jq, el sed del siglo XXI
Que levante la mano quién no ha oído hablar de sed. Una herramienta presente en cualquier sistema UNIX, se trata de un editor de texto en modo streaming. Aunque sed es una herramienta muy potente, con un lenguaje de programación propio que es Turing completo, la mayor cantidad de usos son sustituir o extraer datos usando expresiones regulares y los comandos s y p de sed. jq es sed para el siglo XXI porque trabaja de forma nativa con JSON, es decir, trabaja con objetos, no con texto plano.
El caso del texto plano
Tradicionalmente en UNIX se han tomado varias decisiones de diseño, que a falta de otros sistemas más populares, se han tomado como acertadas. Una de ellas es el concepto de texto plano. En UNIX el formato por defecto de cualquier cosa ha sido texto plano. Texto plano entendido como que no se tiene en cuenta el formato o la estructura del fichero. Las herramientas del sistema han sido diseñadas para trabajar con él (grep, sed, cut, ...). Esto hace muy difícil acceder a partes concretas de un archivo. Ciertas herramientas como AWK soportan formatos estructurados como CSV, de forma bastante cómoda, pero CSV sigue siendo un formato con limitaciones.
Existen sistemas que han tomado esto de otra forma, por ejemplo PowerShell. La shell de Microsoft usa objetos como elemento básico de comunicación, soportando atributos y arrays y desterrando las operaciones de texto plano a un segundo plano (ba dum tss).
El texto plano no es malo, y muchas veces es lo mejor. Consume pocos recursos, es simple de entender, pero muchas veces necesitamos una estructura por detrás que nos ayude a manipular los datos. En mi opinión debería haber más documentos estructurados (que luego pueden contener atributos con text plano claro) por defecto.
jq, la esencia de sed para JSON
Si hablamos de formatos para documentos, quizá el más popular sea JSON. JSON es simple y efectivo, poco verboso, soporta booleanos, números, cadenas de texto plano, objetos y arrays. JSON casualmente usa ficheros de texto plano para guardarse, pero es un error usar grep, sed y AWK para buscar en estos ficheros. Al hacerlo estamos ignorando por completo la estructura del documento y esto puede hacer todo más complejo, dar resultados erróneos, etc
jq, aplica las ideas de estas herramientas clásicas de UNIX al sistema de documentos de JSON. Lo puedes instalar en Debian/Ubuntu fácilmente:
sudo apt install jq
El hola mundo de jq sería aplicar el selector ., para seleccionar todo el documento JSON.
Para todos los ejemplos voy a usar el siguiente fichero JSON, totalmente inventado:
{
"cars" : [
{
"name": "Renault 21",
"company": "Renault",
"year" : 1980
},
{
"name": "Citröen C-Zero",
"company": "Citröen",
"year": 2009
},
{
"name": "Opel Monza",
"company": "Opel",
"year": 1978
},
{
"name": "Pegaso Z-102",
"company": "Pegaso",
"year": 1951
}
],
"drivers" : [
{
"name" : "James Hunt",
"birthplace" : "United Kingdom"
},
{
"name" : "Niki Lauda",
"birthplace" : "Austria"
},
{
"name" : "Jim Clark",
"birthplace": "United Kingdom"
},
{
"name" : "Juan Manuel Fangio",
"birthplace": "Argentina"
},
{
"name" : "Fernando Alonso",
"birthplace": "Spain"
}
]
}
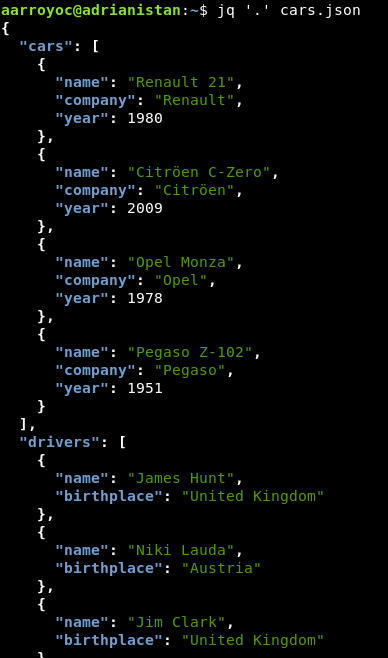
Acceso a datos
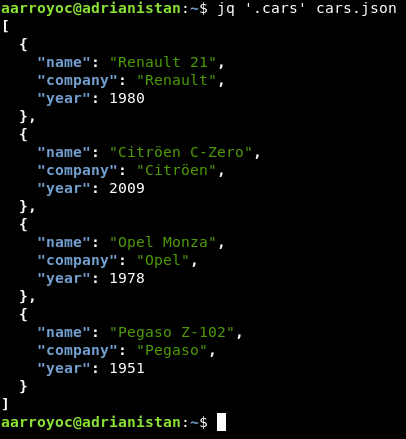
Para acceder a los datos usamos una sintaxis similar a la de JavaScript. Accedemos mediante punto a los atributos y con corchetes a los arrays. Si queremos indicar que un campo es opcional, usamos ?. Por ejemplo, si queremos acceder solamente a los coches:
Un concepto básico de jq son los pipes, de forma similar a Bash, podemos pasar la salida de un comando a otro. Sin embargo, los pipes de jq no transmiten texto plano, sino documentos JSON. Veamos un ejemplo, para acceder al campo year podemos realizarlo de forma compuesta usando pipes. En primer lugar seleccionaríamos el subdocumento del coche y en el siguiente paso accederíamos al elemento year del subdocumento.

