Introducción a Apache Spark con datos de la Fórmula 1
Este post es una adaptación del taller que di en el VallaTech Summit 2023 organizado por el Google Developers Group de Valladolid
Apache Spark es un motor de computación distribuido en cluster diseñado para manejar grandes cantidades de datos. Es opensource y está programado en Scala, aunque se puede usar desde Java, Python y R también.Existe una versión comercial, con características adicionales, llamada Databricks.
¿Cuándo necesitamos usar Apache Spark? Cuando necesitamos realizar transformaciones a unos datos y
- Los datos son demasiado grandes, ocupan demasiado espacio, …
- Las transformaciones no necesitan ser “real time” (hay otras herramientas específicas si buscamos baja latencia).
- El cómputo se beneficia de la paralelización
En general: procesamiento de datos (ETL), ciertos tipos de machine learning (ML), reportes, analíticas, etc. De forma habitual trabajaremos con un clúster de Spark, al que se le van mandando jobs. Los jobs, si están programados usando las APIs de Spark, aprovecharán la potencia del clúster completo de forma eficiente.
¿Cómo consigue Spark funcionar?
Hay tres pilares sobre los cuáles Spark es eficiente:
MapReduce: En Spark hay dos tipos de operaciones fundamentales:
- Map: Se aplica una función para cada dato, que devuelve otro dato. Es fácil ver que es paralelizable.
- Reduce: Se aplica una función que N datos, los combina en un dato único. Aquí para que sea paralelizable idealmente nuestra operación de reducción deberá ser asociative y conmutativa. Es decir, no importe el orden en el que se van haciendo las reducciones.
Los Map y Reduce se distribuyen por el clúster. Spark se encarga de enviar los datos de forma transparente entre los nodos.
RDD: Inmutabilidad y pereza Los datos se cargan en un RDD. Sobre un RDD podemos hacer operaciones pero los RDD en sí son inmutables. Se nos genera otro RDD con el cambio. ¿Con el cambio? Realmente no, se almacena el cambio que hay que hacer pero son perezosos. Hasta que no necesitemos los datos, no se realizará la operación.
HDFS Aunque Spark funciona con muchas fuentes de datos, es habitual encontrarlo HDFS, un sistema de archivos (Hadoop FileSystem) optimizado para data lakes. Este sistema de archivos está diseñado para exponerse en red y que los nodos puedan leer y escribir independientemente del resto de los nodos, logrando así una paralelización a nivel de I/O.
Datos de la Fórmula 1
Vamos a usar datos de la Fórmula 1 para probar las cosas más esenciales de Spark. Los datos están cogidos de este repositorio de Kaggle, aunque también los tengo subidos a GitHub
Races are won at the track. Championships are won at the factory. Mercedes (2019)
spark-shell
La primera forma que tenemos de usar Spark (previamente descomprimido de la página de Spark) es mediante el Spark-Shell. Línea a línea podemos ir ejecutando código (en Scala 2).
Ejecutamos bin/spark-shell y una vez cargado podemos leer un fichero de datos, en este caso un CSV con los circuitos de la Fórmula 1 de toda su historia.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.5.0
/_/
Using Scala version 2.12.18 (OpenJDK 64-Bit Server VM, Java 21)
Type in expressions to have them evaluated.
Type :help for more information.
