Crónica Neuronal: Indian Liver Patients Record
Otro día de verano y otro día de Crónica Neuronal. Hoy he elegido un dataset médico, se trata de Indian Liver Patients Record, o lo que es lo mismo, Registro de pacientes de hígado en la India. Las enfermedades relacionadas con el hígado han ido en aumento en los últimos años: el alcohol, la polución, la comida en mal estado, las drogas y los pepinillos son algunas de las causas de este aumento. En el dataset, originalmente de UCI y bajo licencia Creative Commons Zero, tenemos datos médicos de varias personas y si deben recibir tratamiento para el hígado o no. El objetivo es identificar, dado un paciente nuevo, si debería iniciar un tratamiento del hígado o si por el contrario, está sano.
Análisis de datos
Las variables o features del dataset son las siguientes:
- Age: edad de la persona
- Gender: sexo de la persona
- Total Bilirubin: bilirrubina total en el hígado en mg/dL. Es la suma de la bilirrubina directa y la indirecta
- Direct Bilirubin: bilirrubina directa en mg/dL.
- Alkaline Phosphotas: fosfatasa alcalina en IU/L
- Alanina aminotransferasa: enzima conocida también como transaminasa glutámico pirúvica, en IU/L
- Aspartate Aminotransferas: enzima conocida también como aspartato transaminasa, en IU/L
- Total Protiens: proteínas totales, en g/dL
- Albumin: albúmina, una proteína que se genera en la sangre, en g/dL
- Albumin and Globulin Ratio: ratio de albúmina por glóbulos en sangre
- Dataset: si necesitan tratamiento o no
Vamos a entrar más en detalle de las variables usando Seaborn.
import pandas as pd
import numpy as np
import seaborn as sns
data = pd.read_csv("indian_liver_patient.csv")
data.describe()
sns.countplot(data["Gender"])
sns.countplot(data["Dataset"])
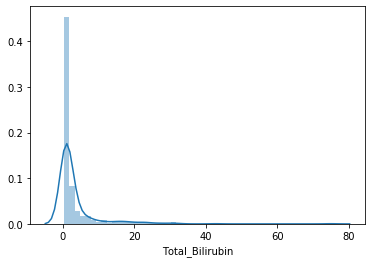
sns.distplot(data["Total_Bilirubin"])
Hay solo dos variables categórica en este dataset: la clase y Gender. La clase no hace falta transformarla, ya que ya son dos números. Vamos a analizar Gender, con countplot, que tendremos que transformar con OneHotEncoder:
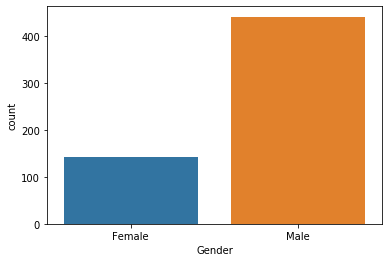
Tenemos muchísimos más datos de hombres que de mujeres. En una prediccón real haría falta tener más datos de mujeres. Puede ser que esto no influya o puede que sí (como en muchas enfermedades, un caso muy evidente, el cáncer de mama) o incluso puede que se deba factores culturales. Pero de cara a un diagnóstico deberíamos poder tener datos equilibrados.
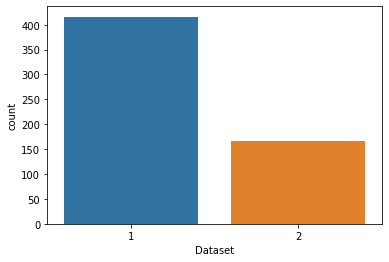
En el caso de la clase, también vemos que está desequilibrada, con muchos más datos de gente que debería recibir tratamiento (1) de los que no (2). A la hora de realizar el test del algoritmo deberemos estratificar, para asegurarnos que se incluye esta misma proporción en los conjuntos de entrenamiento reducidos.
Podemos analizar la distribución de alguna variable continua, con distplot, pero no he encontrado nada relevante aquí (parece obvio que hay un único valor mayoritario).