Otro concepto muy potente de jq es el poder realizar map sobre cada elemento del array. De esta forma, todo lo que indiquemos a continuación se realizará para todos los documentos del array. Estos arrays también soportan slicing, por lo que podemos decir que el map se realice solo desde el elemento X al elemento Y de la forma [X:Y].
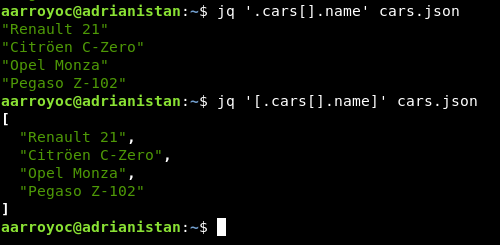
Si además queremos que la salida sea un array válido de JSON, encerramos la expresión entre corchetes.
Búsquedas con regex
Ya hemos visto como acceder a los elementos. Vamos ahora a ver como realizar búsquedas por regex. El comando test nos permite ejecutar una comprobación dada una expresión regular y devuelve true o false.

Sin embargo, esto no es muy útil, ya que la mayoría de las veces no vamos a querer un listado de true y falses. select es un comando que filtra los subdocumentos que recibe dependiendo de su expresión en el interior es true o false. Combinándolos podemos filtrar la salida según la búsqueda.

Aplicando las reglas de los pipes podemos realizar la búsqueda solo en un campo pero obtener el subdocumento completo. Por ejemplo, aquí obtenemos un listado de pilotos que han nacido en Reino Unido.

Generando documentos
Hasta ahora hemos visto como acceder, buscar y filtrar información del documento. Pero jq permite también generar documentos JSON nuevos de salida. Para ello, hay que usar las llaves y escribir la estructura de nuestro documento.
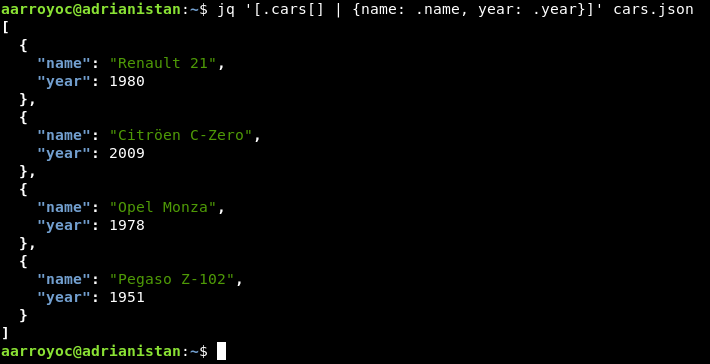
Aquí en este ejemplo, hemos decidido quedarnos con los coches y eliminar el campo de company del JSON. Usamos map, pipes y todo entre corchetes, para obtener un array de salida. Evidentemente, como los campos de entrada y salida se llaman igual, esto se puede simplificar.
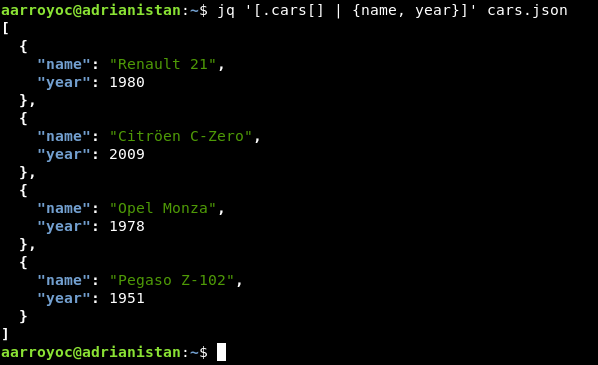
A jq también le podemos pasar variables externas desde fuera con el argumento --arg. Si usamos el argumento -n podemos generar documentos JSON desde cero.

