Paralelismo para lelos parte 2
En la entrada anterior de la serie vimos por qué el paralelismo era necesario así como la primera forma de paralelismo que podíamos usar, que eran las operaciones SIMD. Ahora veremos los procesadores multicore.
¿Qué es un procesador multicore?
Como vimos en el post anterior no podíamos subir las velocidades de los procesadores. Pero lo que la ley de Moore sí nos deja hacer es tener transistores más pequeños. Esto significa que podemos empezar a tener dos procesadores en el espacio de uno. Realmente no son procesadores enteros, sino que colaboran entre sí. Estos son los procesadores multicore.
Cada core ejecuta su propio código en paralelo, previa asignación del sistema operativo. Cada core tiene acceso a los mismos recursos que los demás. Esto es especialmente importante si hablamos de la memoria. Cada core tiene el mismo acceso a la memoria que los demás, por lo que hay que tener cuidado si dos cores intentan acceder a la misma memoria. Aunque sí que es cierto que pueden tener cachés individuales.
Threads
Nosotros no podemos decidir en qué core se ejecuta nuestro código. En realidad, el sistema operativo nos ofrece unas abstracciones llamadas procesos o threads (hilos). No son exactamente iguales un proceso y un thread pero para esto es muy similar. Los sistemas operativos nos dejan crear un número bastante elevado de threads y luego estos pueden, y repito pueden, ejecutarse en diferentes cores. Pero esto es una decisión que se toma por el sistema operativo. De esta forma podemos tener más threads que cores, algo vital para que podamos usar sistemas operativos multitarea. Esta es la diferencia entre la concurrencia: tener muchos threads con tareas separadas dentro del sistema que trabajan de forma coordinada y el paralelismo: ejecutar físicamente en paralelo.
En Rust
En Rust, a diferencia de C, tenemos funciones en la librería estándar para trabajar con threads de forma idéntica entre sistemas operativos. Por otro lado si lo que queremos es maximizar el rendimiento de nuestra máquina, no tiene sentido crear más threads que cores tiene nuestro ordenador, porque entonces alguno tendrá que esperar sí o sí.
La versión más básica de nuestro algoritmo de fractales de Mandelbrot sería la siguiente:
println!("Starting Threads algorithm");
let buffer: Vec = vec![0; BUFFER_SIZE];
let buffer = Arc::new(Mutex::new(buffer));
let cores: usize = std::thread::available_parallelism().unwrap().into();
let cores: u32 = cores as u32;
let now = Instant::now();
println!("Using {} cores", cores);
let mut threads = vec![];
for core in 0..cores {
let x_start = core*WIDTH/cores;
let x_end = if core == cores-1 {
WIDTH
} else {
(core+1)*WIDTH/cores
};
let buffer_rc = Arc::clone(&buffer);
threads.push(std::thread::spawn(move || {
for x in x_start..x_end {
for y in 0..HEIGHT {
let c = Complex {
real: x as f64 / 1000.0 - 2.5,
im: y as f64 / 1000.0 - 1.0,
};
let mut z = Complex {
real: 0.0,
im: 0.0,
};
let mut i = 0;
while i < ITERATIONS && z.abs() < 2.0 {
z.square();
z.plus(&c);
i = i + 1;
}
if i == ITERATIONS {
let mut buffer = buffer_rc.lock().unwrap();
let index = ((y * WIDTH + x) * 3) as usize;
buffer[index] = 255;
buffer[index+1] = 255;
buffer[index+2] = 255;
}
}
}
}));
}
for t in threads {
t.join().unwrap();
}
let elapsed = now.elapsed();
println!("Time for threaded algorithm: {}ms", elapsed.as_millis());
let buffer: Vec<u8> = std::mem::take(&mut buffer.lock().unwrap()); save_fractal(buffer, &Path::new("threaded.png");
La idea básica es que se divide el fractal en trozos iguales y cada trozo lo procesa un thread, que se crean con la función std::thread::spawn. Luego desde el thread original esperamos a que acaben todos. Aquí hay un par de cosas interesantes que en Rust se ven muy bien. La primera es que no podemos pasar el vector directamente a los threads, tenemos que meterlo en un Arc y luego clonarlo por cada core. Esto es por la gestión de memoria de Rust, diseñada para ser lo más parecido a una gestión automática tipo Java o Python pero sin las penalizaciones de rendimiento. Sin embargo cuando hay threads, Rust no puede saber cuantas partes del programa van a tener acceso a un punto concreto de la memoria. La solución es: contarlas. A esto se le llama reference counting y son las letras RC de Arc. Cada vez que hacemos un clone estamos incrementando el contador. Cuando, siguiendo las reglas de Rust, ya no usemos más ese trozo de memoria, restará el contador. Y si ya no queda ninguno, el contador es cero, se liberará la memoria.
