Generar frases con cadenas de Markov. Machine Learning en Python
25/01/2018
Hoy vamos a hacer un ejercicio muy sencillo de machine learning. Para ello usaremos cadenas de Markov. Trataremos de generar frases totalmente nuevas basadas en otras frases que le demos como entrada.
En mi caso voy a usar las frases del presentador argentino afincado en España, Héctor del Mar, porque siempre me han parecido bastante graciosas y tiene unas cuantas.
 Héctor del Mar es el de la derecha. Para quien no le conozca, suele comentar los shows de la WWE
Héctor del Mar es el de la derecha. Para quien no le conozca, suele comentar los shows de la WWE
Las cadenas de Markov es un modelo probabilístico que impone que la probabilidad de que suceda algo solo depende del estado anterior. Aplicado a nuestro caso con palabras, la probabilidad de que una palabra sea la siguiente de la frase solo depende de la palabra anterior. Observemos este grafo:
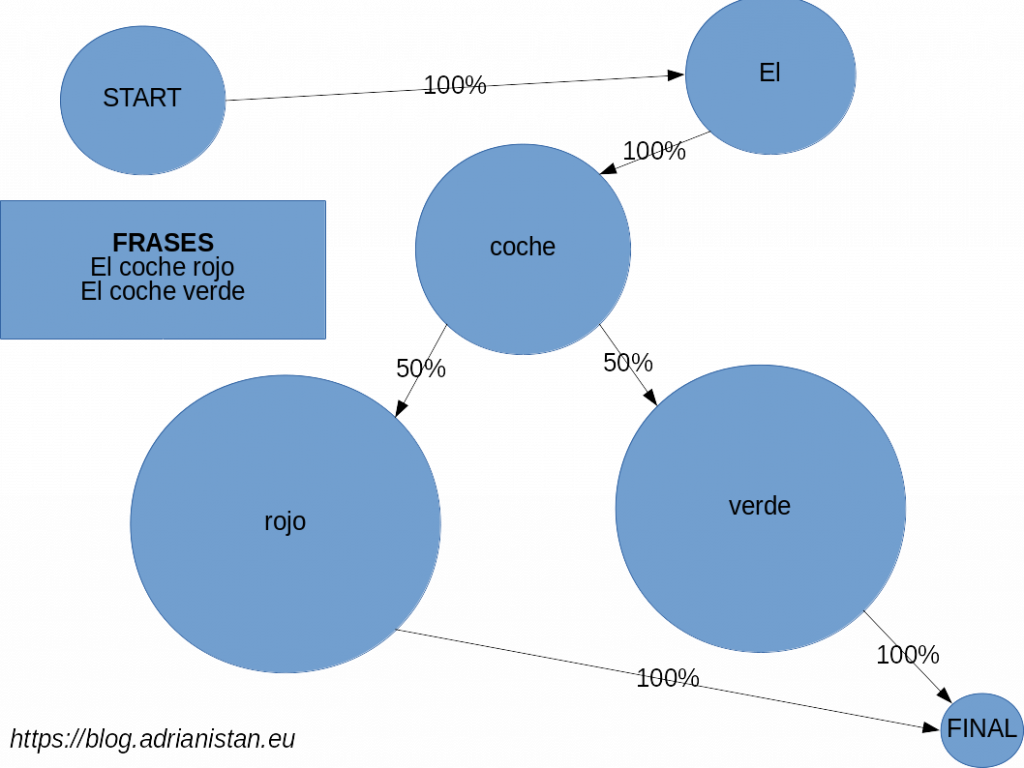 En él se han introducido dos frases: El coche rojo y El coche verde. La probabilidad de que coche sea la palabra que va después de El es del 100%, pero de que rojo sea la siguiente palabra después de coche es del 50%. Con este ejemplo, parece bastante limitado, pero la cosa cambia cuando metemos muchas frases y muchas palabras se repiten.
En él se han introducido dos frases: El coche rojo y El coche verde. La probabilidad de que coche sea la palabra que va después de El es del 100%, pero de que rojo sea la siguiente palabra después de coche es del 50%. Con este ejemplo, parece bastante limitado, pero la cosa cambia cuando metemos muchas frases y muchas palabras se repiten.
Para este ejemplo no obstante, usaré las dos últimas palabras como estado anterior, ya que suele dar resultados mucho más legibles (aunque pueden darse con más probabilidad frases que ya existen).
El primer paso será tener las frases en un formato óptimo. Para ello usaré requests y BeautifulSoup4. Las frases las voy a sacar de Wikiquote.
