Web Semántica desde cero: SPARQL
Hasta ahora hemos visto de forma bastante teórica el funcionamiento de RDF y de RDF Schema. Hemos dicho que RDF es un modelo de datos, interoperable y semántico. No obstante, hasta ahora no hemos accedido a la información allí expuesta. Por eso en este artículo veremos SPARQL, el lenguaje de consultas de RDF; del mismo modo que el modelo relacional tiene SQL o los documentos XML tienen XQuery.
SPARQL es un lenguaje de consultas frente a una base de datos RDF. Esta base de datos puede ser local o ser un servidor. Los servidores más conocidos son Virtuoso, Apache Jena, MarkLogic y Amazon Neptune. La sintaxis de SPARQL está inspirada en Turtle y en SQL. En un origen, SPARQL solo era un lenguaje de consulta, es decir, no podía añadir, editar o borrar información. Existe una extensión, relativamente aceptado llamado SPARQL Update que añade capacidades de edición a las consultas.
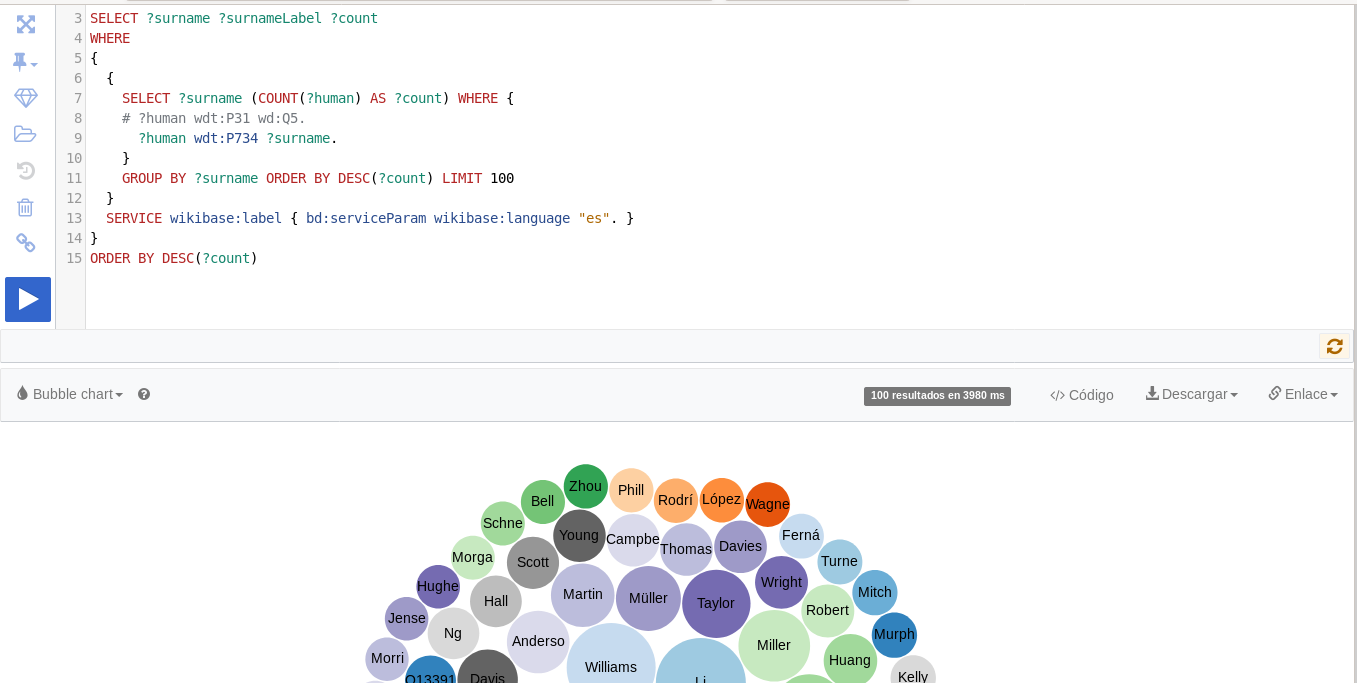
Los apellidos más comunes en la Wikipedia, un ejemplo de consulta SPARQL
SELECT
La sentencia más importante es SELECT. La salida de SPARQL siempre es en formato tabla, pudiendo dar para una misma consulta varias filas de resultados. Cada columna es una propiedad de las que pedimos en SELECT. Para describir qué valores de salida deben aparecer usamos variables. Las variables en SPARQL empiezan por el símbolo de interrogación. Estas variables las usaremos más adelante para filtrar.
FROM
La sentencia FROM en SPARQL es opcional. Indica el o los grafos sobre los que se debe buscar. Por defecto existe un grafo activo, si no lo indicamos, se usará este.
