Strand, un lenguaje extremadamente paralelo
Strand es un lenguaje de programación lógico diseñado en 1988 por Ian Foster y Stephen Taylor. Se trata de un lenguaje diseñado desde para ser extremadamente paralelo. El lenguaje no tuvo mucho éxito, su página de Wikipedia en inglés es enana y muy poca gente lo conoce. No obstante, los autores de Strand llegaron a publicar un libro, Strand: New concepts in Parallel Programming. Además, gracias al trabajo de Felix L. Winkelmann, existe una implementación open source de Strand. En este post veremos algunos conceptos fundamentales de Strand.

La sintaxis de Strand es similar a la de Prolog. De hecho, a primera vista podríamos confundir los lenguajes. Los números siguen reglas similares a Prolog, las variables empiezan por mayúscula y existen variables anónimas con _. En Strand no hay diferencia entre atom y string y las comillas simples y las dobles son equivalentes. Por último, las listas en Strand funcionan de forma similar a Prolog, no obstante las estructuras de Prolog aquí son tuplas, un conjunto de N términos de tamaño fijo entre llaves. No obstante, mediante azúcar sintáctico es posible obtener la representación que tienen las estructuras en Prolog.
house(77, bedrooms(3), Owner) % Equivale a
{house, 77, {beedrooms, 3}, Owner}
Los procesos
Hasta aquí todo es básicamente Prolog. El elemento diferencial de Strand son los procesos. La ejecución de un programa Strand consiste en la ejecución de N procesos. Los procesos pueden ejecutar tres tipos de acciones: terminar, cambiar estado y fork. Cuando un proceso acaba, esa parte de la computación finaliza. Cuando cambia de estado, el mismo proceso busca otra definición de proceso para continuar la computación. Cuando un proceso hace fork, se crea otro proceso que seguirá la computación en paralelo empezando con una definición de proceso inicial. Strand llama definición de proceso al conjunto de reglas con el mismo nombre y aridad (o sea, lo que es un predicado en Prolog).
main :-
a,
b.
a :- true.
b :- true.
Imaginemos el programa anterior. Empezamos a ejecutar el programa por con un proceso que ejecutará main. El proceso main hará dos cosas, primero hará un fork para crear un nuevo proceso y le pedirá ejecutar b. Después cambiará de estado él y ejecutará a. Es decir, a y b se ejecutarán de forma concurrente. En este caso a y b terminarán y acabarán y main acabará también.
Los procesos, como veremos, se pueden comunicar a través de las variables.
Las reglas, a priori pueden parecer similares a las de Prolog, pero hay que hacer un pequeño inciso. Strand no tiene backtracking. Pero conserva el no determinismo. ¿Cómo es esto posible? La filosofía de Prolog respecto al no determinismo podríamos resumirla en No sé que camino tomar mientras que en Strand es No me importa que camino tomar.
Ante una definición de proceso consistente en más de una regla, Strand cogerá cualquiera de ellas forma arbitraria. Pero como esta información puede ser insuficiente para asegurar que es un camino que nos interesa tomar, se añaden las guardas. Las guardas son comprobaciones extra que se comprueban antes de elegir de forma definitiva esa regla como la regla por la que a de seguir la computación. Las guardas se separan del cuerpo de la regla por el caracter | y en Strand las guardas solo pueden contener operadores predefinidos por el lenguaje. Mientras estemos en una guarda, todavía el camino a otras reglas dentro de la definición de proceso están abiertas. Una vez todos los chequeos pasan, la elección es definitiva. A esto se le llama commited choice.
max(X, Y, Z) :- X > Y | Z := X.
max(X, Y, Z) :- X =< Y | Z := Y.
Esta pequeña definición de proceso, max/3, nos permite calcular el máximo entre X e Y, dejando el resultado en Z. A diferencia de Prolog, en Strand al no haber backtracking, debemos usar guardas para saber que regla es la buena para poder continuar en ella la computación. Además, vemos un operador nuevo. Se trata de :=. En Strand esto se llama asignación. Y es que sí, Strand también elimina el concepto de unificación de Prolog. En su lugar tendremos matching y asignaciones. La asignación nos permite asignar un valor a una variable. En muchos casos es similar a la unificación pero es menos flexible. No obstante en la implementación de FLENG sí podremos usar la unificación, ya que no es estrictamente 100% Strand.
Veamos otro programa Strand.
-initialization(main).
max(X, Y, Z) :- X > Y | Z := X.
max(X, Y, Z) :- X < Y | Z := Y.
area(square, D, V) :- V is D * D.
area(circle, D, V) :- V is 3.1416 * D * D.
area(T, _, V) :- T =\= square, T =\= circle | V := 0.
largest(O1, D1, O2, D2, A) :-
area(O1, D1, A1),
area(O2, D2, A2),
max(A1, A2, A).
main :-
largest(square, 50, circle, 30, A),
writeln(A).