La segunda tiene que ver con ese Mutex que vemos ahí. Si nuestro buffer hubiese solo de lectura, realmente no haría falta. Pero como queremos modificar el vector lo necesitamos. Entonces puede darse el caso de que queramos modificar el contenido del vector en dos threads a la vez. ¿Y eso se puede hacer? A nivel de ensamblador sí se puede, pero el resultado puede ser un completo caos. Es por ello que Rust nos fuerza a usar un Mutex, una estructura de datos que en esencia es un bloqueo. Cuando queremos modificar el vector, pedimos acceso, esperamos si no lo tenemos, una vez lo tenemos escribimos y después devolvemos el bloqueo (se libera cuando ya no se usa más en un scope, igual que liberar memoria). Esta distinción se puede hacer gracias a que Rust separa variables mutables e inmutables a nivel de tipos.
Rayon
En Rust existe otra forma de hacer esto, usando una librería que cambia un poco el paradigma, se trata de Rayon. No todos los problemas de paralelización se pueden resolver con Rayon pero este sí. La idea es, programa tu código usando iteradores estándar de Rust (las alternativas de alto nivel a los bucles) y obtén paralelización sin tener que pensar en ello. Esto es precisamente una de las ventajas de los iteradores respecto a los bucles, que pueden ser reordenados por algo en medio, en este caso una librería para paralelizar.
let now = Instant::now();
let mut buffer: Vec<u8> = vec![0; BUFFER_SIZE];
buffer
.par_chunks_exact_mut(3)
.enumerate()
.for_each(|(idx, chunk)| {
let x = (idx as u32) % WIDTH;
let y = (idx as u32) / WIDTH;
let c = Complex {
real: x as f64 / 1000.0 - 2.5,
im: y as f64 / 1000.0 - 1.0,
};
let mut z = Complex {
real: 0.0,
im: 0.0,
};
let mut i = 0;
while i < ITERATIONS && z.abs() < 2.0 {
z.square();
z.plus(&c);
i = i + 1;
}
if i == ITERATIONS {
chunk[0] = 255;
chunk[1] = 255;
chunk[2] = 255;
}
});
let elapsed = now.elapsed();
println!("Time for rayon-preallocated algorithm: {}ms", elapsed.as_millis());
Este código hace unas divisiones extra pero queda bastante claro, no vemos ningún Arc ni Mutex y cuando veamos los tiempos os va a sorprender.
Unsafe Rust
Por último vamos a ver una versión que se salta los Mutex y los Arc. Esto se puede hacer en Rust aunque ya se considera unsafe. La idea es que Arc no nos hace falta porque el thread principal, donde lo creamos vive más que los otros threads, por tanto lo controla al 100%. Y el Mutex no hace falta porque aunque modificamos el mismo vector, nunca dos threads van a modificar la misma posición porque están asignadas de forma exclusiva a cada thread.