WHERE
La sentencia que nos permite filtrar las tripletas RDF. Su sintaxis es muy simple, simplemente escribimos tripletas con variables entre llaves. El motor SPARQL realizará unificación buscando las variables para las que todas las tripletas existen en la base de datos. Cada tripleta se separa por un punto. Podemos usar namespaces al igual que en otras partes de la web semántica
Con esto podemos escribir ya una consulta sencilla.
PREFIX wd: <http://www.wikidata.org/entity/>
PREFIX wdt: <http://www.wikidata.org/prop/direct/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
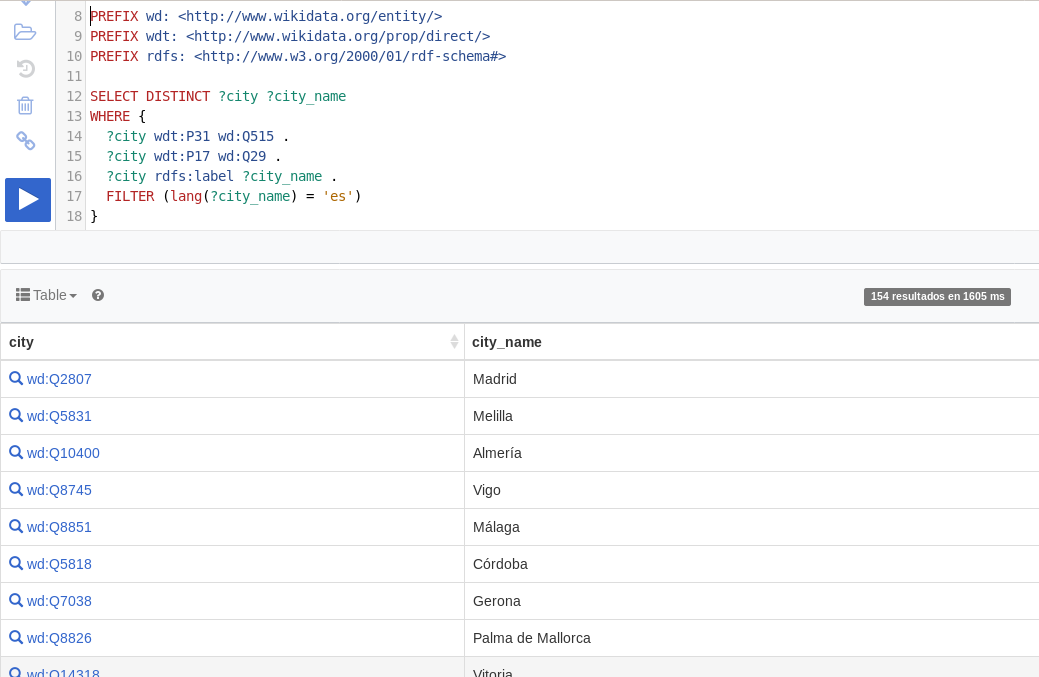
SELECT ?city ?city_name
WHERE {
?city wdt:P31 wd:Q515 .
?city wdt:P17 wd:Q29 .
?city rdfs:label ?city_name .
}
Esta consulta, que podéis ejecutar en Wikidata vosotros mismos, nos devuelve una tabla de recursos y nombres de ciudades de España. Las tripletas, un pelín crípticas debido a la nomenclatura de Wikidata, son las siguientes:
- (CITY,esInstanciaDe,wikidata:Ciudad)
- (CITY,pais,wikidata:España)
- (CITY,rdfs:label,CITY_NAME)
Al ejecutar esta sentencia, el motor SPARQL busca valores para CITY y CITY_NAME para los que las tres tripletas estén definidas.