Usando jointplot en Seaborn podemos ver correlaciones variable a variable. Usando pairplot, podemos ver todas de golpe.
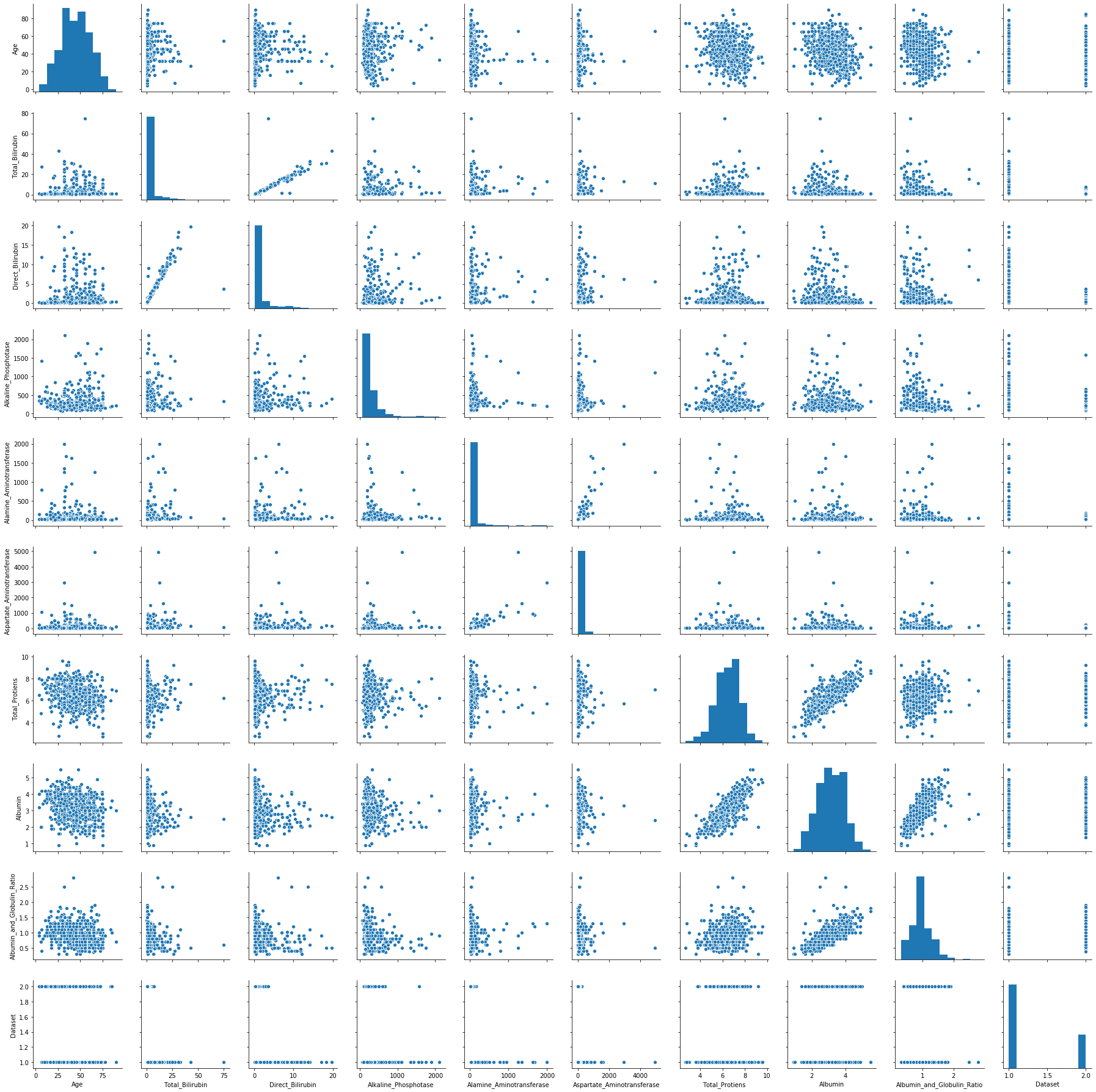
Así a priori no observo valores demasiado extraños, así que de momento, mantendremos todos los valores.
