Paralelismo para lelos parte 3: usando la GPU con WGPU
Por último, para finalizar esta serie de artículos sobre paralelismo, vamos a ver como usar la GPU. Ese componente que hasta hace unos años solo importaba a la gente que jugaba videojuegos pero que ahora se ha vuelto de tremenda importancia, ya que son la base de las IAs estadísticas.
¿Qué es una GPU?
Las siglas GPU significan Graphical Processing Unit. Aunque la tarea que tenemos entre manos, pintar el fractal de Mandelbrot, puede considerarse una tarea gráfica, la realidad es que las GPUs no llegaron a ser como son ahora directamente.
Prácticamente desde las primeras consolas y microordenadores ha habido chips gráficos. Estos eran necesarios, primero porque las salidas de los monitores/TVs eran analógicas y requerían de una sincronización que la CPU no podía garantizar y segundo porque era más eficiente en memoria. En consolas como la NES, podemos usar el chip gráfico (la PPU) para cargar sprites y moverlos sin tener que reescribir toda la pantalla en nuestra RAM principal.
Estos chips sin embargo no eran programables, sino más bien configurables. Es decir, soportan ciertos parámetros, le podemos mandar datos de los sprites, etc Pero no ejecutan código nuestro. Este esquema se mantuvo incluso hasta principios del siglo XXI. Por ejemplo tenemos la PlayStation 2. Una consola con una arquitectura muy compleja pero que podemos resumir en usar técnicas de SIMD, en registros de 128 bits, similares a las que vimos en la primera parte pero en chips paralelos a la CPU principal, que se encargan de dejar todo listo para pasarle al Graphics Synthesizer toda la información de vértices, localización de texturas, modos de funcionamiento,... Y él saca la imagen. Pero no podemos personalizar nada de lo que ocurre dentro con nuestro propio código. Es una caja cerrada.
Tal es así que las primeras APIs gráficas en 3D como OpenGL 1.0 funcionan de una forma parecida. Vamos mandando comandos, activando y desactivando flags, mandando vértices, etc Aunque el concepto no era nuevo y chips como el SuperFX de SNES ya dejaban programar partes del pipeline, no fue hasta que llegó Nvidia que este paradigma no se popularizó.
El paradigma que surgió entonces es tener pequeños programas que se ejecutarían en paralelo, en distintas etapas del procesamiento gráfico. Originalmente serían los vertex shaders y los fragment shaders. A estos pequeños programas se les bautizó como shaders porque con ellos se podía mejorar mucho en el tema de la iluminación. Posteriormente surgieron shaders de más tipos como los geometry shaders. Pero lo interesante es que esta arquitectura extremadamente paralela se abrió a computaciones generalistas y que ha dado lugar a lenguajes como CUDA.
¿Cómo funciona una GPU?
Hemos visto un repaso histórico de como llegamos a las GPUs programables actuales. Pero, ¿cómo funcionan exactamente y en qué se diferencia de usar SIMD en un procesador o los procesadores multicore?
La terminología aquí depende del fabricante pero voy a intentar ser lo más genérico posible. Una GPU está compuesta de uno o varios SMs. SM significa Stream Multiprocessor y tiene asignada parte de la memoria. Un SM recibe bloques de threads, también llamados workgroups. Cuando un bloque llega a un SM, el SM se encarga de organizar su ejecución. Para ello, activará los warps necesarios para ejecutar ese bloque y reservará memoria. Un warp es un conjunto de 32 threads. Cada thread del warp ejecuta el mismo código a la vez, como si fuesen instrucciones SIMD. Esto tiene implicaciones interesantes. Es decir, si un thread del warp tiene un bucle y hace más iteraciones, el resto de threads también hacen esas iteraciones, aunque luego el SM sea listo y descarte los resultados posteriores de los threads que ya habían acabado. ¿Y cuántos threads tiene una GPU? Pues una Nvidia RTX 5090 (tope de gama en 2025) tiene unos 21.760 threads, repartidos en 170 SMs, que pueden seleccionar los warps que consideren en tiempo de ejecución.
Así pues tenemos 21.760 threads en comparación con los 24 de un Intel Core i9-14900K. He aquí una gran diferencia. Aunque es verdad que estos threads tienen importantes limitaciones, como el hecho de que todos los threads ejecutan todas las instrucciones, incluso si no les hace falta.