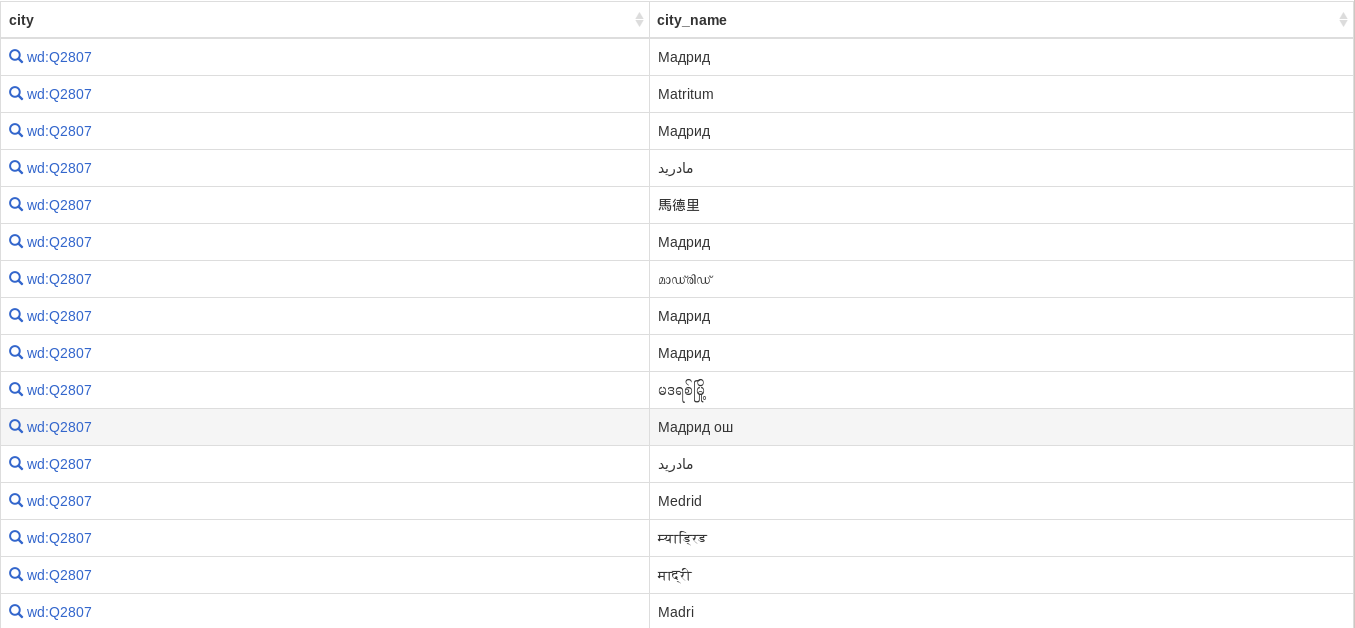
Aquí vemos el resultado de la ejecución. Como vemos, todas las salidad de la foto corresponden a Madrid, el mismo recurso pero en diferentes idiomas. Eso es porque rdfs:label soporta diferentes idiomas para el valor. Afortunadamente podemos filtrar por lenguaje gracias a una carecterística de RDF que permite especificar el lenguaje de las tripletas (xml:lang).
FILTER
La sentencia que debemos usar es FILTER, para filtrar los resultados en base a otros:
PREFIX wd: <http://www.wikidata.org/entity/>
PREFIX wdt: <http://www.wikidata.org/prop/direct/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT ?city ?city_name
WHERE {
?city wdt:P31 wd:Q515 .
?city wdt:P17 wd:Q29 .
?city rdfs:label ?city_name .
FILTER (lang(?city_name) = 'es')
}
Los resultados ahora son únicos ya que nos muestra solo los nombres en Español. FILTER es muy potente, también admite expresiones booleanas (como ?edad > 30) y regex para realizar una comprobación con expresiones regulares de la cadena de texto.
DISTINCT
Sin embargo, puede haber valores repetidos. En ocasiones simplemente queremos los elementos diferentes, no nos importa si se repiten o no. Podemos usar DISTINCT.
COUNT, SUM, MAX, MIN, ...
Al igual que en SQL, en SPARQL podemos usar agregadores en las consultas. Esto requiere SPARQL 1.1:
PREFIX wd: <http://www.wikidata.org/entity/>
PREFIX wdt: <http://www.wikidata.org/prop/direct/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT (COUNT(?city_name) AS ?n_city)
WHERE {
?city wdt:P31 wd:Q515 .
?city wdt:P17 wd:Q29 .
?city rdfs:label ?city_name .
FILTER (lang(?city_name) = 'es')
}
OPTIONAL
En SPARQL podemos definir tripletas en un WHERE que queremos que se cumplan, pero que no queremos que rechace los datos si no lo hace. Esto es normalmente usado para obtener datos que pueden existir o no. Se usa un bloque OPTIONAL dentro del WHERE.
PREFIX wd: <http://www.wikidata.org/entity/>
PREFIX wdt: <http://www.wikidata.org/prop/direct/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT ?city_name ?brother_name
WHERE {
?city wdt:P31 wd:Q515 .
?city wdt:P17 wd:Q29 .
?city rdfs:label ?city_name .
OPTIONAL {
?city wdt:P190 ?brother .
?brother rdfs:label ?brother_name .
FILTER ( lang(?brother_name) = 'es')
}
FILTER (lang(?city_name) = 'es')
}
En este caso obtenemos también las ciudades hermanas de una ciudad. Sin embargo, es algo que no todas las ciudades tienen por qué tener.
UNION
Al igual que en SQL, podemos disponer de varias condiciones diferentes, las cuales ambas son válidas. En SPARQL se expresa con la palabra UNION y dos bloques de llaves. Cada bloque es independiente del otro. Podemos decir que se ejecutan dos consultas y se juntan los resultados. Esto puede ser muy útil si tenemos datos con ontologías parecidas pero no iguales y queremos obtener datos de ambas de ellas a la vez.
