Sudoku en Prolog
Prolog es el lenguaje más importante dentro del paradigma lógico. Uno de los puntos claves de Prolog es su expresividad para modelar un problema, y de la misma forma que ha sido modelado, resolverlo. Veremos como resolver el clásico Sudoku usando Prolog.

El tablero
Lo primero que tenemos que pensar es que estructura de datos va a tener el sudoku internamente. En el caso del sudoku, en la vida real sabemos que es una especie de matriz. Por simplicidad, vamos a implementarlo como una lista de Prolog. Las listas en Prolog son estructuras de datos plenamente integradas con el lenguaje. Será una lista plana de 81 (9x9) elementos. La lista contiene inicialmente los números iniciales del tablero y x donde no tenemos solución. Los números iniciales no van a cambiar nunca, así que ya sabemos que son parte de la solución definitiva.
[4,x,x,x,6,x,9,1,x,
2,x,x,x,x,7,x,5,x,
x,9,x,8,x,x,x,2,x,
x,x,1,6,x,9,x,x,2,
x,8,x,x,x,x,x,6,3,
x,7,x,x,4,x,x,x,x,
7,x,3,x,x,8,x,9,x,
x,x,x,x,3,x,4,x,5,
x,4,x,9,x,x,6,x,x].
En el sudoku hay tres subdivisiones principales: filas, columnas y cuadrados. Vamos a hacer un código en Prolog para definir cada una de estas subdivisiones. Las filas son fáciles de definir:
row(Sudoku, N, Row) :-
N0 is N-1,
N1 is N0*9+1, nth1(N1, Sudoku, X1),
N2 is N0*9+2, nth1(N2, Sudoku, X2),
N3 is N0*9+3, nth1(N3, Sudoku, X3),
N4 is N0*9+4, nth1(N4, Sudoku, X4),
N5 is N0*9+5, nth1(N5, Sudoku, X5),
N6 is N0*9+6, nth1(N6, Sudoku, X6),
N7 is N0*9+7, nth1(N7, Sudoku, X7),
N8 is N0*9+8, nth1(N8, Sudoku, X8),
N9 is N0*9+9, nth1(N9, Sudoku, X9),
Row = [X1, X2, X3, X4, X5, X6, X7, X8, X9].
Las filas se componen de 9 valores, los cuáles accedemos a ellos calculando el índice de la lista y accediendo al valor con nth1. Con nth1, las listas empiezan a contar en 1 (¡sacrilegio! ¡blasfemia!). Si usásemos nth0, las listas empezarían a contar en 0. ¡Prolog lo tiene todo!
Las columnas son iguales pero modificando el cálculo del índice lógicamente
column(Sudoku, N, Column) :-
N1 is 0*9+N, nth1(N1, Sudoku, X1),
N2 is 1*9+N, nth1(N2, Sudoku, X2),
N3 is 2*9+N, nth1(N3, Sudoku, X3),
N4 is 3*9+N, nth1(N4, Sudoku, X4),
N5 is 4*9+N, nth1(N5, Sudoku, X5),
N6 is 5*9+N, nth1(N6, Sudoku, X6),
N7 is 6*9+N, nth1(N7, Sudoku, X7),
N8 is 7*9+N, nth1(N8, Sudoku, X8),
N9 is 8*9+N, nth1(N9, Sudoku, X9),
Column = [X1, X2, X3, X4, X5, X6, X7, X8, X9].
