Web Semántica desde cero: RDF
Este artículo es el primero de una serie de tutoriales que van a explorar la web semántica a día de hoy, fuera de todo hype inicial y todo el universo de los datos enlazados. Lo primero será entender el concepto fundamental y lo segundo, RDF, piedra angular de la web semántica tal y como la describe W3C.
La idea fundamental de la web semántica, es tener una web con significado, interpretable tanto por humanos como por máquinas. En la web tradicional, las webs no tienen significado, para un ordenador no deja de ser texto que no es capaz de interpretar con facilidad. La web semántica es una red, interconectada de datos con valor semántico. El valor semántico se expresa a través de ontologías. RDF es el modelo de datos propuesto por W3C para modelar esta red. No es la única propuesta, también existen microformats, microdata y otros formatos. Sin embargo, RDF es lo suficientemente maduro como para basarnos en él directamente, además de ser muy flexible.
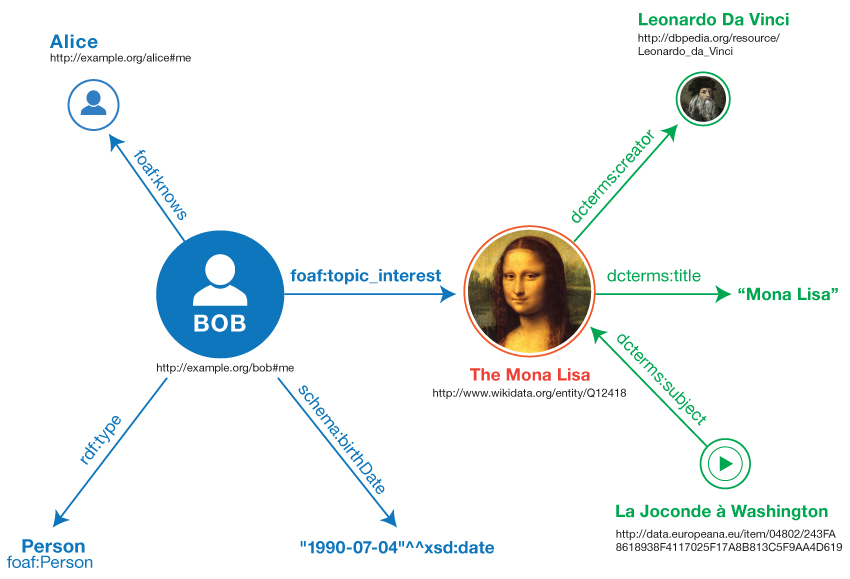
En esta imagen, cortesía de W3C, podemos ver el concepto de datos enlazados, en un grafo, donde la información se relaciona a través de propiedades comunes que todos entienden, pero la información reside en servidores diferentes. Así, aunque el perfil de usuario de Bob exista en http://example.org, sabemos que le interesa la Mona Lisa y que su autor fue Leonardo da Vinci. Simplemente siguiendo el grafo, podemos conocer esa información, aunque Bob no especificase ni guardase en su servidor en ningún momento que la Mona Lisa fue obra de Leonardo da Vinci.
¿Qué es RDF?
RDF son las iniciales de Resource Description Framework y es un modelo de datos. Define una forma en la que se representa toda la información. RDF se basa en el concepto, ya usado con anterioridad, de Objeto-Atributo-Valor (también llamado sujeto-predicado-objeto). Esto es muy sencillo de entender y a la vez, muy flexible. Básicamente, toda la información se almacena en tripletas. Una tripleta son tres valores: recurso, propiedad y valor. El recurso es el individuo sobre el que decimos algo, la propiedad es la característica sobre la que decimos algo y el valor es el contenido. Por ejemplo, podemos modelar una persona fácilmente usando tripletas.
("Alonzo Church","fecha-nacimiento","1903-06-14")
("Alonzo Church","lugar-nacimiento","Washington D.C.")