Este programa devuelve el área mayor entre un cuadrado de lado 50 y un círculo de radio 30. Y lo hace de forma paralela. Lo primero que quiero destacar es el pequeño en max/3. Ahora si X == Y, podría cualquier regla indistintamente, no está definido (pero en este caso es válido, nos da igual). Por esto mismo, también en la tercera regla de area tenemos que confirmar que la forma no es la de cuadrado o círculo, ya que Strand podría elegir cualquiera esa regla antes. Vemos también el uso del operador is para la aritmética.
Este programa también es concurrente. El proceso que ejecuta largest cambia de estado para ejecutar la primera llamada a area y hace fork para ejecutar la segunda. Las áreas se ejecutan en paralelo. La llamada a max también es paralela, pero hay un problema, hace referencia a variables cuyo valor tiene que calcular area. Strand es inteligente y sabe que no puede continuar, así que max espera hasta que las variables necesarias para las evaluar las guardas tengan un valor, y así poder continuar. De este modo, hemos sincronizado el programa usando variables.
Productores y consumidores en Strand
Sabemos que una variable que sin valor y del cuál necesitamos valor hace esperar el proceso. La variable puede tomar valor en otro proceso mediante la asignación. Vamos a ver ahora algunos patrones que podemos usar en Strand aprovechando estas técnicas. La más básica de todas es tener productores y consumidores. Básicamente tendremos procesos que generarán valores, a su ritmo, y procesos que irán consumiendo esos valores.
La idea fundamental para implementar estos patrones es pensar en listas de variables, en vez de variables a secas.
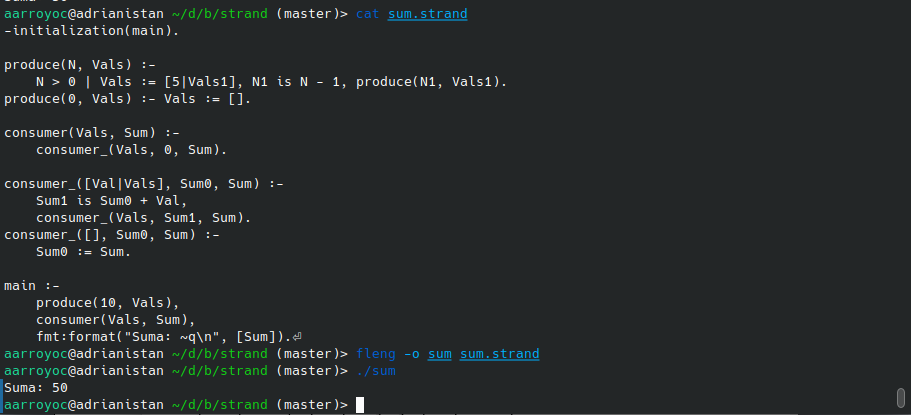
Vamos a implementar un productor que genera 10 veces el número 5.
-initialization(main).
produce(N, Vals) :-
N > 0 | Vals := [5|Vals1], N1 is N - 1, produce(N1, Vals1).
produce(0, Vals) :- Vals := [].
Hay dos reglas para produce. Una se dispara cuando N es 0 y simplemente asigna la lista de valores a la lista vacía, imposibilitando mandar más mensajes. Por otro lado, tenemos el caso de N > 0. Ahí, usamos la sintaxis de lista [Head|Tail] para asignar el primer valor de la lista Vals a 5 y obtener una variable con el resto de la lista. Esta variable, la pasaremos de forma recursiva a produce de nuevo. Al finalizar la ejecución del proceso, habrá mandado N mensajes, todos ellos con valor 5.
consumer(Vals, Sum) :-
consumer_(Vals, 0, Sum).
consumer_([Val|Vals], Sum0, Sum) :-
Sum1 is Sum0 + Val,
consumer_(Vals, Sum1, Sum).
consumer_([], Sum0, Sum) :-
Sum0 := Sum.
Por su lado el consumidor va a sumar los mensajes que le vayan llegando. En la cabeza de la regla vamos a hacer match del primer valor con el resto. Esto hará que Strand espere hasta que pueda garantizar si puede tomar la primera o la segunda regla. Haremos la suma y posteriormente volveremos a pasar la cola de la lista para volver a esperar que valor toma, si otra vez [Head|Tail] o si por el contrario, acabamos con la lista vacía y ya no hay más mensajes que procesar.
Por último, podemos juntar todo y ver como funciona correctamente.
main :-
produce(10, Vals),
consumer(Vals, Sum),
fmt:format("Suma: ~q\n", [Sum]).
¿Y si en vez de enviar un número mandásemos una estructura para poder enviar mensajes de vuelta desde el consumidor? Pues no habría ningún problema, Strand nos permite hacer este tipo de patrones también. Veamos como podríamos enviar de vuelta la suma hasta el momento.