Property Paths
Se trata de una característica que nos ahorra trabajo. Permiten describir caminos sobre el grafo, de longitud variable, de forma mucho más cómoda y breve. Sin entrar mucho en detalle, podemos usar la barra (/) para concatenar propiedades. Si tenemos una estructura tal que X p1 Y y Y p2 Z y solo nos interesan X y Z, podemos escribir X p1/p2 Z.
PREFIX wd: <http://www.wikidata.org/entity/>
PREFIX wdt: <http://www.wikidata.org/prop/direct/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT ?city_name ?brother_name
WHERE {
?city wdt:P31 wd:Q515 .
?city wdt:P17 wd:Q29 .
?city rdfs:label ?city_name .
OPTIONAL {
?city wdt:P190/rdfs:label ?brother_name .
FILTER (lang(?brother_name) = 'es') .
}
FILTER (lang(?city_name) = 'es')
}
ORDER BY
Al igual que en SQL, se puede ordenar la tabla saliente por un campo de los presentes en SELECT.
LIMIT
Podemos limitar el número de resultados con LIMIT al final de la consulta.
CONSTRUCT
Si con SELECT generamos tablas, con CONSTRUCT podemos construir documentos RDF como salida de la consulta. Para ello usamos el lenguaje de tripletas que usamos en la cláusula WHERE, salvo que aquí las variables serán los valores de salida.
PREFIX wd: <http://www.wikidata.org/entity/>
PREFIX wdt: <http://www.wikidata.org/prop/direct/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
CONSTRUCT {
?city rdfs:label ?city_name .
}
WHERE {
?city wdt:P31 wd:Q515 .
?city wdt:P17 wd:Q29 .
?city rdfs:label ?city_name .
OPTIONAL {
?city wdt:P190/rdfs:label ?brother_name .
FILTER (lang(?brother_name) = 'es') .
}
FILTER (lang(?city_name) = 'es')
}
ASK
Otra opción además de SELECT y CONSTRUCT es ASK. Con ASK preguntamos si un conjunto de tripletas en cuestión existen en la base de datos. Esto nos devuelve true o false.
PREFIX wd: <http://www.wikidata.org/entity/>
PREFIX wdt: <http://www.wikidata.org/prop/direct/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
ASK {
?city rdfs:label "Valladolid"@es .
?city wdt:P31 wd:Q515 .
?city wdt:P17 wd:Q29 .
}
ASK no admite WHERE, porque en realidad ya es un WHERE. Aquí hay un detalle sobre el soporte a idiomas de RDF. En la consulta la string es "Valladolid"@es y no "Valladolid". Esto es así para indicar que la string es Valladolid y está en español. No es lo mismo "Valladolid"@fr que "Valladolid"@es, para RDF son dos valores distintos.
INSERT / DELETE
Originalmente, SPARQL no permitía modificar los datos. Sin embargo, HP y otras empresas desarrollaron una extensión llamada SPARQL Update para poder hacerlo. Finalmente, fue incorporado a SPARQL 1.1. La sintaxis es Turtle. La primera orden es INSERT DATA.
PREFIX dc: <http://purl.org/dc/elements/1.1/>
INSERT DATA{
<http://libros.com/2001> dc:title "2001: una odisea en el espacio" ;
dc:creator "Arthur C. Clarke" .
}
DELETE DATA es exactamente igual. Si queremos usar variables, tenemos con una sintaxis ligeramente diferente para INSERT y DELETE.
# DATOS ANTES
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
<http://example/president25> foaf:givenName "Bill" .
<http://example/president25> foaf:familyName "McKinley" .
<http://example/president27> foaf:givenName "Bill" .
<http://example/president27> foaf:familyName "Taft" .
<http://example/president42> foaf:givenName "Bill" .
<http://example/president42> foaf:familyName "Clinton" .
# SPARQL
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
DELETE { ?person foaf:givenName 'Bill' }
INSERT{ ?person foaf:givenName 'William' }
WHERE { ?person foaf:givenName 'Bill' }
# DATOS DESPUÉS
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
<http://example/president25> foaf:givenName "William" .
<http://example/president25> foaf:familyName "McKinley" .
<http://example/president27> foaf:givenName "William" .
<http://example/president27> foaf:familyName "Taft" .
<http://example/president42> foaf:givenName "William" .
<http://example/president42> foaf:familyName "Clinton" .
Conclusión
Con esto queda explicado el 90% del uso de SPARQL, el lenguaje de consulta propuesto por W3C para manipular grafos RDF. Es un lenguaje potente y con bastante soporte. Idealmente, los clientes podrían hacer las consultas directamente al servidor, supliendo en bastantes casos de uso a otras tecnologías como REST o GraphQL.