scala> 23/11/27 22:43:34 WARN GarbageCollectionMetrics: To enable non-built-in garbage collector(s) List(G1 Concurrent GC), users should configure it(them) to spark.eventLog.gcMetrics.youngGenerationGarbageCollectors or spark.eventLog.gcMetrics.oldGenerationGarbageCollectors
scala> df.show()
+---------+--------------+--------------------+------------+---------+--------+---------+---+--------------------+
|circuitId| circuitRef| name| location| country| lat| lng|alt| url|
+---------+--------------+--------------------+------------+---------+--------+---------+---+--------------------+
| 1| albert_park|Albert Park Grand...| Melbourne|Australia|-37.8497| 144.968| 10|http://en.wikiped...|
| 2| sepang|Sepang Internatio...|Kuala Lumpur| Malaysia| 2.76083| 101.738| 18|http://en.wikiped...|
| 3| bahrain|Bahrain Internati...| Sakhir| Bahrain| 26.0325| 50.5106| 7|http://en.wikiped...|
| 4| catalunya|Circuit de Barcel...| Montmeló| Spain| 41.57| 2.26111|109|http://en.wikiped...|
| 5| istanbul| Istanbul Park| Istanbul| Turkey| 40.9517| 29.405|130|http://en.wikiped...|
| 6| monaco| Circuit de Monaco| Monte-Carlo| Monaco| 43.7347| 7.42056| 7|http://en.wikiped...|
| 7| villeneuve|Circuit Gilles Vi...| Montreal| Canada| 45.5| -73.5228| 13|http://en.wikiped...|
| 8| magny_cours|Circuit de Nevers...| Magny Cours| France| 46.8642| 3.16361|228|http://en.wikiped...|
| 9| silverstone| Silverstone Circuit| Silverstone| UK| 52.0786| -1.01694|153|http://en.wikiped...|
| 10|hockenheimring| Hockenheimring| Hockenheim| Germany| 49.3278| 8.56583|103|http://en.wikiped...|
| 11| hungaroring| Hungaroring| Budapest| Hungary| 47.5789| 19.2486|264|http://en.wikiped...|
| 12| valencia|Valencia Street C...| Valencia| Spain| 39.4589|-0.331667| 4|http://en.wikiped...|
| 13| spa|Circuit de Spa-Fr...| Spa| Belgium| 50.4372| 5.97139|401|http://en.wikiped...|
| 14| monza|Autodromo Naziona...| Monza| Italy| 45.6156| 9.28111|162|http://en.wikiped...|
| 15| marina_bay|Marina Bay Street...| Marina Bay|Singapore| 1.2914| 103.864| 18|http://en.wikiped...|
| 16| fuji| Fuji Speedway| Oyama| Japan| 35.3717| 138.927|583|http://en.wikiped...|
| 17| shanghai|Shanghai Internat...| Shanghai| China| 31.3389| 121.22| 5|http://en.wikiped...|
| 18| interlagos|Autódromo José Ca...| São Paulo| Brazil|-23.7036| -46.6997|785|http://en.wikiped...|
| 19| indianapolis|Indianapolis Moto...|Indianapolis| USA| 39.795| -86.2347|223|http://en.wikiped...|
| 20| nurburgring| Nürburgring| Nürburg| Germany| 50.3356| 6.9475|578|http://en.wikiped...|
+---------+--------------+--------------------+------------+---------+--------+---------+---+--------------------+
only showing top 20 rows
Spark SQL y DataFrames
La estructura de datos fundamental de Spark es el RDD. Sin embargo, para la mayoría de tareas es de demasiado bajo nivel. Spark ofrece una API de DataFrames, que nos permite hacer operaciones trabajando con filas y columnas. La API es similar a SQL pero por debajo usa todas las facilidades de Spark para que el cómputo sea distribuido en el clúster de forma óptima.
Para referirnos a una columna usaremos $"columna", col("columna") o df("columna").
Algunos ejemplos de cosas que permite la API de Spark SQL.