-initialization(main).
produce(N, Vals) :-
N > 0 |
Vals := [{5, CurrentSum}|Vals1],
N1 is N - 1,
fmt:format("Current Sum: ~d\n", [CurrentSum]),
produce(N1, Vals1).
produce(0, Vals) :- Vals := [].
consumer(Vals, Sum) :-
consumer_(Vals, 0, Sum).
consumer_([{Val, CurrentSum}|Vals], Sum0, Sum) :-
Sum1 is Sum0 + Val,
CurrentSum := Sum1,
consumer_(Vals, Sum1, Sum).
consumer_([], Sum0, Sum) :-
Sum0 := Sum.
main :-
produce(10, Vals),
consumer(Vals, Sum),
fmt:format("Suma: ~q\n", [Sum]).
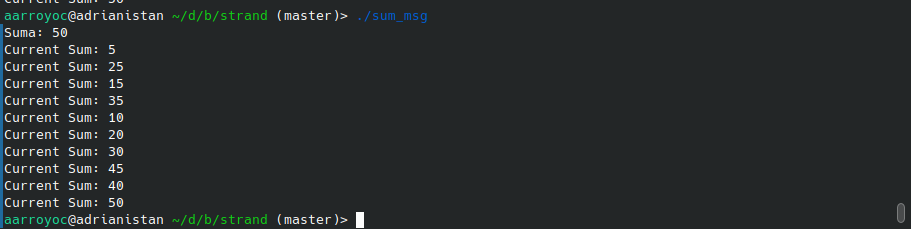
Como se puede ver el programa se ejecuta correctamente, ningún mensaje se pierde, aunque por pantalla aparecen desordenados. Es obvio ya que no hemos insertado ninguna sincronización.
Blackboard
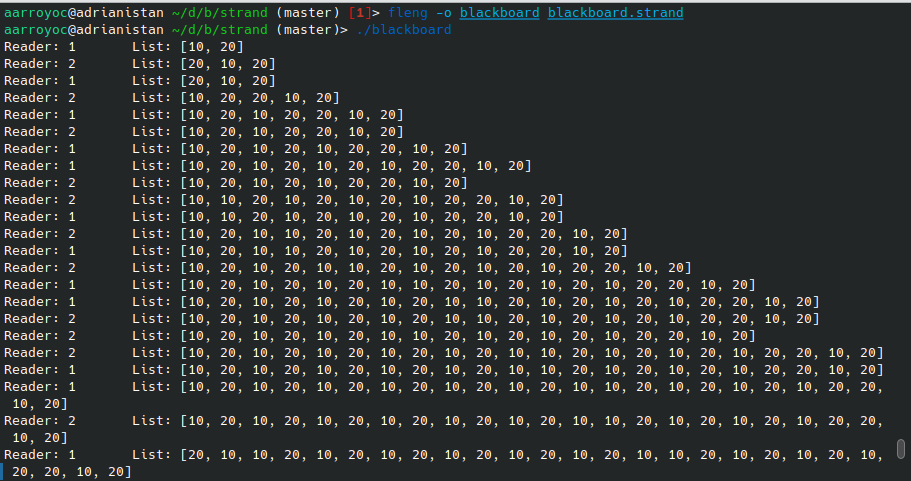
Cuando hablamos de concurrencia en otros lenguajes una de las primeras cosas es como compartir estructuras de datos entre procesos. En Strand también es posible mediante el patrón Blackboard. La idea es que la estructura de datos pertenece en sí a un proceso, que va a ir procesando mensajes de diferentes usuarios que quieren leer o escribir en la estructura de datos. Veamos un ejemplo de un programa que tendrá varios escritores y varios lectores. Los escritores añadirán números y los lectores pueden leer la lista entera.
-initialization(main).
main :-
writer(10, S1),
writer(20, S2),
reader(1, S3),
reader(2, S4),
merger([merge(S1), merge(S2), merge(S3), merge(S4)], M),
manager(M).
writer(N, S) :-
S := [write(N)|S1],
writer(N, S1).
reader(N, S) :-
S := [read(List)|S1],
fmt:format("Reader: ~d\tList: ~q\n", [N, List]),
reader(N, S1).
manager(M) :- manager(M, []).
manager([read(BB)|M], L) :- BB := L, manager(M, L).
manager([write(E)|M], L) :- manager(M, [E|L]).
manager([], _).
Este programa se ejecutaría indefinidamente y los dos escritores irían escribiendo mientras los dos lectores irían leyendo la lista e imprimiendo por pantalla. Todo de forma atómica ya que el proceso manager se encargará de ir procesando los mensajes de forma individual. Mención especial a merger/2, que usamos para combinar varios streams de variables en una sola.
Conclusión
Espero que esta breve e incompleta introducción a Strand os haya despertado la curiosidad de este lenguaje, bastante desconocido. Nos dejamos en el tintero muchas cosas, como más patrones o el uso de diferentes ordenadores para un mismo programa (Strand permitía hacer clústeres).
