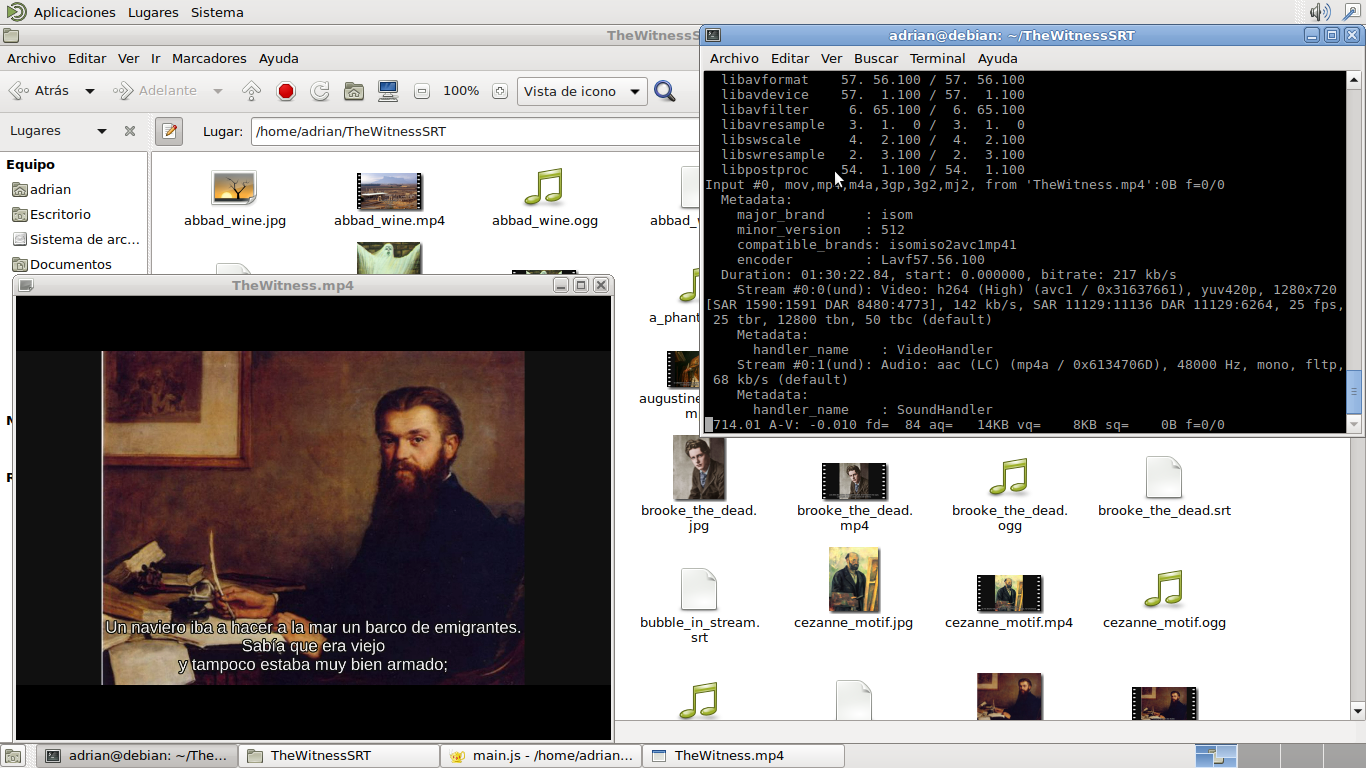
Encontrando archivos del juego
Los archivos del juego no están escondidos, se encuentran en un archivo llamado data-pc.zip. Hasta ahí fácil. Una vez dentro encontramos cientos de archivos con unas extensiones peculiares que nos informan de lo que hay dentro (.texture, .lightmap,...). Sin embargo los archivos de sonido no los encontramos de manera sencilla. Necesitan una conversión. Estaba ya buscando soluciones (sospecho que tiene que ver con Audiokinetic Wwise) cuando encontré en reddit a un buen samaritano que había subido, ya decodificados, los archivos de sonido a Mega.
Al ver los archivos observé cantidad de ficheros .WAV y muy poquitos .OGG. Eso ya nos da una pista, pues las citas célebres han tenido que ser codificadas como Ogg, ya que si fuesen con WAV el fichero sería demasiado grande. Extraigo los archivos y borro todos los WAV, pues sé que ahí no están.
Pero no hemos acabado. Los Ogg no solo eran de citas célebres, también había efectos de sonido largos. Afortunadamente, los archivos de efectos de sonido solían llevar un prefijo común (amb_, spec_,...).
