Reinforcement Learning (Aprendizaje por refuerzo): ¿Qué es y cómo funciona? (parte 1)
Dentro del Machine Learning existen tres ramas: aprendizaje supervisado, no supervisado y por refuerzo. En esta serie de posts vamos a hacer una introducción a esta última rama, siguiendo el esquema habitual que se usa en libros y cursos pero simplificando ciertas cosas. Este post tendrá un caracter más teórico, pero necesario para poder desarrollar temas más avanzados.

¿Qué es el aprendizaje por refuerzo?
Se trata de una rama de Machine Learning donde un agente recibe recompensas según las acciones que realice. Las recompensas, que configuramos nosotros, tienen que ir encaminadas a que el agente, al intentar conseguir la recompensa máxima, realice lo que nosotros queremos que haga.
Un ejemplo. Pongamos el caso de un coche de carreras que tiene que hacer un circuito. Podemos darle un premio por cada tramo de circuito por el que pasa la primera vez, quitarle puntos si se sale, quitarle puntos si tarda mucho, ... Al final el agente que controla el coche aprenderá a que para obtener la recompensa máxima debe pilotar el coche sin salirse haciendo todo el circuito en el menor tiempo posible.
A parte de las recompensas, existen otras tres diferencias respecto a las otras ramas:
- El feedback sobre las acciones no es instantáneo, sino que puede retrasarse.
- El tiempo es una variable que siempre está presente.
- Las acciones tomadas por el agente varían los datos que vamos a recibir.
Términos y notación
Lo primero será ver los conceptos y notaciones que vamos a usar en este área y que se aplicarán posteriormente a cualquier algoritmo que encontremos.
La recompensa, llamada Rt, es un valor escalar, positivo o negativo, que indica como de bien o mal está el agente en el instante de tiempo t.
El aprendizaje por refuerzo funciona si aceptamos la siguiente hipótesis como válida: Todos los objetivos pueden describirse como la maximización de las recompensas acumuladas esperadas.
Estas recompensas se obtienen realizando acciones, At, es la acción elegida en el instante de tiempo t. Estas acciones se toman de forma secuencial. Las recompensas de las acciones no tienen por qué ser inmediatas. Es muy posible que sacrificar el beneficio inmediato sea mejor en pos de un beneficio mayor a largo plazo.
Para que el agente pueda tomar decisiones informadas, recibe una observación en cada instante de tiempo, Ot. Las observaciones dependen del problema que estemos resolviendo. Por ejemplo, en un juego arcade, las observaciones podrían ser una matriz de píxeles con los colores que tienen en ese momento en la pantalla.
Al conjunto de todos los paquetes Observación-Recompensa-Acción hasta el instante de tiempo t se le denomina historia, Ht. Ht = O1, R1, A1, ..., At-1, Ot, Rt. La información que el agente usa para tomar la siguiente acción se basa en la historia y se le llama estado: St = f(Ht). Aquí hay un detalle a tener en cuenta y es que partiendo del mismo estado y tomando la misma acción, el resultado (observación y recompensa siguientes) puede ser diferente.
Este estado también se le llama a veces, estado del agente. Puede ocurrir que exista otro estado, el estado ambiental o del entorno: Set. Este es el estado que tiene el entorno exterior donde vive el agente. Puede depender de variables que de cara a nuestro problema sean irrelevantes y a veces es inaccesible.
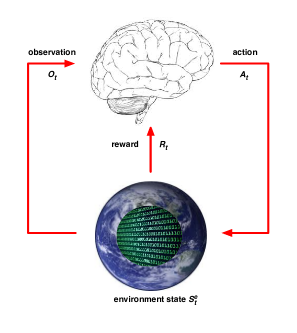
Si en nuestro problema el estado del entorno es accesible, se dice que estamos ante un entorno completamente observable y en este caso, llamaremos estado indistintamente a ambos: St = Set. En caso contrario, hablaremos de un entorno parcialmente observable y habrá distinción, aunque lo importante sigue siendo el estado del agente. La mayoría de problemas en el mundo real son parcialmente observables ya que no podemos observar de forma completa el universo.