Ahora hay que generar el grafo de Markov. Para ello vamos a usar un diccionario, donde en la clave tendremos el estado anterior, es decir, las dos últimas palabras (en forma de tupla). El contenido será una lista con todas las palabras a las que puede saltar. Al ser una lista, puede haber palabras repetidas, lo que efectivamente hará aumentar su probabilidad.
Aprovechando Python, voy a usar un defaultdict para simplificar el código, ya que con él me voy a asegurar de que todos los accesos al diccionario me van a devolver una lista.
Ahora viene el último paso, generrar una frase nueva. Para ello, empezamos con el estado START,START y seguimos el grafo hasta que acabemos. Para elegir la siguiente palabra de la lista usamos random.choice. La frase que se va generando se queda en una lista hasta que finalmente devolvemos un string completo.
Veamos los resultados:
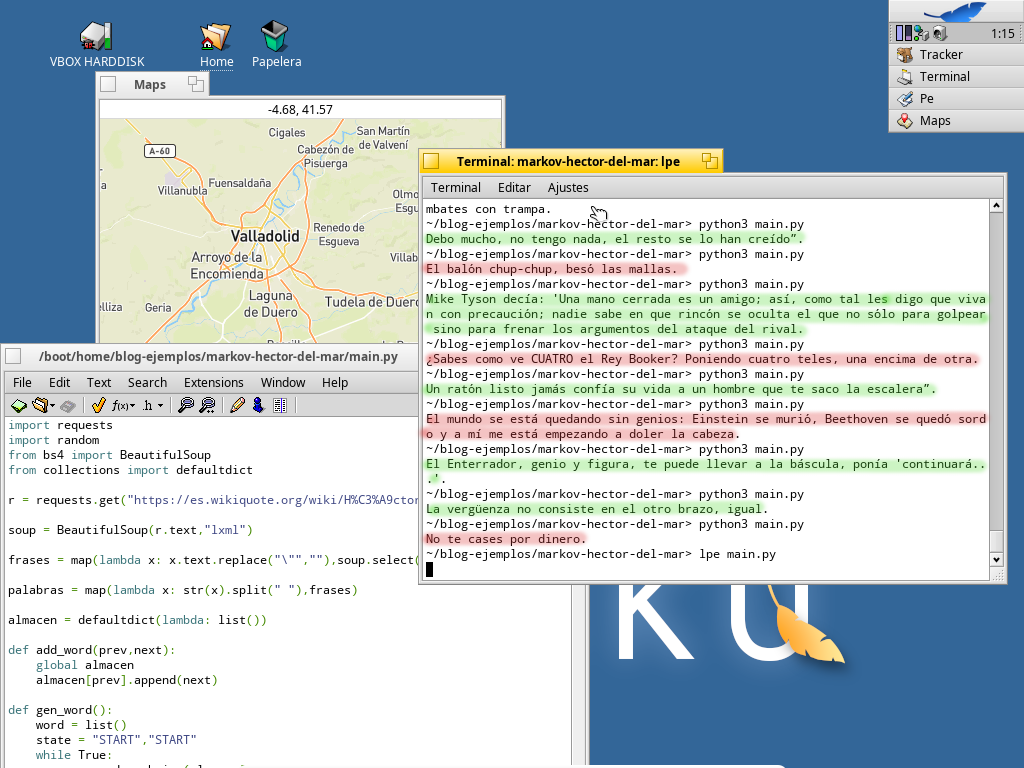 Las frases en rojo son frases que dijo de verdad. Las frases en verde son frases generadas por este machine learning. La tasa de frases nuevas no es muy elevada, pero son más del 50%. Y todas son bastante divertidas.
Las frases en rojo son frases que dijo de verdad. Las frases en verde son frases generadas por este machine learning. La tasa de frases nuevas no es muy elevada, pero son más del 50%. Y todas son bastante divertidas.
El código fuente completo de Markov-HectorDelMar está en el repositorio Git del blog: https://github.com/aarroyoc/blog-ejemplos/tree/master/markov-hector-del-mar
Ahora que ya sabes usar cadenas de Markov, ¿por qué no meter como dato de entrada El Quijote?, ¿o los tuits de algún político famoso?, ¿o las entradas de este blog? Las posibilidades son infinitas.
Para despedirme, como diría el Héctor del Mar de verdad:
En mi caso voy a usar las frases del presentador argentino afincado en España, Héctor del Mar, porque siempre me han parecido bastante graciosas y tiene unas cuantas.
Héctor del Mar es el de la derecha. Para quien no le conozca, suele comentar los shows de la WWE¿Qué son las cadenas de Markov?
