Estadística en Python: Pandas, NumPy, SciPy (Parte I)
- Adrián Arroyo Calle
Recientemente SciPy anunció que lanzaba la versión 1.0 tras 16 años en desarrollo. Con motivo de este acontecimiento voy a realizar una serie de tutoriales sobre estadística en Python. Quiero hacer especial énfasis en la resolución de problemas estadísticos, con problemas reales que vamos a ir resolviendo. Usaremos Python 3, NumPy, Pandas, SciPy y Matplotlib entre otras.
Python se ha convertido en uno de los lenguajes más usados en la comunidad de data science. Se trata de un lenguaje cómodo para los matemáticos, sobre el que es fácil iterar y cuenta con unas librerías muy maduras.
Yo voy a usar Python 3. Tanto si estamos en Windows, macOS o Linux podemos instalar NumPy, SciPy, Pandas y Matplotlib con este simple comando
NumPy sirve para realizar cálculos numéricos con matrices de forma sencilla y eficiente y tanto SciPy como Pandas la usan de forma interna. NumPy es la base del stack científico de Python.
SciPy es una colección de módulos dedicados a diversas áreas científicas. Nosotros usaremos principalmente el módulo stats.
Pandas es una librería que permite manipular grandes conjuntos de datos en tablas con facilidad. Además permite importar y exportar esos datos.
Matplotlib permite realizar gráficos y diagramas con facilidad, mostrarlos en pantalla o guardarlos a archivos.
Vamos a comenzar con la parte de la estadística que trata de darnos un resumen del conjunto de datos.
Para ello vamos a definir el concepto de variable estadística como la magnitud o cualidad de los individuos que queremos medir (estatura, calificaciones en el examen, dinero en la cuenta,...). Las variables pueden ser cualitativas o cuantitativas y dentro de las cuantitativas pueden ser continuas y discretas.
En este post voy a usar este fichero para los ejemplos (guardalo como notas.csv).
Para cargar datos y manipular los datos usamos Pandas. Pandas permite cargar datos de distintos formatos: CSV, JSON, HTML, HDF5, SQL, msgpack, Excel, ...
Para estos ejemplos usaremos CSV, valores separados por comas:
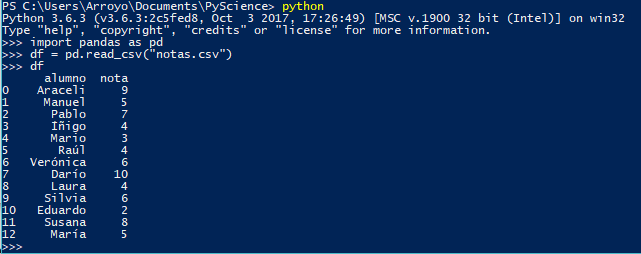
df es un objeto de tipo DataFrame. Es la base de Pandas y como veremos, se trata de un tipo de dato muy flexible y muy fácil de usar. Si ahora hacemos print a df obtenemos algo así:
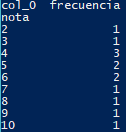
Si tenemos una variable discreta o cualitativa una cosa habitual que se suele hacer es construir la tabla de frecuencias. Con ella sabemos cuantas veces se repite el valor de la variable. Para crear tablas de frecuencia usamos crosstab. En index indicamos la variable que queremos contar y en columns especificaos el nombre de la columna de salida. crosstab devuelve otro DataFrame independiente.
Ejemplo: ¿Cuántos alumnos han sacado un 5 en el examen?
Ejemplo: ¿Cuántos alumnos han aprobado (sacar 5 o más)?
En estos ejemplo usamos loc para devolver las filas que cumplan la condición descrita entre corchetes. En el último ejemplo como el resultado son varias filas, nos quedamos con la parte de las frecuencias y sumamos todo, para así obtener el resultado final.
Una forma sencilla de visualizar datos que ya han sido pasados por la tabla de frecuencias es el diagrama de sectores. Usando Matplotlib podemos generar gráficos en los que podemos personalizar todo, pero cuyo uso básico es extremadamente simple.
