Natural Language Understanding con Snips NLU en Python
17/04/2018
Uno de los campos más importantes de la inteligencia artificial es el del tratamiento del lenguaje natural. Ya en 1955, en el primer evento sobre Inteligencia Artificial, y promovido entre otros por John McCarthy (creador de Lisp) y Claude Shannon (padre de la teoría de la información y promotor del uso del álgebra de boole para la electrónica), estas cuestiones entraron en el listado de temas.
En aquella época se era bastante optimista con las posibilidades de describir el lenguaje natural (inglés, español, ...) de forma precisa con un conjunto de reglas de forma similar a las matemáticas. Luego se comprobó que esto no era una tarea tan sencilla.
Hoy día, es un campo donde se avanza mucho todos los días, aprovechando las técnicas de machine learning combinadas con heurísticas propias de cada lenguaje.
Natural Language Understanding nos permite saber qué quiere decir una frase que pronuncia o escribe un usuario. Existen diversos servicios que provee de esta funcionalidad: IBM Watson, Microsoft LUIS y también existe software libre, como Snips NLU.
 Snips NLU es una librería hecha en Rust y con interfaz en Python que funciona analizando el texto con datos entrenados gracias a machine learning y da como resultado un intent, o significado de la frase y el valor de los slots, que son variables dentro de la frase.
Snips NLU es una librería hecha en Rust y con interfaz en Python que funciona analizando el texto con datos entrenados gracias a machine learning y da como resultado un intent, o significado de la frase y el valor de los slots, que son variables dentro de la frase.
Y Snips NLU nos devuelve:
Pero para esto, antes hay que hacer un par de cosas.
Instala Snips NLU con Pipenv (recomendado) o Pip:
En primer lugar vamos a crear un listado de frases que todas expresen la intención de obtener el tiempo y lo guardamos en un fichero llamado obtenerTiempo.txt. Así definimos un intent:
La sintaxis es muy sencilla. Cada frase en una línea. Cuando una palabra forme parte de un slot, se usa la sintaxis [NOMBRE SLOT:TIPO](texto). En el caso de [donde:localidad](Frías). Donde es el nombre del slot, localidad es el tipo de dato que va y Frías es el texto original de la frase. En el caso del slot cuando, hemos configurado el tipo como snips/time que es uno de los predefinidos por Snips NLU.
Creamos también un fichero llamado localidad.txt, con los posibles valores que puede tener localidad. Esto no quiere decir que no capture valores fuera de esta lista, como veremos después, pero tienen prioridad si hubiese más tipos. También se puede configurar a que no admita otros valores, pero no lo vamos a ver aquí.
Ahora generamos un fichero JSON listo para ser entrenado con el comando generate-dataset.
Ya estamos listos para el entrenamiento. Creamos un fichero Python como este y lo ejecutamos:
El entrenamiento se produce en fit, y esta tarea puede tardar dependiendo del número de datos que metamos. Una vez finalizado, generama un fichero trained.json con el entrenamiento ya realizado.
Ha llegado el momento de hacer preguntas, cargando el fichero de los datos entrenados.
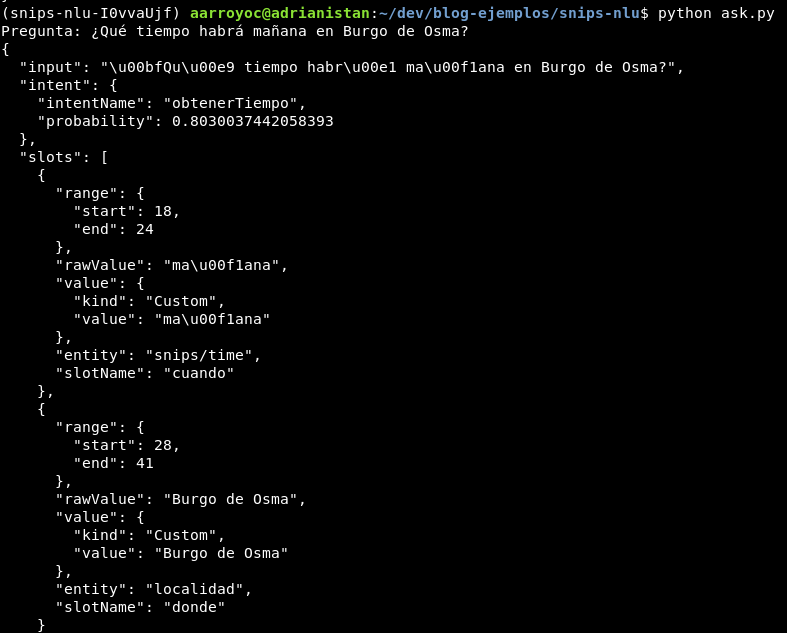 Ahora sería tarea del programador usar el valor del intent y de los slots para dar una respuesta inteligente.