("Alonzo Church","profesion","matematico")
Los valores pueden ser a su vez recursos o pueden ser valores atómicos. De este modo se logra un grafo de relaciones. Las tripletas RDF se pueden almacenar en muchos formatos diferentes. Al principio, se hizo mucho énfasis en la sintaxis XML. Hoy día también son muy comunes las sintaxis Turtle, N3 o JSON-LD. RDF presenta un modelo de datos semitipado. Sobre esto hablaremos más adelante. En esto que hemos visto surge un problema, ¿cómo identificamos cada objeto dentro de un sistema interoperable? Si estuviésemos en Microsoft alguien habría dicho GUID, pero en la W3C la respuesta fue IRI.
¿Qué es IRI?
IRI son las iniciales de Internationalized Resource Identifier, se trata de la versión más extensa de las que las URL son un caso particular. Los IRI se definen como los identificadores en toda la web, según W3C. Una IRI puede ser http://www.google.com/ o tel:+34000111222. Ambas cadenas permiten identificar un recurso. Ese es el concepto de IRI. Si el identificador es a la vez un "puntero" ya que nos permite a su vez localizar la información, hablamos de IRL. En RDF tenemos que usar IRI, es decir, no tienen por qué permitir la localización de un recurso, pero sí lo deben identificar de forma inequícova y exclusiva.
Namespaces
En RDF hemos dicho que necesitamos usar IRI en las tripletas. Los IRI pueden ser muy largos, y con muchas partes repetidas. Para ello, se usan los espacios de nombres, que al igual que en XML, nos permiten acortar lo que escribimos. Un beneficio secundario es que podemos usar espacios de nombres ya definidos y tener así la interoperabilidad que es la base de la web semántica. Esto son las denominadas ontologías. Algunas de las más conocidas son Schema.org, Dublin Core y FOAF.
Sintaxis de RDF
Vamos a crear un ejemplo real de uso de RDF y comprobaremos las diferencias entre las distintas sintaxis. Para ello, vamos a elegir un conjunto de canciones.
Tripletas Objeto-Atributo-Valor
("https://blog.adrianistan.eu/song/Vagabundear","https://blog.adrianistan.eu/web-semantica-rdf/autor","https://blog.adrianistan.eu/group/NuestroPequeñoMundo")
("https://blog.adrianistan.eu/song/Vagabundear","https://blog.adrianistan.eu/web-semantica-rdf/album","https://blog.adrianistan.eu/web-semantica-rdf/CantarTierraMia")
("https://blog.adrianistan.eu/song/CantigaApocrifa","https://blog.adrianistan.eu/web-semantica-rdf/autor","https://blog.adrianistan.eu/group/NuestroPequeñoMundo")
("https://blog.adrianistan.eu/song/CantigaApocrifa","https://blog.adrianistan.eu/web-semantica-rdf/album","https://blog.adrianistan.eu/web-semantica-rdf/CantarTierraMia")
("https://blog.adrianistan.eu/group/NuestroPequeñoMundo","https://blog.adrianistan.eu/web-semantica-rdf/pais","https://blog.adrianistan.eu/country/España")
("https://blog.adrianistan.eu/group/NuestroPequeñoMundo","https://blog.adrianistan.eu/web-semantica-rdf/genero","https://blog.adrianistan.eu/gender/Folk")
("https://blog.adrianistan.eu/web-semantica-rdf/CantarTierraMia","https://blog.adrianistan.eu/web-semantica-rdf/fecha","1975")
Ahora veamos como estas tripletas, que ya usan IRI, se pasan a las diferentes sintaxis.
Grafo

La representación de grafo es útil para ver las interrelaciones, aunque rápidamente se puede volver bastante difícil de leer. En cualquier caso, siempre tenemos que tener en mente que el modelo RDF genera un grafo.