Comparado con el modelo SIMD de las CPUs, donde también se da el caso de que todos los datos ejecutan las mismas instrucciones, tenemos la diferencia de que en una GPU vamos a poder usar lenguajes donde podemos programar como si fuese en secuencial para un elemento en particular. La paralelización la hace la GPU por nosotros.
WGPU, WebGPU en Rust
Hace ya unos años, la industria se dio cuenta de que APIs como OpenGL, y las versiones antiguas de DirectX, no se adaptaban ya bien al hardware actual de las GPUs. Esto se veía en APIs nuevas como Metal por parte de Apple o Mantle por parte de AMD. Y seguramente se viese en las APIs propietarias de consolas como PlayStation. Dentro de Khronos, la gente detrás de OpenGL, se decidió dejar de desarrollar OpenGL y empezar de cero con Vulkan. En el mundo web sin embargo ya existía una API basada en OpenGL para gráficos 3D: WebGL. Pero WebGL estaba atada a conceptos de OpenGL y al igual que Vulkan, se pensó en hacer una API web siguiendo principios más cercanos a Vulkan, aunque simplificando algunas cosas. Esta API es WebGPU y está diseñada para ser usada desde JavaScript en un navegador. Pero por debajo esos navagadores necesitan una librería. Google ha hecho dawn en C++ y Mozilla ha hecho WGPU en Rust.
Veamos que pinta tiene el código:
let instance = wgpu::Instance::new(&Default::default());
let adapter = instance.request_adapter(&Default::default()).block_on().unwrap();
let (device, queue) = adapter.request_device(&Default::default()).block_on().unwrap();
let shader = device.create_shader_module(wgpu::include_wgsl!("mandelbrot.wgsl"));
let pipeline = device.create_compute_pipeline(&wgpu::ComputePipelineDescriptor {
label: Some("Mandelbrot"),
layout: None,
module: &shader,
entry_point: None,
compilation_options: Default::default(),
cache: Default::default(),
});
En primer lugar inicializamos WGPU. Hay que tener en cuenta que podemos tener varias GPUs en un mismo ordenador. Lo más interesante es que vamos a conseguir un device, un dispositivo donde podemos crear cosas, y una queue, una cola donde mandaremos las tareas a realizar por el dispositivo.
Después, cargamos el código de nuestro shader y creamos un pipeline, donde lo básico es que el módulo es nuestro shader.
let byte_buffer_size = BUFFER_SIZE * std::mem::size_of::<u32>();
let buffer = vec![0u32; BUFFER_SIZE];
let storage_buffer = device.create_buffer(&wgpu::BufferDescriptor {
label: Some("storage"),
size: byte_buffer_size as u64,
usage: wgpu::BufferUsages::COPY_DST | wgpu::BufferUsages::COPY_SRC | wgpu::BufferUsages::STORAGE,
mapped_at_creation: false
});
let output_buffer = device.create_buffer(&wgpu::BufferDescriptor {
label: Some("output"),
size: byte_buffer_size as u64,
usage: wgpu::BufferUsages::MAP_READ | wgpu::BufferUsages::COPY_DST,
mapped_at_creation: false
});
let bind_group = device.create_bind_group(&wgpu::BindGroupDescriptor {
label: None,
layout: &pipeline.get_bind_group_layout(0),
entries: &[
wgpu::BindGroupEntry {
binding: 0,
resource: storage_buffer.as_entire_binding(),
}
],
});
Ahora viene un tema fundamental en la programación de GPUs que es tema de la memoria. Aunque existen arquitecturas de memoria unificada, no son las más comunes. Lo más típico es que la GPU tenga su propia memoria RAM y haya que copiar datos entre la memoria de la CPU y la memoria de la GPU. Para esto definimos buffers. Vamos a necesitar mínimo dos. Uno que vamos a enviar nosotros desde la CPU y que una vez en la GPU vamos a modificar. Será de tipo STORAGE. Por otro lado, vamos a necesitar otro con permisos para que pueda ser leído desde la CPU de vuelta (MAP_READ). Por otro lado en el shader vamos a hacer referencia al buffer de STORAGE. Tenemos que realizar un binding entre ese buffer y el pipeline que usa nuestro shader.