Los subtítulos
Tenemos los ficheros de audio de las citas en formato Ogg. Ahora hacen falta los subtítulos. Están fuera de ese fichero ZIP gigante y no es difícil encontrarlos. En concreto el archivo es_ES.subtitles. Sin embargo, una vez lo abres descubres la primera sorpresa. Es un formato del que desconocía su existencia. Os pongo un poco para ver si alguien es capaz de saber el formato:
: tagore_voyage
= 1.000000
Creía que mi viaje había llegado al final
al estar al límite de mis fuerzas...
= 6.700000
que el camino ante mí estaba cerrado,
las provisiones agotadas
y que había llegado la hora de refugiarse en la silenciosa oscuridad.
= 17.299999
Pero encuentro que la voluntad no se me acaba,
= 21.299999
y cuando las palabras se apagan en la lengua,
surgen nuevas melodías del corazón;
= 27.200001
y cuando se pierde el antiguo camino,
una nueva tierra revela sus maravillas.
= 32.700001
= 32.709999
Rabindranath Tagore, 1910
: tagore_end
= 1.000000
En mi vida te he buscado con mis canciones.
Fueron ellas las que me guiaron de puerta en puerta,
= 8.800000
y con ellas me he sentido a mí,
buscando y tocando mi mundo.
= 14.400000
= 14.900000
Fueron mis canciones las que me enseñaron
todas las lecciones que he aprendido
= 18.900000
me mostraban caminos secretos,
condujeron mi vista hacia más de una estrella
en el horizonte de mi corazón.
= 25.500000
= 26.100000
Me guiaron todo el día
hacia los misterios del país del placer y el dolor
= 32.500000
y, finalmente,
¿a las puertas de qué palacio me han
guiado en el atardecer al final de mi viaje?
= 39.299999
: tagore_boast
= 1.000000
Presumí ante los hombres de conocerte.
= 4.300000
Ven tus imágenes en mis trabajos.
Vienen y me preguntaban "¿Quién es él?"
= 10.900000
No tengo respuesta para ellos.
Les digo "No sabría decirlo".
= 16.799999
Me culpan y se marchan con desprecio.
Y tú te sientas ahí, sonriendo.
= 23.500000
= 24.700001
Mis historias sobre ti quedan en canciones duraderas.
El secreto sale a borbotones de mi corazón.
= 31.000000
Vienen y me piden
"Cuéntame todo lo que significan".
= 34.900002
No tengo respuesta para ellos.
Les digo "Ah, ¡quién sabrá!"
= 40.500000
= 41.000000
Sonríen y se marchan con desprecio absoluto.
Y tú te sientas ahí, sonriendo.
= 48.000000
= 49.500000
- Rabindranath Tagore, 1910
Pero no me iba a detener. Así que empecé a diseñar un programa que permitiese traducir este archivo a un archivo SRT normal y corriente. Para ello usaría Regex a saco (me leí el libro, para algo me tendría que servir).

Para hacer el programa usé Node.js. Sí, se que para este tipo de cosas el mejor lenguaje es Perl, o un derivado como Ruby pero todavía no he aprendido lo suficiente de Ruby como para plantearmelo. JavaScript cuenta de forma estándar (tanto Node.js como navegador) con la clase RegExp, que permite ejecutar expresiones regulares y esa es la que he usado.
Finalmente conseguí hacer un script de Node.js, sin dependencias externas, que traduciese este archivo subtitles en un SRT.
Generando un vídeo para cada cita
Ya tenemos el audio, tenemos los subtítulos en un formato conocido. Vamos ahora a generar un vídeo. Primero necesitaremos una imagen de fondo. Pillo una cualquiera de Internet y empiezo a hacer pruebas con ffmpeg. El formato de salida va a ser MP4 codificado con H264 porque realmente es el formato que más rápido se codifica en mi ordenador.
Nada más empezar empiezo a ver que los subtítulos no están funcionando, no se fusionan con la imagen y el audio. Al parecer es un problema que involucra a fontconfig, ffmpeg y Windows. Sí, estaba usando Windows hasta ahora.
Me muevo a Debian y ahora ya funciona bien el fusionado de subtítulos.
Ahora intento unir dos vídeos con ffmpeg también. Fracaso. Lo vuelvo a intentar, FRACASO. Si os digo que la mayor parte del tiempo que me ha llevado este proyecto ha sido encontrar como concatenar varios MP4 en ffmpeg sin que me diese errores extraños quizá no os lo creeríais, pero es verídico. No me creeríais porque la wiki de ffmpeg lo explica correctamente y si buscáis por Internet os van a decir lo mismo. ¿Qué era lo que pasaba?
- Las dimensiones de los vídeos no cuadraban
- Esto fue obvio y fue lo primero que pensé. ffmpeg tiene un filtro de escalado, pero por alguna razón no funcionaba. La razón era que estaba usando dos veces la opción "-vf" (filtro de vídeo), una con los subtítulos y otra con el escalado. ffmpeg no admite nos veces la opción, si quieres aplicar dos filtros de vídeo tienes que usar una coma entre ellos.
