Regex para torpes
Las expresiones regulares, o de forma abreviada, regex, son pequeños programas que buscan y extraen ciertas cadenas de texto dentro de una cadena mayor. Las expresiones regulares no son Turing-completas, pero son ideales para trabajar con texto. Prácticamente todos los lenguajes de programación incluyen soporte a regex, con diferentes niveles de soporte. Sin embargo, habitualmente mucha gente al ver una expresión regular piensa que son indescifrables e imposibles de entender. Nada más lejos de la realidad. Con este post intento explicar lo más importante de Regex
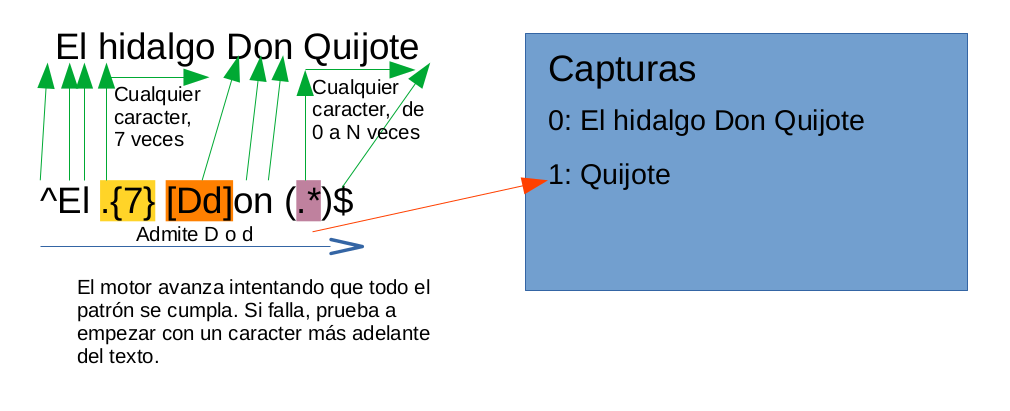 No importa si no entiendes esto ahora. Cuando acabes de leer el post espero que sí puedas.
No importa si no entiendes esto ahora. Cuando acabes de leer el post espero que sí puedas.
Para el código de ejemplo usaré Python, pero todo lo que voy a explicar es compatible con cualquier motor de regex.
Las regex son patrones de texto
Lo primero que hay que tener claro es que las expresiones regulares son patrones. El motor regex va a intentar hacer que el patrón coincida con la entrada en cualquier punto. Los patrones se definen escribiendo los caracteres que queremos que aparezcan.
import re
TEXT = """
Always remember my friend
The world will changes again
And you may have to come back
Through everywhere you have been
When your life was low
You had nowhere to go
People turned there backs on you
And everybody said that you through
I took you in
I made you strong again
Put you back together
Out of all the dreams
You left along the way
You left me shining
Now your doing well
From story's I hear tell
You own the world again
Everyone's your friend
Although I never hear from you
Still its nice to know
You used to love me so
When your life was low
"""
x = re.search(r"friend", TEXT)
if x is not None:
print("La palabra friend aparece en la letra de la canción")
En este primer ejemplo, usamos caracteres "normales" para crear la expresión regular. El motor regex va a buscar si existe en algún punto de la cadena TEXT la expresión "friend", la cuál es cierta. El procedimiento es el siguiente, el motor va buscando la primera letra, la f en el texto. Si la encuentra, comprueba que el siguiente caracter cumpla también el patrón, es decir, que sea una r. La complejidad, aparente que no real, de las regex, viene cuando introducimos condiciones más avanzadas para estos patrones. Normalmente, además de obtener si se ha podido aplicar el patrón o no, obtendremos el match, que es el texto en concreto que cumple la regla.
Tal y como hemos visto, el procedimiento de búsqueda de patrones es un AND implícito. Si queremos añadir un OR, es decir, varias alternativas, usaremos la barra vertical |.
x = re.search(r"left|right", TEXT)
En este caso, podrá encontrar el texto ya que left existe, aunque right no aparezca.
Grupos de caracteres
Lo anterior nos podría servir para muchos casos de uso, pero muchos serían tremendamente verbosos. Algunos caracteres especiales nos ayudarán.