Un detalle importante es que WebGPU tiene actualmente un soporte de tipos muy limitado. Por eso en esta versión vamos a tener que usar buffers de u32 para la imagen, cuando lo ideal es que fuesen de u8. Vamos a tener que mandar bastante más datos en las copias, pero WebGPU no soporta u8 todavía.
let mut encoder = device.create_command_encoder(&Default::default());
{
let mut pass = encoder.begin_compute_pass(&Default::default());
pass.set_pipeline(&pipeline);
pass.set_bind_group(0, &bind_group, &[]);
pass.dispatch_workgroups(350, 200, 1);
}
encoder.copy_buffer_to_buffer(&storage_buffer, 0, &output_buffer, 0, output_buffer.size());
queue.write_buffer(&storage_buffer, 0, bytemuck::cast_slice(&buffer));
queue.submit([encoder.finish()]);
{
let (tx, rx) = channel();
output_buffer.map_async(wgpu::MapMode::Read, .., move |result| tx.send(result).unwrap());
device.poll(wgpu::PollType::Wait).unwrap();
rx.recv().unwrap().unwrap();
let elapsed = now.elapsed();
println!("Time for WGPU algorithm: {}ms", elapsed.as_millis());
let output_data = output_buffer.get_mapped_range(..);
let data: &[u32] = bytemuck::cast_slice(&output_data);
let data_u8 = data.into_iter().map(|x| *x as u8).collect();
save_fractal(data_u8, &Path::new("wgpu.png"));
}
Por último tenemos que mandar las instrucciones. Primero creamos un command encoder, de tipo computacional, agregamos el pipeline, los bindings y la instrucción más importante: dispatch_workgroups, que viene a ser: ejecútalo. Ahora explicaremos los números.
En el encoder también ponemos que después haga una copia del buffer de storage al buffer de output. Luego en la cola agregamos primero la instrucción de inicializar el buffer de storage y luego mandamos a la GPU con submit todas las instrucciones del encoder. Estas operaciones se ejecutan de forma asíncrona. Desde la CPU solo podemos mandar tareas a la cola. Para leer el buffer de output tenemos que usar la API asíncrona de WebGPU. Es un poco verboso, pero en esencia pide a la GPU leer el dato y el callback se ejecuta cuando ya está disponible. Luego tenemos que transformar esos u32 ineficientes en u8 para reusar nuestra función de guardar la imagen.
@group(0) @binding(0) var<storage, read_write> mandelbrot: array<u32>;
const ITERATIONS: u32 = 100;
// image size is 3500x2000
// workgroup size 10x10
// dispatch 350x200 workgroups
@compute
@workgroup_size(10, 10)
fn main(
@builtin(workgroup_id) workgroup_id: vec3<u32>,
@builtin(local_invocation_id) local_invocation_id: vec3<u32>,
) {
let x = workgroup_id.x * 10 + local_invocation_id.x;
let y = workgroup_id.y * 10 + local_invocation_id.y;
let global_id = (y * 3500 + x) * 3;
let cx = f32(x) / 1000.0 - 2.5;
let cy = f32(y) / 1000.0 - 1.0;
var zx = 0.0;
var zy = 0.0;
var zx_square = 0.0;
var zy_square = 0.0;
var i = u32(0);
while(i < ITERATIONS && zx_square + zy_square < 4.0) {
let prev_zx = zx;
zx = zx_square - zy_square + cx;
zy = 2.0 * prev_zx * zy + cy;
i = i + 1;
zx_square = zx * zx;
zy_square = zy * zy;
}
if (i == ITERATIONS) {
mandelbrot[global_id] = 255;
mandelbrot[global_id + 1] = 255;
mandelbrot[global_id + 2] = 255;
}
}
Por último tenemos el código del shader. Este shader está programado en WGSL, un lenguaje especificado por el estándar de WebGPU. Es una evolución del GLSL de las versiones modernas de OpenGL con algunos detalles que recuerdan más a Rust.
Al principio tenemos declarado el storage buffer, que es el binding 0, es read_write y es un array de u32. Luego tenemos una constante y a continuación nuestra función. La anotamos con compute para que sea un compute shader. Y le indicamos que el workgroup_size es 10x10. ¿Qué diantres es esto?