- Generar dataframe nuevo seleccionando ciertas columnas:
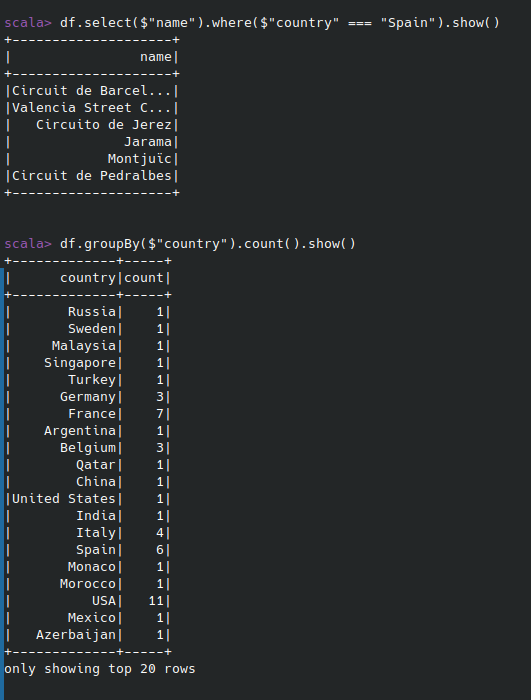
df.select($“name”, $”country”).show() - Filtrar filas for valor de una columna:
df.select($”name”).where($”country” === “Spain”).show() - Agrupar y contar:
df.groupBy($”country”).count().show() - Ordenar:
df.orderBy(desc($”name”)).show() - Joins:
df.join(races, "circuitId", "inner")
Desafío 1
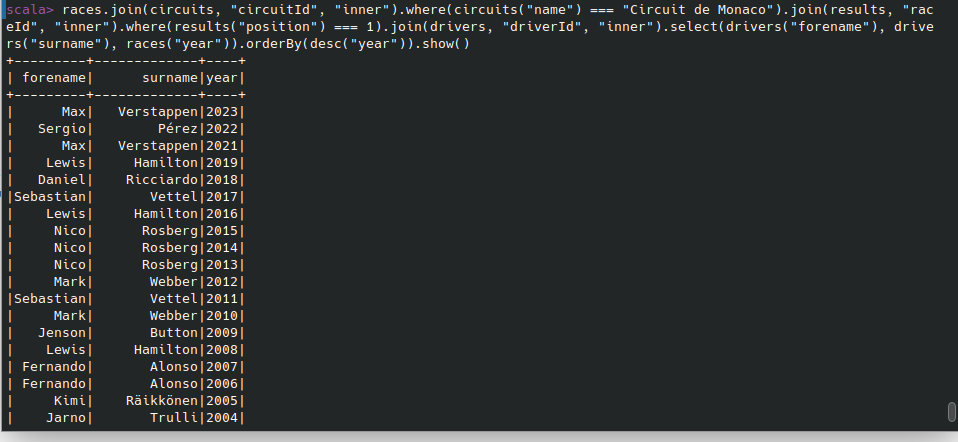
Obtener una tabla con la temporada y el piloto que ganó esa temporada en el circuito de Mónaco.
Lo primero será abrir los dataframes de los datos que necesitamos:
val circuits = spark.read.format(“csv”).option(“header”, true).load(“data/circuits.csv”)
val races = spark.read.format(“csv”).option(“header”, true).load(“data/races.csv”)
val drivers = spark.read.format(“csv”).option(“header”, true).load(“data/drivers.csv”)
val results = spark.read.format(“csv”).option(“header”, true).load(“data/results.csv”)
Dejamos solo las carreras que tuvieron lugar en Mónaco
val racesInMonaco = races.join(circuits, "circuitId", "inner").where(circuits("name") === "Circuit de Monaco")
Obtenemos los ganadores de Mónaco
val monacoWinners = racesInMonaco.join(results, "raceId", "inner").where(results("position") === 1)
Obtenemos nombre, apellido y años de la victoria, ordenamos de forma descendente:
monacoWinners.join(drivers, "driverId", "inner").select(drivers("forename"), drivers("surname"), races("year")).orderBy(desc("year"))
Particiones
Para distribuir el trabajo, Spark debe saber cómo repartir los datos dentro de los nodos. Para ello usa el concepto de particiones. Tomará un punto de referencia (como el valor de una columna) para saber si cierto dato tiene que ir en una partición o en otra. Los nodos procesan particiones enteras. Si tu dataset tiene 4 particiones, podrás usar 4 nodos en paralelo.
En un DataFrame podemos reparticionar usando el método repartition. Podemos indicarle el número de particiones que queremos y/o la columna sobre la que hacer la partición
Idealmente se debe escoger una columna donde la mayoría de operaciones de un nodo tengan todos el mismo valor
Agregaciones
Las agregaciones o reducciones son la principal diferencia entre una base de datos convencional.