- Formato de píxeles
- Este era el verdadero problema. Normalmente no suele pasar, pero como las imágenes de los dos vídeos venían de fuentes distintas, ffmpeg usó un formato de píxeles distinto en cada una. Forzando a ffmpeg a usar siempre "yuv420p" funcionó y la concatenación se pudo realizar.
Probé también con mkvmerge, pero me decía que la longitud de los códecs era distinta. No entendí el error hasta que no me enteré que había sido el formato de píxeles, cada vídeo usaba uno distinto en su codificación.
El comando necesario para generar cada vídeo fue entonces:
ffmpeg -loop 1 -i imagen.jpg -i audio.ogg -c:v libx264 -tune stillimage -pix_fmt yuv420p -s 1280x720 -vf scale=1280:720:force_original_aspect_ratio=decrease,pad=1280:720:(ow-iw)/2:(oh-ih)/2,subtitles=subtitulos.srt video.mp4
Concatenar los vídeos
Para concatenar los vídeos es necesario tener un archivo de texto donde se indiquen los archivos y su orden, siguiendo este formato:
# Archivo de concatenacion ffmpeg
file 'video1.mp4'
file 'video2.mp4'
file 'video3.mp4'
Luego, su uso es bastante sencillo:
ffmpeg -f concat -i videos.txt -c:v copy video.mp4
El script final
Ahora solo hacía falta convertir todos los archivos de audio en vídeo con sus subtítulos. Usando un script de bash se puede hacer esto:
for f in *.ogg; do
node main.js "${f%.*}"
done
Y el código de main.js es el siguiente. main.js se encarga de traducir los ficheros subtitles a SRT, de llamar a ffmpeg y de añadir el vídeo a la lista de videos.txt para la posterior concatenación.
var fs = require("fs");
var spawn = require("child_process").spawn;
var ZONE = process.argv[2];
var IMG = process.argv[2]+".jpg";
function timeFormat(SEC,MILISEC){
var date = new Date(SEC * 1000);
var regex = new RegExp("([0-9]+:[0-9]+:[0-9]+)");
var str = regex.exec(date.toUTCString())[1] + "," + MILISEC.substring(0,3);
return str;
}
var witness = fs.readFileSync("es_ES.subtitles","utf-8");
var srt = fs.createWriteStream(ZONE+".srt");
var regex = ": "+ZONE+"\n\n= ([0-9]+).([0-9]+)\n";
var LINE = 1;
while(!(new RegExp(regex + "\n: ","g").test(witness))){
var start = new RegExp(regex,"g");
var match = start.exec(witness);
var START_TIME_SEC = parseInt(match[match.length - 2]);
var START_TIME_MILISEC = match[match.length - 1];
var TEXT = "";
do{
var text = new RegExp(regex + "(.+)\n","g");
var exec = text.exec(witness);
if(exec!=null){
TEXT = TEXT + "\n" + exec[exec.length - 1];
regex = regex + "(.+)\n";
}
}while(exec != null);
regex = regex + "\n= ([0-9]+).([0-9]+)\n";
var time = new RegExp(regex,"g");
var end_time = time.exec(witness);
if(end_time != null){
var END_TIME_SEC = parseInt(end_time[end_time.length - 2]);
var END_TIME_MILISEC = end_time[end_time.length - 1];
srt.write(LINE + "\n");
srt.write(timeFormat(START_TIME_SEC,START_TIME_MILISEC)+" --> "+timeFormat(END_TIME_SEC,END_TIME_MILISEC));
srt.write(TEXT);
srt.write("\n\n");
}else{
srt.write(LINE + "\n");
srt.write(timeFormat(START_TIME_SEC,START_TIME_MILISEC)+" --> "+timeFormat(5*60,"000000"));
srt.write(TEXT);
srt.write("\n\n");
break;
}
LINE++;
}
srt.end();
var ffmpeg = spawn("ffmpeg",["-loop","1","-i",IMG,"-i",ZONE+".ogg","-c:v","libx264","-tune","stillimage","-pix_fmt","yuv420p","-s","1280x720","-shortest","-vf","scale=1280:720:force_original_aspect_ratio=decrease,pad=1280:720:(ow-iw)/2:(oh-ih)/2,subtitles="+ZONE+".srt",ZONE+".mp4"]);
ffmpeg.stderr.on('data', (data) => {
console.log(`stderr: ${data}`);
});
fs.appendFileSync("video.txt","file '"+ZONE+".mp4'\n");
Se trata de un programa que hice deprisa y corriendo y aunque el código es feo (o eso me parece a mi), la verdad es que me ha servido.