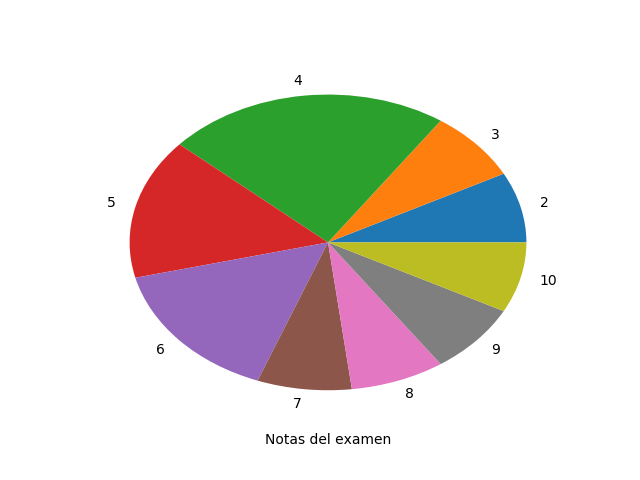 Gráfica generada por Matplotlib
Gráfica generada por Matplotlib
Ejemplo: Haz un diagrama de sectores donde se vea claramente el porcentaje de aprobados frente al de suspensos
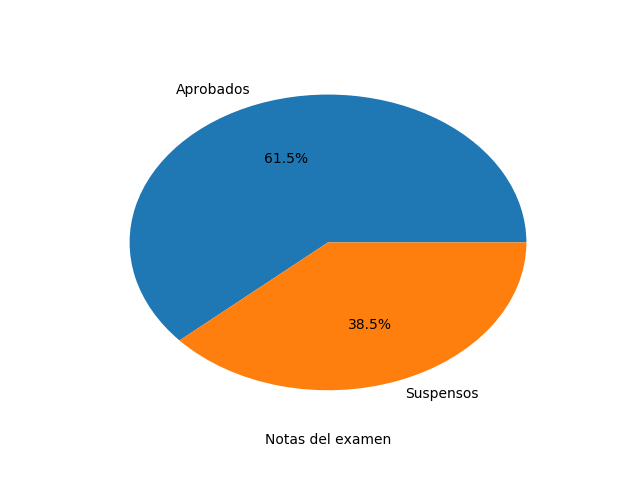 Destacar que aquí hemos usado np.array para crear un array de NumPy en vez de una lista nativa de Python.
Destacar que aquí hemos usado np.array para crear un array de NumPy en vez de una lista nativa de Python.
De forma similar es posible generar un diagrama de barras:
Ejemplo: Genere un diagrama de barras de las notas obtenidas por los alumnos en el examen
¿Por qué Python para estadística?
Python se ha convertido en uno de los lenguajes más usados en la comunidad de data science. Se trata de un lenguaje cómodo para los matemáticos, sobre el que es fácil iterar y cuenta con unas librerías muy maduras.
Instalando el stack estadístico en Python
Yo voy a usar Python 3. Tanto si estamos en Windows, macOS o Linux podemos instalar NumPy, SciPy, Pandas y Matplotlib con este simple comando
pip3 install numpy scipy matplotlib pandas --user
¿Para qué sirve cada cosa?
NumPy sirve para realizar cálculos numéricos con matrices de forma sencilla y eficiente y tanto SciPy como Pandas la usan de forma interna. NumPy es la base del stack científico de Python.
SciPy es una colección de módulos dedicados a diversas áreas científicas. Nosotros usaremos principalmente el módulo stats.
Pandas es una librería que permite manipular grandes conjuntos de datos en tablas con facilidad. Además permite importar y exportar esos datos.
Matplotlib permite realizar gráficos y diagramas con facilidad, mostrarlos en pantalla o guardarlos a archivos.
Estadística descriptiva
Vamos a comenzar con la parte de la estadística que trata de darnos un resumen del conjunto de datos.
Para ello vamos a definir el concepto de variable estadística como la magnitud o cualidad de los individuos que queremos medir (estatura, calificaciones en el examen, dinero en la cuenta,...). Las variables pueden ser cualitativas o cuantitativas y dentro de las cuantitativas pueden ser continuas y discretas.
Fichero de ejemplo
En este post voy a usar este fichero para los ejemplos (guardalo como notas.csv).
alumno,nota
Araceli,9
Manuel,5
Pablo,7
Íñigo,4
Mario,3
Raúl,4
Verónica,6
Darío,10
Laura,4
Silvia,6
Eduardo,2
Susana,8
María,5
Cargando datos
Para cargar datos y manipular los datos usamos Pandas. Pandas permite cargar datos de distintos formatos: CSV, JSON, HTML, HDF5, SQL, msgpack, Excel, ...