Las BBDD relacionales suelen estar optimizadas para OLTP. Las agregaciones (como GROUP BY) se soportan pero no son eficientes.
Spark está diseñado de modo OLAP, de modo que las agregaciones son operaciones muy eficientes.
Para agrupar en Spark usamos groupBy(). Dentro indicamos las columnas por las que agrupamos, seguido de agg y una función de agregación. Ejemplo:
df.groupBy("name").agg(sum("pedidos") as "pedidos_total")Desafío 2
¿Cuántas vueltas rápidas tiene cada piloto?
val fastestLapDriversSum = results
.where(results("rank") === 1)
.groupBy(results("driverId"))
.agg(sum("rank") as "fastest_laps")
.join(drivers, "driverId", "inner")
.select("forename", "surname", "fastest_laps")
.orderBy(desc("fastest_laps"))
Despliegue
Spark Shell es muy bonito pero salvo para hacer pruebas, es poco práctico Podemos generar un JAR para enviar a Spark. Mínimo dos archivos: build.sbt y src/main/scala/Formula1.scala
El build.sbt es tan simple como esto:
name := "Formula 1 Spark"
version := "1.0"
scalaVersion := "2.12.18"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "3.5.0"
El otro fichero, donde irán nuestros algoritmos, deberá seguir la siguiente estructura.
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
object Formula1 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder.appName("Formula 1").getOrCreate()
// hacer cosas con el objeto spark
spark.stop()
}
}
Compilaríamos con:
sbt packageY lo mandaríamos al clúster de Spark con spark-submit. En este caso para ejecutar el JAR en un clúster local.
bin/spark-submit --class "Formula1" --master local[4] FICHERO.jarmap / withColumn / when
Con map podemos cambiar por completo cada fila dentro de un DF. Podemos ejecutar cualquier código Scala y obtendremos de vuelta un RDD, no un DF. Así que deberemos transformarlo de vuelta si queremos.
circuits.map(row => (row.getString(0), row.getString(2).toUpperCase)).toDF(“circuitId”, “name”)
Con withColumn podemos agregar /sustituir una columna. Las funciones tienen que ser funciones de Spark o UDFs (más adelante)
circuits.withColumn(“name_uppercase”, upper(col(“name”)))
Una función de Spark muy interesante con withColumn es when.
circuits.withColumn(“in_spain”, when(col(“country”) === “Spain”, true).otherwise(false))
UDF y UDAF
Spark SQL contiene una gran cantidad de funciones. Pero a veces nosotros queremos definir las nuestras. Se pueden programar en Scala y que sean accesibles tanto desde Scala como desde SQL. UDF si operan sobre columnas y UDAF si opera sobre agregaciones. Aunque existe ya la función upper, hagamos como si no existiese para el siguiente ejemplo
def upperCase(str: String): String = str.toUpperCase
val upperCaseUDF = udf(upperCase _)
circuits.select(upperCaseUDF(col("name")).as("name"))
Spark ML
Se trata de una librería que implementa algoritmos de Machine Learning sobre Spark. Hay que tener en cuenta que Spark no accede a las GPUs, por lo que ciertos tipos de ML no son adecuados en Spark (redes neuronales por ejemplo). Pero con otros algoritmos su uso es ideal.
- Algoritmos de clústering
- Regresiones, SVM, Random Forest, Bayes, …
- Algoritmos de recomendación (ALS, …)
- Extracción y transformaciones de features
Desafío 3
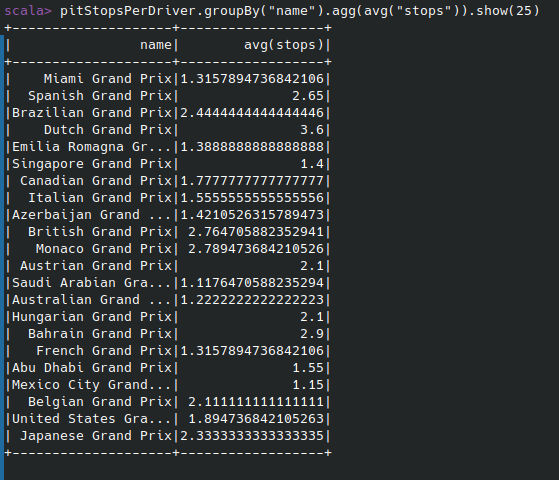
De los carreras de 2022. ¿Cuál fue el número de paradas promedio?