Las cadenas de Markov es un modelo probabilístico que impone que la probabilidad de que suceda algo solo depende del estado anterior. Aplicado a nuestro caso con palabras, la probabilidad de que una palabra sea la siguiente de la frase solo depende de la palabra anterior. Observemos este grafo:
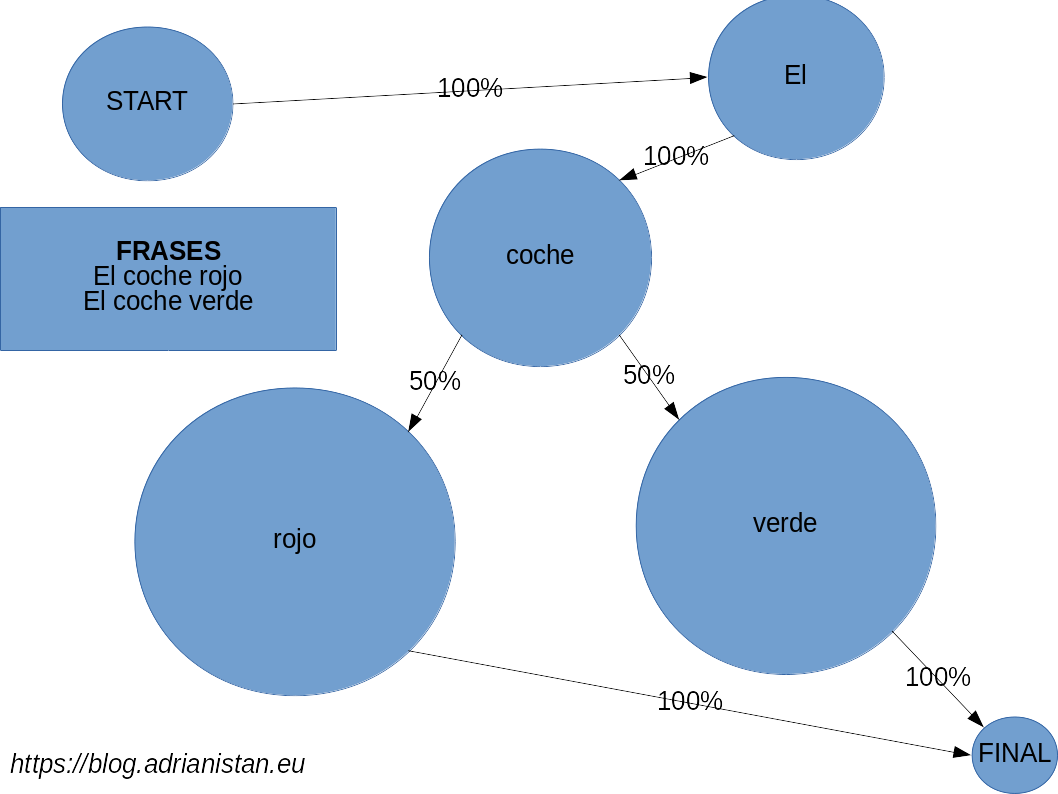 En él se han introducido dos frases: El coche rojo y El coche verde. La probabilidad de que coche sea la palabra que va después de El es del 100%, pero de que rojo sea la siguiente palabra después de coche es del 50%. Con este ejemplo, parece bastante limitado, pero la cosa cambia cuando metemos muchas frases y muchas palabras se repiten.
En él se han introducido dos frases: El coche rojo y El coche verde. La probabilidad de que coche sea la palabra que va después de El es del 100%, pero de que rojo sea la siguiente palabra después de coche es del 50%. Con este ejemplo, parece bastante limitado, pero la cosa cambia cuando metemos muchas frases y muchas palabras se repiten.Para este ejemplo no obstante, usaré las dos últimas palabras como estado anterior, ya que suele dar resultados mucho más legibles (aunque pueden darse con más probabilidad frases que ya existen).
Obteniendo los datos
El primer paso será tener las frases en un formato óptimo. Para ello usaré requests y BeautifulSoup4. Las frases las voy a sacar de Wikiquote.
from bs4 import BeautifulSoup
import requests
r = requests.get("https://es.wikiquote.org/wiki/H%C3%A9ctor_del_Mar")
soup = BeautifulSoup(r.text,"lxml")
frases = map(lambda x: x.text.replace("\"",""),soup.select(".mw-parser-output li"))
palabras = map(lambda x: str(x).split(" "),frases)
Generando el grafo de Markov
Ahora hay que generar el grafo de Markov. Para ello vamos a usar un diccionario, donde en la clave tendremos el estado anterior, es decir, las dos últimas palabras (en forma de tupla). El contenido será una lista con todas las palabras a las que puede saltar. Al ser una lista, puede haber palabras repetidas, lo que efectivamente hará aumentar su probabilidad.