Los corchetes [ y ] no permiten definir grupos de caracteres. Dentro de estos grupos podemos poner caracteres que podrían ir en esa posición. A la hora de buscar se seleccionará uno.
x = re.search(r"[Tt]he", TEXT)
En el ejemplo, buscará tanto la palabra the como The.
Los grupos de caracteres soportan intervalos, que nos permite definir un rango de caracteres amplio de forma reducida. Los más importantes son 0-9 (dígitos), A-Z (mayúsculas ASCII) y a-z (minúsculas ASCII).
x = re.search(r"[A-Za-z]", TEXT)
El ejemplo anterior sería un patrón para todas las letras ASCII. Hago hincapié en lo de ASCII porque si tuviesemos caracteres con tildes o eñes, no funcionaría, ya que no están dentro del intervalo.
Los grupos de caracteres pueden funcionar de forma inversa, admitiendo cualquier caracter salvo los que están dentro de él. Los grupos de caracteres complementarios empiezan con el caracter ^.
x = re.search(r"[^ ]", TEXT)
En el ejemplo anterior se admite todo menos el espacio.
Los grupos de caracteres también sirven para expresar caracteres que no podemos expresar de otra forma por tener otro significado en regex, como los puntos o los paréntesis.
Multiplicidad
Todo lo que hemos visto está muy bien pero seguimos teniendo patrones que en ocasiones pueden ser muy verbosos. Para ello entran los operadores de multiplicidad, que son cuatro y nos permiten definir las repeticiones admitidas de lo que va inmediatamente antes.
El operador * indica que lo que va antes se puede repetir de 0 a N veces
El operador + indica que lo que va antes se puede repetir de 1 a N veces
El operador ? indica que lo que va antes se puede repetir de 0 a 1 veces
El operador {M} indica que lo que va antes se puede repetir M veces
x = re.search(r"[0-9]*", "hola") # OK
x = re.search(r"[0-9]*", "123") # OK
x = re.search(r"[0-9]+", "hola") # NOPE
x = re.search(r"[0-9]+", "123") # OK
x = re.search(r"[0-9]?", "hola") # NOPE
x = re.search(r"[0-9]?", "123") # OK (pero cada número por separado)
x = re.search(r"[0-9]{4}-[0-9]{2}-[0-9]{2}", "2020-07-26") # OK
Hay que tener en cuenta que el motor regex va a buscar el match más largo que pueda encontrar, por eso usando * o +, buscará siempre el patrón que cumpla la regla que más caracteres lleve. Esto es lógico si tenemos en cuenta que el patrón más largo suele ser el buscado, pero se puede cambiar este comportamiento.
Caracteres especiales
Existen algunos caracteres especiales en regex. El punto . representa cualquier caracter (salvo saltos de línea). Por ejemplo, usando la variable TEXT de arriba:
x = re.search(r".*", TEXT)
Va a ser un patrón dentro del texto y el match va a ser: "Always remember my friend".
Otros caracteres especiales son ^ y $. Representan respectivamente, inicio de cadena y final. Son útiles cuando queremos delimitar el patrón a que necesariamente empiece donde empieza la cadena de texto y cuando queremos que toda la cadena de texto cumpla con el patrón.
x = re.search(r"^(\n|.)*$", TEXT) # OK
x = re.search(r"^[0-9]{4}-[0-9]{2}-[0-9]{2}$", "2020-07-26") # Así evitaríamos que se colase texto antes o después de la fecha.
Extraer texto (capturas)
Una de las mejores características de regex es que podemos extraer contenido dado unos patrones. Para ello, usamos paréntesis ( y ). Los grupos de captura, que es como se llaman, se numeran internamente de izquierda a derecha empezando por el número 1 (número 0 es el match completo).
x = re.search(r"^([0-9]{4})-([0-9]{2})-([0-9]{2})$", "2020-07-26")
print(x.group(0)) # 2020-07-26
print(x.group(1)) # 2020
print(x.group(2)) # 07
print(x.group(3)) # 26
Con esto ya sabemos lo básico de expresiones regulares. Existen más caracteres especiales y cosas más avanzadas como los lookaheads, pero en la gran mayoría de casos no necesitarás más. Ahora intenta leer el gráfico del comienzo del post.
Por último, una pregunta para los comentarios, ¿utilizas regex normalmente o intentas evitarlo?