XML
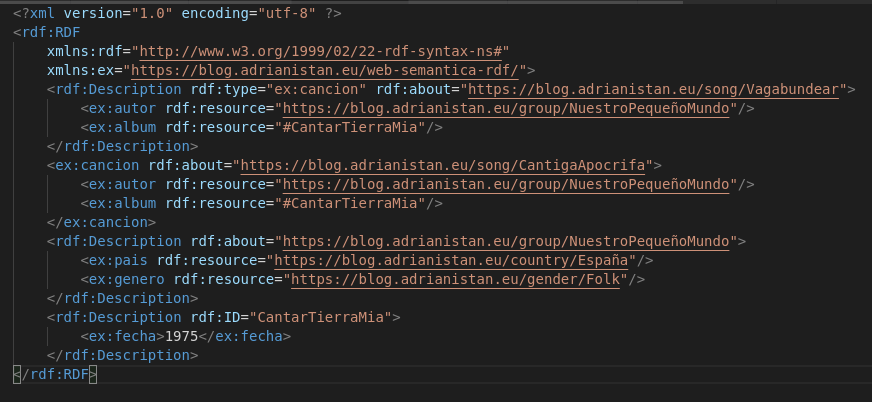
La sintaxis XML es verbosa, pero admite muchas opciones. En primer lugar definimos una etiqueta global RDF, que en este caso está dentro del namespace rdf, que usamos para referirnos al estándar RDF de 1999 (la última versión es de 2014, pero en este ejemplo no hay cambios). Cada recurso tiene un rdf:Description, pero si queremos que este objeto tenga un tipo o clase (que se indica con rdf:type) podemos simplemente usar ese nombre como etiqueta (en el ejemplo lo hacemos con ex:cancion). Esto forma parte de RDF Schema y lo veremos en el siguiente artículo. Cada objeto tiene un IRI, expresado con el atributo rdf:about. rdf:about admite IRIs absolutas y relativas. También existe, rdf:ID, que solo admite rutas relativas, pero algo mejor. Cuando el valor de una tripleta es atómico, lo podemos incluir directamente, si es otro recurso, usamos rdf:resource.
Los ficheros XML se pueden validar en el servicio de W3C.
JSON-LD
{
"@context": {
"ex": "https://blog.adrianistan.eu/web-semantica-rdf/",
"rdf": "http://www.w3.org/1999/02/22-rdf-syntax-ns#",
"rdfs": "http://www.w3.org/2000/01/rdf-schema#",
"xsd": "http://www.w3.org/2001/XMLSchema#"
},
"@graph": [
{
"@id": "https://blog.adrianistan.eu/group/NuestroPequeñoMundo",
"ex:genero": {
"@id": "https://blog.adrianistan.eu/gender/Folk"
},
"ex:pais": {
"@id": "https://blog.adrianistan.eu/country/España"
}
},
{
"@id": "https://blog.adrianistan.eu/song/Vagabundear",
"@type": "ex:cancion",
"ex:album": {
"@id": "#CantarTierraMia"
},
"ex:autor": {
"@id": "https://blog.adrianistan.eu/group/NuestroPequeñoMundo"
}
},
{
"@id": "#CantarTierraMia",
"ex:fecha": "1975"
},
{
"@id": "https://blog.adrianistan.eu/song/CantigaApocrifa",
"@type": "ex:cancion",
"ex:album": {
"@id": "#CantarTierraMia"
},
"ex:autor": {
"@id": "https://blog.adrianistan.eu/group/NuestroPequeñoMundo"
}
}
]
}
JSON-LD fue creado mucho más recientemente, debido a la pérdida de popularidad de XML. Una parte de la comunidad quería seguir usando RDF con JSON, así surgió JSON-LD (JSON for Linking Data).
Como vemos, es menos verboso. Se distinguen dos partes fundamentales: @context y @graph. En @context van los namespaces que vamos a usar. En @graph tenemos un array con los recursos. Cada recurso tiene una propiedad @id, su IRI (tanto relativos como absolutos) y sus propiedades. Las propiedades pueden ser valores directamente u objetos con propiedad @id, que hacen referencia a otro objeto. JSON-LD es muy sencillo de usar, pero tiene poco soporte.