Ahora sería tarea del programador usar el valor del intent y de los slots para dar una respuesta inteligente.
Te animo a que te descargues el proyecto o lo hagas en casa e intentes hacerle preguntas con datos retorcidos a ver qué pasa y si guarda en los slots el valor correcto.
En aquella época se era bastante optimista con las posibilidades de describir el lenguaje natural (inglés, español, ...) de forma precisa con un conjunto de reglas de forma similar a las matemáticas. Luego se comprobó que esto no era una tarea tan sencilla.
Hoy día, es un campo donde se avanza mucho todos los días, aprovechando las técnicas de machine learning combinadas con heurísticas propias de cada lenguaje.
Natural Language Understanding nos permite saber qué quiere decir una frase que pronuncia o escribe un usuario. Existen diversos servicios que provee de esta funcionalidad: IBM Watson, Microsoft LUIS y también existe software libre, como Snips NLU.
 Snips NLU es una librería hecha en Rust y con interfaz en Python que funciona analizando el texto con datos entrenados gracias a machine learning y da como resultado un intent, o significado de la frase y el valor de los slots, que son variables dentro de la frase.
Snips NLU es una librería hecha en Rust y con interfaz en Python que funciona analizando el texto con datos entrenados gracias a machine learning y da como resultado un intent, o significado de la frase y el valor de los slots, que son variables dentro de la frase.¿Qué tiempo hará mañana en Molina de Aragón?
Y Snips NLU nos devuelve:
- intent: obtenerTiempo
- slots:
- cuando: mañana
- donde: Molina de Aragón
Pero para esto, antes hay que hacer un par de cosas.
Instalar Snips NLU
Instala Snips NLU con Pipenv (recomendado) o Pip:
pipenv install snips-nlu
pip install snips-nlu
Datos de entrenamiento
En primer lugar vamos a crear un listado de frases que todas expresen la intención de obtener el tiempo y lo guardamos en un fichero llamado obtenerTiempo.txt. Así definimos un intent:
¿Qué tiempo hará [cuando:snips/time](mañana) en [donde:localidad](Molina de Aragón)?
¿Qué tal hará [cuando:snips/time](pasado mañana) en [donde:localidad](Ponferrada)?
¿Qué temperatura habrá [cuando:snips/time](mañana) en [donde:localidad](Frías)?
La sintaxis es muy sencilla. Cada frase en una línea. Cuando una palabra forme parte de un slot, se usa la sintaxis [NOMBRE SLOT:TIPO](texto). En el caso de [donde:localidad](Frías). Donde es el nombre del slot, localidad es el tipo de dato que va y Frías es el texto original de la frase. En el caso del slot cuando, hemos configurado el tipo como snips/time que es uno de los predefinidos por Snips NLU.
Creamos también un fichero llamado localidad.txt, con los posibles valores que puede tener localidad. Esto no quiere decir que no capture valores fuera de esta lista, como veremos después, pero tienen prioridad si hubiese más tipos. También se puede configurar a que no admita otros valores, pero no lo vamos a ver aquí.
Burgos
Valladolid
Peñaranda de Bracamonte
Soria
Almazán
Íscar
Portillo
Toro
Fermoselle
Sahagún
Hervás
Oña
Saldaña
Sabiñánigo
Jaca
Ahora generamos un fichero JSON listo para ser entrenado con el comando generate-dataset.
generate-dataset --language es --intent-files obtenerTiempo.txt --entity-files localidad.txt > dataset.json
Entrenamiento
Ya estamos listos para el entrenamiento. Creamos un fichero Python como este y lo ejecutamos:
import io
import json
from snips_nlu import load_resources, SnipsNLUEngine
load_resources("es")
with io.open("dataset.json") as f:
dataset = json.load(f)
engine = SnipsNLUEngine()
engine.fit(dataset)
engine_json = json.dumps(engine.to_dict())
with io.open("trained.json",mode="w") as f:
f.write(engine_json)
El entrenamiento se produce en fit, y esta tarea puede tardar dependiendo del número de datos que metamos. Una vez finalizado, generama un fichero trained.json con el entrenamiento ya realizado.
Hacer preguntas
Ha llegado el momento de hacer preguntas, cargando el fichero de los datos entrenados.
import io
import json
from snips_nlu import SnipsNLUEngine, load_resources
load_resources("es")
with io.open("trained.json") as f:
engine_dict = json.load(f)
engine = SnipsNLUEngine.from_dict(engine_dict)
phrase = input("Pregunta: ")
r = engine.parse(phrase)
print(json.dumps(r, indent=2))
Ahora sería tarea del programador usar el valor del intent y de los slots para dar una respuesta inteligente.Te animo a que te descargues el proyecto o lo hagas en casa e intentes hacerle preguntas con datos retorcidos a ver qué pasa y si guarda en los slots el valor correcto.