Aprovechando Python, voy a usar un defaultdict para simplificar el código, ya que con él me voy a asegurar de que todos los accesos al diccionario me van a devolver una lista.
from collections import defaultdict
almacen = defaultdict(lambda: list())
def add_word(prev,next):
global almacen
almacen[prev].append(next)
for frase in palabras:
frase = list(frase)
for i,palabra in enumerate(frase):
if i == 0:
add_word(("START","START"),palabra)
continue
if i == 1:
add_word(("START",frase[0]),palabra)
continue
add_word((frase[i-2],frase[i-1]),palabra)
Generando una frase nueva
Ahora viene el último paso, generrar una frase nueva. Para ello, empezamos con el estado START,START y seguimos el grafo hasta que acabemos. Para elegir la siguiente palabra de la lista usamos random.choice. La frase que se va generando se queda en una lista hasta que finalmente devolvemos un string completo.
import random
def gen_word():
word = list()
state = "START","START"
while True:
w = random.choice(almacen[state])
word.append(w)
state = state[1],w
if w.endswith(".") or w.endswith("!"):
return " ".join(word)
Resultados
Veamos los resultados:
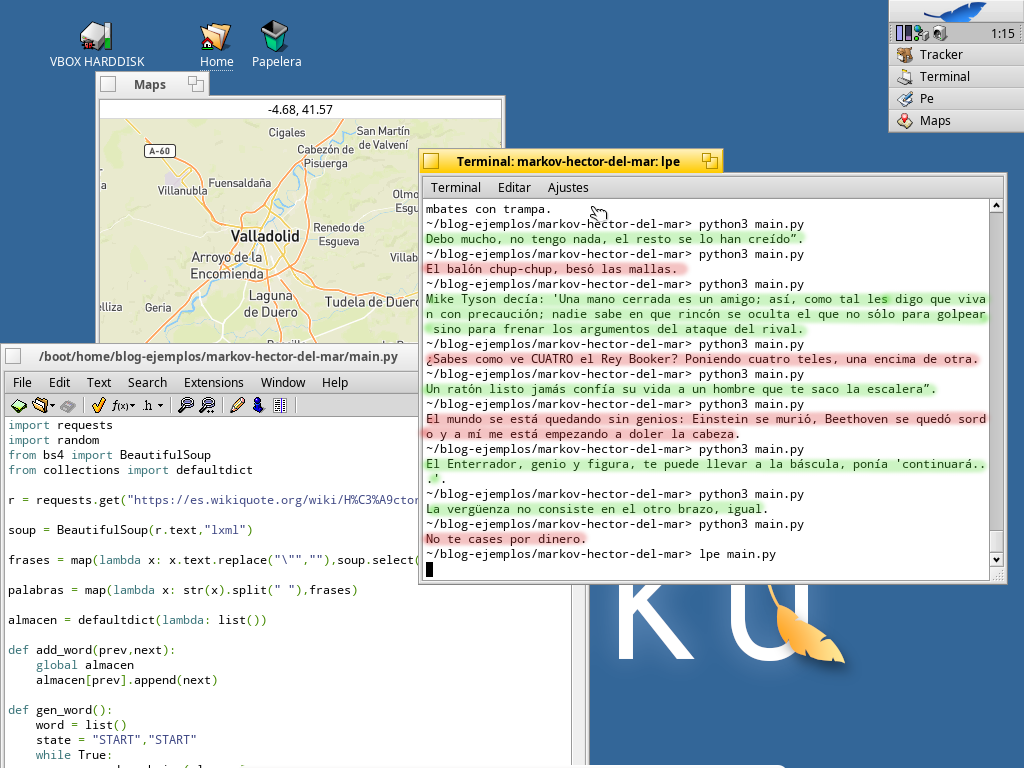 Las frases en rojo son frases que dijo de verdad. Las frases en verde son frases generadas por este machine learning. La tasa de frases nuevas no es muy elevada, pero son más del 50%. Y todas son bastante divertidas.
Las frases en rojo son frases que dijo de verdad. Las frases en verde son frases generadas por este machine learning. La tasa de frases nuevas no es muy elevada, pero son más del 50%. Y todas son bastante divertidas.El código fuente completo de Markov-HectorDelMar está en el repositorio Git del blog: https://github.com/aarroyoc/blog-ejemplos/tree/master/markov-hector-del-mar
Ahora que ya sabes usar cadenas de Markov, ¿por qué no meter como dato de entrada El Quijote?, ¿o los tuits de algún político famoso?, ¿o las entradas de este blog? Las posibilidades son infinitas.
Para despedirme, como diría el Héctor del Mar de verdad:
Aquí estoy porque he venido, porque he venido aquí estoy, si no le gusta mi canto, como he venido, me voy. ¡Nos vamos, don Fernando!