N3
@prefix ex: <https://blog.adrianistan.eu/web-semantica-rdf/> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix xml: <http://www.w3.org/XML/1998/namespace> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
<https://blog.adrianistan.eu/song/CantigaApocrifa> a ex:cancion ;
ex:album <#CantarTierraMia> ;
ex:autor <https://blog.adrianistan.eu/group/NuestroPequeñoMundo> .
<https://blog.adrianistan.eu/song/Vagabundear> a ex:cancion ;
ex:album <#CantarTierraMia> ;
ex:autor <https://blog.adrianistan.eu/group/NuestroPequeñoMundo> .
<#CantarTierraMia> ex:fecha "1975" .
<https://blog.adrianistan.eu/group/NuestroPequeñoMundo> ex:genero <https://blog.adrianistan.eu/gender/Folk> ;
ex:pais <https://blog.adrianistan.eu/country/España> .
N3 fue un formato diseñado específicamente para RDF por Tim Berners-Lee y W3C. Es posiblemente el lenguaje menos verboso. Al principio se definen los namespaces. A continuación se definen los recursos. El IRI del recurso y a continuación separado por punto y coma, propiedad y valor, finalizando con un punto. Siempre que queramos usar un IRI usamos comillas latinas. Los valores atómicos entre comillas inglesas. N3 dispone de muchas cosas, como soporte para reglas, un subconjunto con todo lo necesario para RDF es Turtle. Este código por ejemplo, también es válido en Turtle.
N-Triples
<https://blog.adrianistan.eu/song/Vagabundear> <https://blog.adrianistan.eu/web-semantica-rdf/album> <#CantarTierraMia> .
<https://blog.adrianistan.eu/group/NuestroPequeñoMundo> <https://blog.adrianistan.eu/web-semantica-rdf/genero> <https://blog.adrianistan.eu/gender/Folk> .
<https://blog.adrianistan.eu/song/CantigaApocrifa> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <https://blog.adrianistan.eu/web-semantica-rdf/cancion> .
<https://blog.adrianistan.eu/song/CantigaApocrifa> <https://blog.adrianistan.eu/web-semantica-rdf/autor> <https://blog.adrianistan.eu/group/NuestroPeque\u00F1oMundo> .
<https://blog.adrianistan.eu/group/NuestroPequeñoMundo> <https://blog.adrianistan.eu/web-semantica-rdf/pais> <https://blog.adrianistan.eu/country/Espa\u00F1a> .
<https://blog.adrianistan.eu/song/CantigaApocrifa> <https://blog.adrianistan.eu/web-semantica-rdf/album> <#CantarTierraMia> .
<#CantarTierraMia> <https://blog.adrianistan.eu/web-semantica-rdf/fecha> "1975" .
<https://blog.adrianistan.eu/song/Vagabundear> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <https://blog.adrianistan.eu/web-semantica-rdf/cancion> .
<https://blog.adrianistan.eu/song/Vagabundear> <https://blog.adrianistan.eu/web-semantica-rdf/autor> <https://blog.adrianistan.eu/group/NuestroPeque\u00F1oMundo> .
El último formato es básicamente lo mismo que he puesto al principio, pero de forma estandarizada. N-Triples es muy simple e incluso menos verboso que XML en ocasiones, pero hay que repetir los IRI de objeto cada vez. Tampoco soporta namespaces.
RDFa, microdata, ...
Existen otros formatos para representar RDF, quizá el más popular de los que faltan sea RDFa. Este formato se acopla a HTML y permite introducir RDF en HTML. Este formato es muy usado en SEO, aunque Google también reconoce JSON-LD.
Un paso más
A continuación lo más interesante sería definir ontologías o schemas, para informar de un determinado valor semántico. Gracias a RDF Schema podremos definir relaciones de significado básicas.
Con esto acabamos el primer apartado dedicado a la web semántica. Este artículo ha sido el maś teórico pero es clave para comprender lo que haremos más adelante