Por último, los cuadrados tienen un pelín más de complicación de calcular los índices, pero nada que no se pueda resolver con un poco de aritmética extra.
square(Sudoku, N, Square) :-
O is (N-1) // 3,
P is (N-1) mod 3,
N1 is O*27+P*3+1 , nth1(N1, Sudoku, X1),
N2 is O*27+P*3+2 , nth1(N2, Sudoku, X2),
N3 is O*27+P*3+3 , nth1(N3, Sudoku, X3),
N4 is O*27+P*3+10 , nth1(N4, Sudoku, X4),
N5 is O*27+P*3+11 , nth1(N5, Sudoku, X5),
N6 is O*27+P*3+12 , nth1(N6, Sudoku, X6),
N7 is O*27+P*3+19 , nth1(N7, Sudoku, X7),
N8 is O*27+P*3+20 , nth1(N8, Sudoku, X8),
N9 is O*27+P*3+21 , nth1(N9, Sudoku, X9),
Square = [X1, X2, X3, X4, X5, X6, X7, X8, X9].
Condiciones del Sudoku
Una vez hemos definido estos términos, podemos pasar a comprobar como tenemos un sudoku válido. La norma dice que en las casillas de cada subdivisión deben estar todos los números, del 1 al 9, y como tienen un tamaño de 9, eso quiere decir que tampoco se pueden repetir.
Un enfoque simple podría ser comprobar que están todos los números en una subdivisión dada. Algo tal que así:
valid0(R) :-
proper_length(R, 9),
member(1, R),
member(2, R),
member(3, R),
member(4, R),
member(5, R),
member(6, R),
member(7, R),
member(8, R),
member(9, R).
Esta comprobación es correcta, pero cuando queramos resolver el sudoku va a ser extremadamente lenta. La razón es que cuando un número no existe en la subdivisión, lo añadirá para intentar hacer cumplir la regla. El inconveniente es que lo hace con todos los números que no están asignados a la vez, esto de cara a la búsqueda de la solución es muy lento. Es mucho mejor ir añadiendo un número, comprobar todo, luego volver a añadir otro.
Una validación mucho más simple y rápida es comprobar que si la subdivisión, que es una lista, es además un set, es decir, no hay elementos repetidos. Esto no nos añadirá números innecesariamente (¡de hecho no nos añadirá ninguno, lo tendremos que hacer en otro lado!).
valid(R) :-
is_set(R).
Resolviendo
Vamos a la parte final, vamos a resolver el sudoku, que gracias a las cualidades de Prolog, también nos dice si el tablero es correcto o no.
Lo primero que vamos a hacer es crear variables nuevas en cada X que encontremos en la entrada original. Para esta tarea he decidido usar DCGs, que ya he explicado anteriormente. Si quieres entender el código deberás leerlo antes, si simplemente te lo crees, aquí está:
program([H|T]) --> digit(H), program(T).
program([]) --> [].
digit(N) --> [N], { number(N) } .
digit(X) --> [x].
El código de sudoku se encarga de realizar la transformación de la lista con la DCG y de ejecutar un maplist sobre el tablero. ¿Qué función realiza maplist? Simplemente itera por todos los elementos de la lista, números y variables, ejecutando para ellos una comprobación. Esta comprobación será la que compruebe que los números están bien situados, y nos genere los números que sustituyan a las variables.
sudoku(Sudoku, SolvedSudoku) :-
phrase(program(SolvedSudoku), Sudoku),!,
maplist(check(SolvedSudoku), SolvedSudoku).