val racesIn2022 = races.filter(races("year") === 2022)
val pitStopsRaces2022 = racesIn2022.join(pitStops, "raceId", "inner")
val pitStopsPerDriver = pitStopsRaces2022
.groupBy(races("name"), col("driverId"))
.agg(max("stop") as "stops")
val pitStopsAvgPerRace = pitStopsPerDriver
.groupBy("name")
.agg(avg("stops"))
SQL
Esta API se parece mucho a SQL. Tanto que si nos gusta, podemos escribir las queries en, ¡SQL!
df.createOrReplaceTempView(“circuits”)
spark.sql(“SELECT name, country FROM circuits”).show()
Desafío 4
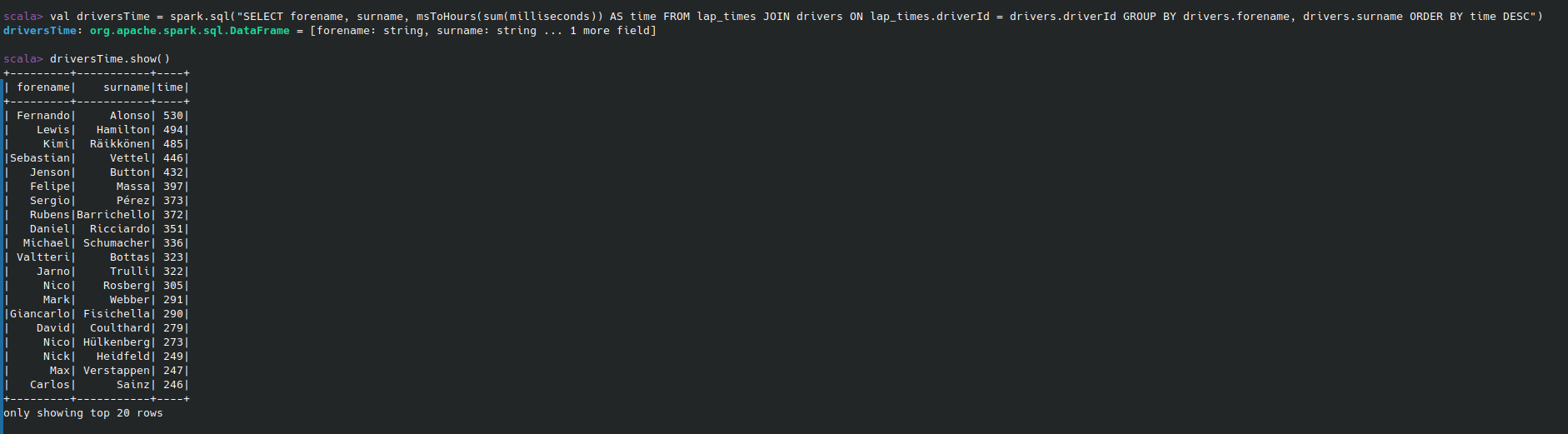
¿Cuántas horas ha corrido cada piloto de F1?
lapTimes.createOrReplaceTempView("lap_times")
drivers.createOrReplaceTempView("drivers")
def millisecondsToHours(n: Long): Long = {
n / 3600000
}
val millisecondsToHoursUDF = udf(millisecondsToHours _)
spark.udf.register("msToHours", millisecondsToHoursUDF)
val driversTime = spark.sql(
"""
|SELECT forename, surname, msToHours(sum(milliseconds)) AS time
|FROM lap_times
|JOIN drivers ON lap_times.driverId = drivers.driverId
|GROUP BY drivers.forename, drivers.surname
|ORDER BY time DESC
|""".stripMargin)