Esta anotación de workgroup_size nos permite definir el tamaño del bloque. El bloque era lo que se mandaba a un SM y el SM buscaba warps con threads para ejecutar nuestro bloque. En este caso he optado por un bloque de 100 elementos. Una peculiaridad es que la mayoría de estos lenguajes nos permiten hacer bloques de 1D, 2D y 3D. En este caso al ser una imagen he optado por bloques 2D. Entonces WGPU va a mandar a la GPU bloques de 10x10 elementos. Pero nuestra imagen es de 3500x2000 píxeles. Si cada bloque es de 10x10, entonces necesitaremos 350 bloques para cubrir la horizontal y 200 para cubrir la vertical. Esos son los números que se veían en Rust en la parte de dispatch_workflow. Esto es lo que se llama nuestra grid y es de 350x200. También puede ser unidimensional o tridimensional. O sea que la GPU va a tener que procesar 70.000 bloques, cada uno de 10x10 píxeles. ¿Podríamos haber puesto bloques más grandes? Sí, pero WebGPU para ser compatible con muchas GPUs tiene un límite de 256 threads por bloque. Si programásemos directamente en CUDA el límite sería de 1024 threads por bloque.
Dentro del shader, ¿cómo sabemos qué píxeles del fractal tenemos que procesar? Para ello tenemos dos argumentos en la función que la GPU rellenará pos nosotros: workgroup_id y local_invocation_id. workgroup_id nos dice en qué bloque estamos dentro de la grid, en nuestro caso como es 2D, el identificador es una coordenada XY. Por otro lado, local_invocation_id nos dice nuestra coordenada dentro del bloque. De nuevo como es un bloque 2D, nos da una coordenada XY. Multiplicando el workgroup_id por el tamaño del bloque y sumando el ID local, obtenemos nuestra posición absoluta dentro del grid de computación. El resto del shader es el algoritmo de otras veces.
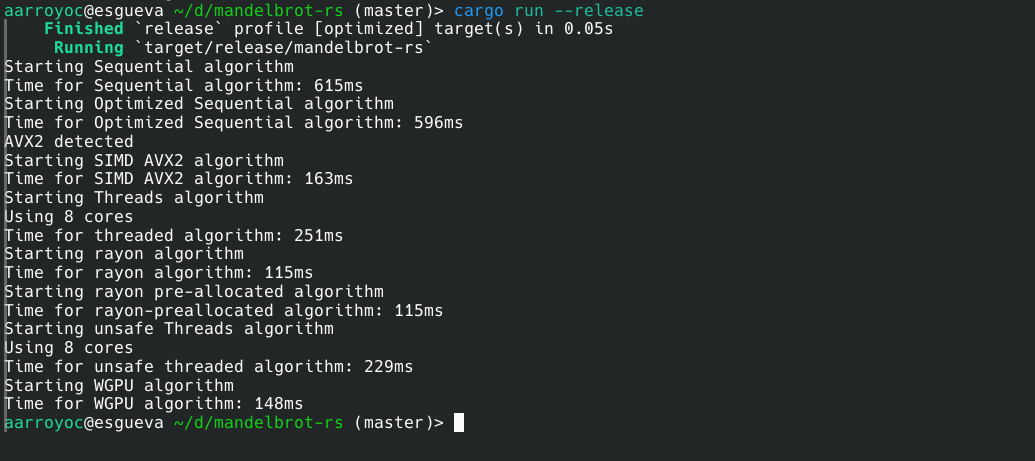
Los resultados en mi sistema, con una gráfica integrada de Intel, son buenos aunque no son los mejores. Este método tiene muchas ventajas como hemos visto pero quizá habréis intuido algunos problemas. El setup es muy farragoso y había que realizar copias entre memorias. Además en el caso concreto de WebGPU no soportar u8 nos penaliza. Y esto suponiendo un sistema con drivers de GPU estables, cosa que no siempre es así. El tema de las copias entre memorias es bastante clave y ya que podemos perder más de lo que ganamos con esta paralelización extrema. Por eso en problemas complejos a veces cuanto más tiempo podamos seguir en la GPU, mejor. Aunque hay que tener en cuenta que los ifs y los while en un shader arrastran a otros threads, así que con cuidado. Las arquitecturas con memoria unificada nos permiten que la CPU y la GPU no tengan que hacer copias de los datos en su comunicación. Pero en PC no son comunes e implicarían cambios importantes. Apple en sus equipos con procesador M1 en adelante ha adoptado este esquema por lo que no sería extraño que en el futuro los PCs evolucionasen hacia la memoria unificada aunque sin duda será más difícil porque implicaría mayor integración entre componentes que habitualmente vienen de empresas separadas.
Todo el código de todos los días está en GitHub