El último código que nos falta es el de check
check(SolvedSudoku, N) :-
between(1,9,N),
row(SolvedSudoku, 1, R1), valid(R1),
row(SolvedSudoku, 2, R2), valid(R2),
row(SolvedSudoku, 3, R3), valid(R3),
row(SolvedSudoku, 4, R4), valid(R4),
row(SolvedSudoku, 5, R5), valid(R5),
row(SolvedSudoku, 6, R6), valid(R6),
row(SolvedSudoku, 7, R7), valid(R7),
row(SolvedSudoku, 8, R8), valid(R8),
row(SolvedSudoku, 9, R9), valid(R9),
column(SolvedSudoku, 1, C1), valid(C1),
column(SolvedSudoku, 2, C2), valid(C2),
column(SolvedSudoku, 3, C3), valid(C3),
column(SolvedSudoku, 4, C4), valid(C4),
column(SolvedSudoku, 5, C5), valid(C5),
column(SolvedSudoku, 6, C6), valid(C6),
column(SolvedSudoku, 7, C7), valid(C7),
column(SolvedSudoku, 8, C8), valid(C8),
column(SolvedSudoku, 9, C9), valid(C9),
square(SolvedSudoku, 1, S1), valid(S1),
square(SolvedSudoku, 2, S2), valid(S2),
square(SolvedSudoku, 3, S3), valid(S3),
square(SolvedSudoku, 4, S4), valid(S4),
square(SolvedSudoku, 5, S5), valid(S5),
square(SolvedSudoku, 6, S6), valid(S6),
square(SolvedSudoku, 7, S7), valid(S7),
square(SolvedSudoku, 8, S8), valid(S8),
square(SolvedSudoku, 9, S9), valid(S9).
Aquí juntamos todo lo que hemos creado antes. N será el valor de la casilla de la lista. Si N es ya un número fijado, simplemente validará todas las condiciones, si es una variable, between elegirá un número entre 1 y 9 para que sea N y comprobará las condiciones. Si falla alguna condición, elegirá otro número entre 1 y 9. Si ningún número entre 1 y 9 puede cumplir las condiciones, Prolog irá marcha atrás en el maplist y le dará otro número al elemento anterior, y si no fuese posible, anterior y al anterior y al anterior, así hasta que pueda volver a avanzar. Esto es claro ejemplo de algoritmo de backtracking, que Prolog implementa en su ejecución. Gracias a esto, hemos podido modelar el sudoku fácilmente.
Conclusión
El código completo es el siguiente:
row(Sudoku, N, Row) :-
N0 is N-1,
N1 is N0*9+1, nth1(N1, Sudoku, X1),
N2 is N0*9+2, nth1(N2, Sudoku, X2),
N3 is N0*9+3, nth1(N3, Sudoku, X3),
N4 is N0*9+4, nth1(N4, Sudoku, X4),
N5 is N0*9+5, nth1(N5, Sudoku, X5),
N6 is N0*9+6, nth1(N6, Sudoku, X6),
N7 is N0*9+7, nth1(N7, Sudoku, X7),
N8 is N0*9+8, nth1(N8, Sudoku, X8),
N9 is N0*9+9, nth1(N9, Sudoku, X9),
Row = [X1, X2, X3, X4, X5, X6, X7, X8, X9].
column(Sudoku, N, Column) :-
N1 is 0*9+N, nth1(N1, Sudoku, X1),
N2 is 1*9+N, nth1(N2, Sudoku, X2),
N3 is 2*9+N, nth1(N3, Sudoku, X3),
N4 is 3*9+N, nth1(N4, Sudoku, X4),
N5 is 4*9+N, nth1(N5, Sudoku, X5),
N6 is 5*9+N, nth1(N6, Sudoku, X6),
N7 is 6*9+N, nth1(N7, Sudoku, X7),
N8 is 7*9+N, nth1(N8, Sudoku, X8),
N9 is 8*9+N, nth1(N9, Sudoku, X9),
Column = [X1, X2, X3, X4, X5, X6, X7, X8, X9].
square(Sudoku, N, Square) :-
O is (N-1) // 3,
P is (N-1) mod 3,
N1 is O*27+P*3+1 , nth1(N1, Sudoku, X1),
N2 is O*27+P*3+2 , nth1(N2, Sudoku, X2),
N3 is O*27+P*3+3 , nth1(N3, Sudoku, X3),
N4 is O*27+P*3+10 , nth1(N4, Sudoku, X4),
N5 is O*27+P*3+11 , nth1(N5, Sudoku, X5),
N6 is O*27+P*3+12 , nth1(N6, Sudoku, X6),
N7 is O*27+P*3+19 , nth1(N7, Sudoku, X7),
N8 is O*27+P*3+20 , nth1(N8, Sudoku, X8),
N9 is O*27+P*3+21 , nth1(N9, Sudoku, X9),
Square = [X1, X2, X3, X4, X5, X6, X7, X8, X9].