Para estos ejemplos usaremos CSV, valores separados por comas:
import pandas as pd
df = pd.read_csv("notas.csv")
df es un objeto de tipo DataFrame. Es la base de Pandas y como veremos, se trata de un tipo de dato muy flexible y muy fácil de usar. Si ahora hacemos print a df obtenemos algo así:
Tabla de frecuencias
Si tenemos una variable discreta o cualitativa una cosa habitual que se suele hacer es construir la tabla de frecuencias. Con ella sabemos cuantas veces se repite el valor de la variable. Para crear tablas de frecuencia usamos crosstab. En index indicamos la variable que queremos contar y en columns especificaos el nombre de la columna de salida. crosstab devuelve otro DataFrame independiente.
Ejemplo: ¿Cuántos alumnos han sacado un 5 en el examen?
import pandas as pd
# Leer datos
df = pd.read_csv("notas.csv")
# Generar tabla de frecuencias
tab = pd.crosstab(index=df["nota"],columns="frecuencia")
print(tab)
# Buscar el elemento 5 (el elemento que cumple la condición de que su índice es igual a 5)
fila = tab.loc[tab.index == 5]
# Obtenemos el valor "frecuencia" de la fila
x = fila["frecuencia"]
x = int(x)
print("%d alumnos han sacado un 5" % x)
Ejemplo: ¿Cuántos alumnos han aprobado (sacar 5 o más)?
import pandas as pd
df = pd.read_csv("notas.csv")
tab = pd.crosstab(index=df["nota"],columns="frecuencia")
print(tab)
x = tab.loc[tab.index >= 5]["frecuencia"].sum()
x = int(x)
print("%d alumnos han aprobado el examen" % x)
En estos ejemplo usamos loc para devolver las filas que cumplan la condición descrita entre corchetes. En el último ejemplo como el resultado son varias filas, nos quedamos con la parte de las frecuencias y sumamos todo, para así obtener el resultado final.
Diagrama de sectores
Una forma sencilla de visualizar datos que ya han sido pasados por la tabla de frecuencias es el diagrama de sectores. Usando Matplotlib podemos generar gráficos en los que podemos personalizar todo, pero cuyo uso básico es extremadamente simple.
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("notas.csv")
tab = pd.crosstab(index=df["nota"],columns="frecuencia")
plt.pie(tab,labels=tab.index)
plt.xlabel("Notas del examen")
plt.savefig("notas.png")
Gráfica generada por MatplotlibEjemplo: Haz un diagrama de sectores donde se vea claramente el porcentaje de aprobados frente al de suspensos
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("notas.csv")
tab = pd.crosstab(index=df["nota"],columns="frecuencia")
aprobados = tab.loc[tab.index >= 5]["frecuencia"].sum()
suspensos = tab.loc[tab.index < 5]["frecuencia"].sum()
data = np.array([aprobados,suspensos])
plt.pie(data,labels=["Aprobados","Suspensos"],autopct="%1.1f%%")
plt.xlabel("Notas del examen")
plt.savefig("notas.png")
Destacar que aquí hemos usado np.array para crear un array de NumPy en vez de una lista nativa de Python.Diagrama de barras
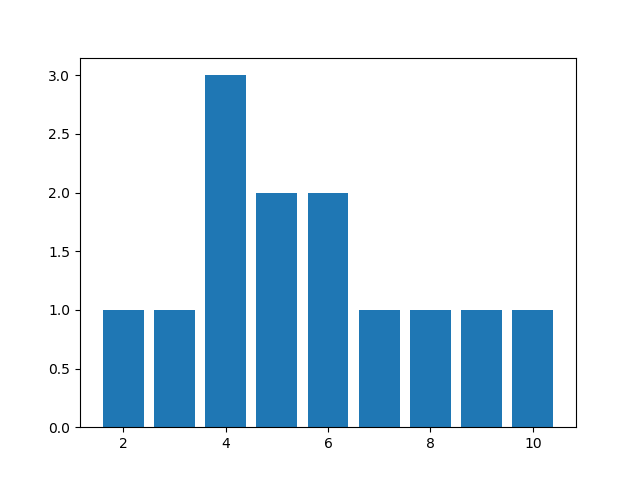
De forma similar es posible generar un diagrama de barras:
Ejemplo: Genere un diagrama de barras de las notas obtenidas por los alumnos en el examen
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("notas.csv")
tab = pd.crosstab(index=df["nota"],columns="frecuencia")
plt.bar(tab.index,tab["frecuencia"])
plt.xlabel("Notas del examen")
plt.savefig("notas.png")
Comentarios