Las variables se referencian por su nombre siempre precedidas del símbolo del dólar (como en Bash). Se pueden crear variables usando as $variable.
Funciones y operadores aritméticos
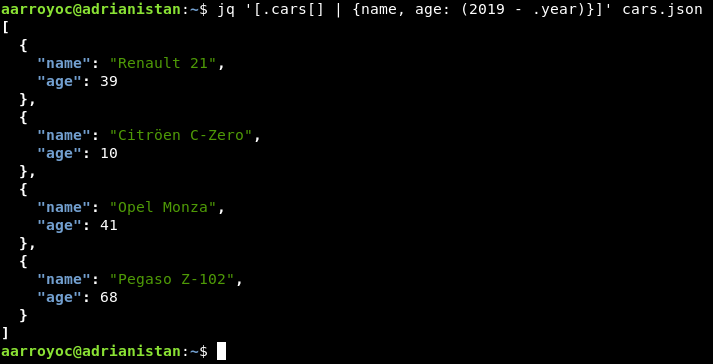
jq contiene un buen puñado de funciones y operadores aritméticos. Por ejemplo, podemos usar la resta para calcular en vez del año de fabricación del coche, su edad actual (suponiendo que vivimos en 2019).
Existen funciones muy interesantes, algunas de ellas son length (longitud de una cadena de texto o de un array), has (comprobar si existe una propiedad), in (la función inversa de has), map (aplicar una función a todos los elementos y devolver el nuevo array), del (elimina un subdocumento), add (añade todos los elementos entre sí), any, all (comprueban si una condición se cumple en algún elemento o en todos), flatten (simplifica los arrays, aplanándolos), sort, sort_by (para ordenar), group_by (para agrupar en base a un campo), unique (elimina los elementos duplicados), while (aplica una operación hasta que se deje de cumplir la condición), join (al estilo SQL) y muchos más.
En jq además existen operadores condicionales (if-then-else, and, or y not) y try-catch para detectar errores. No obstante, en la mayoría de las ocasiones no los vas a usar y es mucho más legible usar los elementos presentados anteriormente.
En general, si tienes un buen dominio de la programación funcional, jq te parecerá bastante intuitivo, ya que las similaridades son evidentes.
Asignaciones
Una cosa muy interesante que tiene jq es poder editar los archivos directamente, sin tener que generar uno nuevo, a través de las asignaciones. La asignación básica es |= que permite modificar un documento con una versión nueva. Por ejemplo, si queremos editar la compañía del coche, únicamente cuando es Opel, podemos recurrir a una combinación de if-then-else con |=.
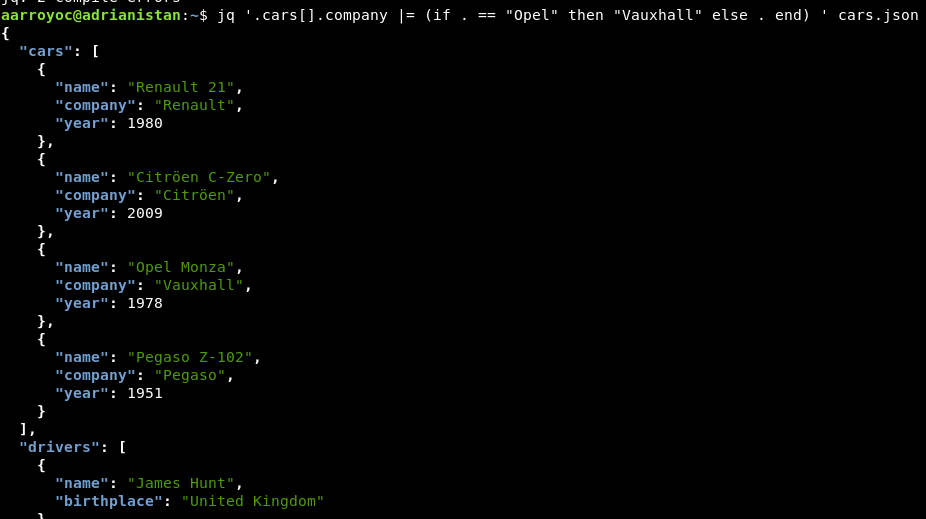
Como vemos, el fichero de salida es idéntico al original pero modificando Opel por Vauxhall.
Conclusiones
jq es una herramienta muy potente, pensada para trabajar con documentos JSON en un flujo de trabajo similar al de Bash y Sed pero con nociones de la estructura del archivo. jq se puede usar en cualquier sistema prácticamente y es muy potente, como podéis haber visto. Espero que os haya picado el gusanillo y a partir de ahora lo empecéis a utilizar. Muy interesante es su combinación con curl para poder trabajar con APIs web desde la terminal.