valid(R) :-
is_set(R).
program([H|T]) --> digit(H), program(T).
program([]) --> [].
digit(N) --> [N], { number(N) } .
digit(X) --> [x].
check(SolvedSudoku, N) :-
between(1,9,N),
row(SolvedSudoku, 1, R1), valid(R1),
row(SolvedSudoku, 2, R2), valid(R2),
row(SolvedSudoku, 3, R3), valid(R3),
row(SolvedSudoku, 4, R4), valid(R4),
row(SolvedSudoku, 5, R5), valid(R5),
row(SolvedSudoku, 6, R6), valid(R6),
row(SolvedSudoku, 7, R7), valid(R7),
row(SolvedSudoku, 8, R8), valid(R8),
row(SolvedSudoku, 9, R9), valid(R9),
column(SolvedSudoku, 1, C1), valid(C1),
column(SolvedSudoku, 2, C2), valid(C2),
column(SolvedSudoku, 3, C3), valid(C3),
column(SolvedSudoku, 4, C4), valid(C4),
column(SolvedSudoku, 5, C5), valid(C5),
column(SolvedSudoku, 6, C6), valid(C6),
column(SolvedSudoku, 7, C7), valid(C7),
column(SolvedSudoku, 8, C8), valid(C8),
column(SolvedSudoku, 9, C9), valid(C9),
square(SolvedSudoku, 1, S1), valid(S1),
square(SolvedSudoku, 2, S2), valid(S2),
square(SolvedSudoku, 3, S3), valid(S3),
square(SolvedSudoku, 4, S4), valid(S4),
square(SolvedSudoku, 5, S5), valid(S5),
square(SolvedSudoku, 6, S6), valid(S6),
square(SolvedSudoku, 7, S7), valid(S7),
square(SolvedSudoku, 8, S8), valid(S8),
square(SolvedSudoku, 9, S9), valid(S9).
sudoku(Sudoku, SolvedSudoku) :-
phrase(program(SolvedSudoku), Sudoku),!,
maplist(check(SolvedSudoku), SolvedSudoku).
Para usarlo, lo guardamos en un fichero sudoku.pl y ejecutamos SWI-Prolog (swipl)
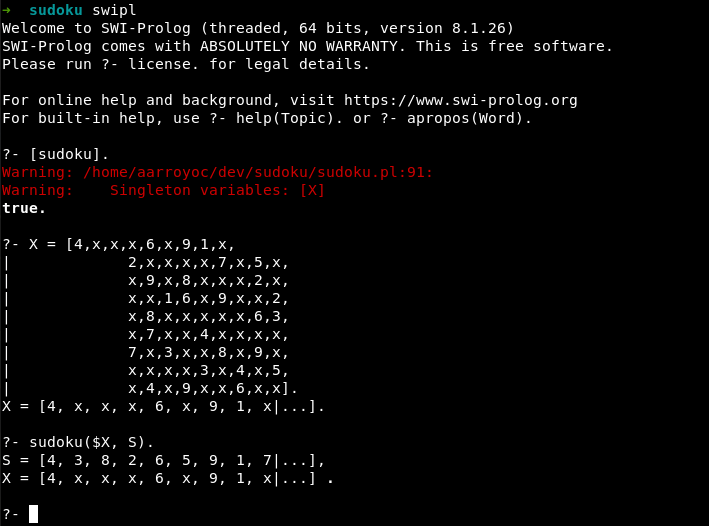
En la lista S queda la solución del Sudoku para que la inspeccionemos. Esto es un poco feo, pero con SWI-Prolog podemos hacer una API que a través de JSON pueda recibir y devolver sudokus, que luego podemos usar en otro sitio con una interfaz más trabajada.