println!("Starting unsafe Threads algorithm");
let mut buffer = vec![0u8; BUFFER_SIZE];
let raw_buffer = RawBuffer(buffer.as_mut_ptr() as *mut u8);
let cores: usize = std::thread::available_parallelism().unwrap().into();
let cores: u32 = cores as u32;
println!("Using {} cores", cores);
let now = Instant::now();
let mut threads = vec![];
for core in 0..cores {
let x_start = core*WIDTH/cores;
let x_end = if core == cores-1 {
WIDTH
} else {
(core+1)*WIDTH/cores
};
let raw_buffer_clone = raw_buffer.clone();
threads.push(std::thread::spawn(move || {
let q = raw_buffer_clone;
for x in x_start..x_end {
for y in 0..HEIGHT {
let c = Complex {
real: x as f64 / 1000.0 - 2.5,
im: y as f64 / 1000.0 - 1.0,
};
let mut z = Complex {
real: 0.0,
im: 0.0,
};
let mut i = 0;
while i < ITERATIONS && z.abs() < 2.0 {
z.square();
z.plus(&c);
i = i + 1;
}
if i == ITERATIONS {
unsafe {
let index = ((y * WIDTH + x) * 3) as usize;
*q.0.add(index) = 255;
*q.0.add(index + 1) = 255;
*q.0.add(index + 2) = 255;
}
}
}
}
}));
}
for t in threads {
t.join().unwrap();
}
...
#[derive(Clone)]
struct RawBuffer(*mut u8);
unsafe impl Send for RawBuffer {}
unsafe impl Sync for RawBuffer {}
Esto en teoría nos ahorrará el overhead de Arc y de Mutex.
Resultados
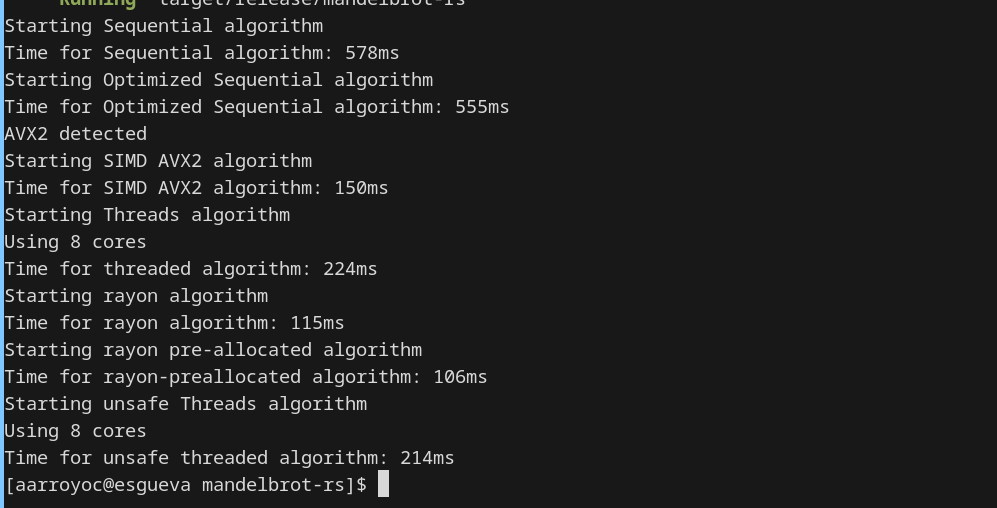
Los resultados son muy interesantes, usando threads de forma simple con Arc y Mutex obtenemos una mejora pero no es mejor que el código SIMD. Y eso que en SIMD vamos de 4 en 4 y aquí tenía 8 cores disponibles. Por otro lado la versión que elimina Arc y Mutex es ligeramente más rápida. Esto es consistente, siempre que ejecuto, esta es un pelín más rápida. Pero eso, muy poquito. Ese es el overhead de Arc y Mutex.
Por otro lado la versión más rápida es la de rayon preallocated, la que os he puesto, hay otra de Rayon que no os he compartido. Se alza como la opción más rápida hasta ahora. Pero si usa threads igualmente, ¿por qué es mucho más rápida?
El motivo es que Rayon ha ido haciendo los threads de forma más inteligente. En este problema hay zonas muy rápidas de hacer y otras más lentas. Rayon ha ido haciendo paquetitos y entregándoselos a los threads según se iban quedando ociosos. En este tipo de problemas es una diferencia muy reseñable, fijaos que tarda menos de la mitad que nuestras versiones con reparto estático.