En aprendizaje por refuerzo vamos a trabajar con estados Markov. ¿Qué es eso? Son estados que contienen en sí mismos toda la información histórica necesaria. Es decir, una vez estamos en un estado Markov, no necesitamos mirar atrás por qué otros estados hemos pasado para hacer una buena decisión ya que sería redundante, el propio estado, por su definición, ya contiene toda la información para hacer esa decisión. Esto quiere decir que no vamos a necesitar guardar la historia completa, ya que con guardar el estado actual, ya tenemos toda la información. Esto en la práctica significa que cualquier proceso temporal, que dependa de haber pasado antes por otros estados un número N de veces por ejemplo, va a ser representado con un estado diferente para cada valor de N.
El futuro es independiente del pasado dado el presente.
Los entornos completamente observables los podremos modelar como MDP (Markov Decission Process) mientras que los parcialmente observables los modelaremos como POMDP (Partially Observable Markov Decission Process). Gran parte del aprendizaje por refuerzo se basa en evaluar el MDP de un problema.
Componentes internos de un agente
En RL (reinforcement learning) un agente tiene como mínimo una de estas tres cosas (puede tener las tres):
- Política: ¿Qué debe hacer el agente?
- Función Valor: ¿Cómo de bueno es un estado?
- Modelo: ¿Cómo funciona el mundo exterior?
Política
La política de un agente es la función que indica que acción tomar dado un estado (que como recordamos es Markov y es lo único necesario para tomar una buena decisión). Normalmente se denomina 𝜋. At = 𝜋(St). Las políticas pueden ser deterministas o estocásticas.
Los algoritmos que usan solo una política se llaman Policy Based
Función Valor
La función valor nos dice que tan bueno es un estado. Se trata de una predicción de una recompensa futura. De este modo, podemos pensar que algunas acciones son mejores que otras en base al valor de esta función. Esta función puede adoptar muchas formas, pero lo más normal es estimar la función valor, dada una política según las recompensas que iría obteniendo hasta el infinito, y multiplicándolas por gamma (factor de descuento).
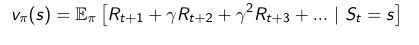

Los algoritmos que usan solo la función valor se llaman Value Based. En verdad, toda función valor lleva una política implícita pero si esta polícita ya es explícita e "independiente" de la función valor, estamos hablando de un algoritmo Actor Critic.
A parte de la función v, también existe la función q, que es similar, pero espeficicando una acción inicial.
Modelo
Por último el modelo se compondría de dos partes, una parte que predice el siguiente estado del entorno (y de la misma forma, la observación que tendríamos) y otra que predice la recompensa.
Hoy en día existen muchos algoritmos de RL model-free, es decir, sin modelo. También existen algoritmos model-based pero son menos conocidos. El problema es que muchas veces es muy costoso elaborar este tipo de modelos en la práctica.
Exploración vs Explotación
Un agente se enfrenta a un dilema constantemente: ¿es mejor explotar algo conocido que sé que funciona bien o experimento cosas nuevas para poder descurbir cosas mejores? El agente debería explorar pero tampoco debe perder demasiado las recompensas que ha obtenido. Encontrar el balance adecuado es complicado.
Un ejemplo humano de este dilema sería por ejemplo, un día de cena con tus amigos, ir a un restaurante que ya conoces y que sabes que está bien o probar un restaurante nuevo que quizá sea mejor, pero no lo sabes.
Predicción vs Control
En RL tenemos dos problemas, relacionados pero diferentes. Por un lado, la predicción: evaluar correctamente el desempeño de una política en el futuro. Por otro lado, el control: obtener la mejor política posible para maximizar la recompensa.
Algoritmos clásicos
Existen tres tipos de algoritmos clásicos para RL:
- Programación dinámica
- Monte Carlo
- Temporal Difference (TD)
En el siguiente post analizaremos con más detalle qué significa que podemos modelar un problema de RL como un MDP y qué es la ecuación de Bellman.