Analizando los datos compruebo que existen 4 valores no existentes en la columna Albumin_and_Globulin_Ratio. Procedo a rellenarlos con una media de valores. Hacemos el OneHotEncoding:
data.isna().sum()
data["Albumin_and_Globulin_Ratio"] = data["Albumin_and_Globulin_Ratio"].fillna(data["Albumin_and_Globulin_Ratio"].mean())
data = pd.get_dummies(data)
X = data.drop(columns=["Dataset"])
Y = data["Dataset"]
A continuación, probamos diferentes algoritmos de la familia de árboles: DecisionTree y RandomForest. Probé el criterio de entropía (ID3, C4.5 y similares) y el de Gini. Y Gini era más estable, así que es mi elección.
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = train_test_split(X,Y,test_size=1/3,stratify=Y,random_state=0)
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(criterion="gini", max_depth=3, min_samples_split=4, max_features=4)
tree.fit(train_x, train_y)
predict_y = tree.predict(test_x)
np.sum(predict_y == test_y)/test_y.shape[0]
from sklearn.ensemble import RandomForestClassifier
tree = RandomForestClassifier(criterion="gini", max_depth=None, min_samples_split=4, max_features=4, n_estimators=100)
tree.fit(train_x, train_y)
predict_y = tree.predict(test_x)
np.sum(predict_y == test_y)/test_y.shape[0]
Con DecisionTreeClassifier y el criterio de Gini, lo tuneé con max_depth=3, min_samples_split=4 y max_features=4. Todo ello para que no haga sobreajuste, típico en árboles. Este max_features es interesante. Podríamos haberlo hecho antes, pero con los árboles da igual. Básicamente si dos variables están muy correlacionadas, aportan prácticamente la misma información, serán ignoradas en la construcción del modelo, reduciendo el sobreajuste. El resultado es un 70% de acierto.
Con RandomForest he conservado los ajustes de max_features y de min_samples_split pero he desactivado la profundidad máxima. Consistentemente se obtiene un 73-74% de acierto.
Por último, para XGBoost, que era la primera vez que lo usaba, le metí en un bucle que va modificando valores, probando muchas configuraciones posibles. Esto llevó un rato, pero consiguió una configuració
import xgboost as xgb
res = dict()
for d in range(1,10):
for l in range(1,9):
for m in range(1,5):
for g in range(0,10):
tree = xgb.XGBClassifier(max_depth=d, learning_rate=l/100, n_estimators=100, objective="binary:logistic", booster="gbtree", n_jobs=4, min_child_weight=m, gamma=g/10)
tree.fit(train_x, train_y)
predict_y = tree.predict(test_x)
res[(d,l,m,g)] = np.sum(predict_y == test_y)/test_y.shape[0]
print(res[(d,l,m,g)])
max(res, key=res.get)
El valor óptimo fue profundidad máxima de 7, learning_rate de 0.08, min_child_weight de 3 y gamma de 0.3. Estos valores fueron lo mejor que pude encontrar para este holdout específico. Pero al cambiar el random_state del Holdout, estos aciertos se desmoronaron hasta llegar al 64%. Los parámetros no son buenos, simplemente había coincidido que iban muy bien. Con esta tragedia, es un buen momento para recordar uno de los métodos alternativos a Holdout: validación cruzada, que sin duda usaré en otro dataset de otra Crónica Neuronal.
Conclusión
Hemos obtenido fácilmente modelos con más del 70% de acierto de forma consistente, con RandomForest y xgboost. Probé también K-Vecinos, con resultados parecidos pero más lento y el perceptrón multicapa, sin poder igualar resultados. Espero que este dataset os haya gustado, espero vuestros aportes en los comentarios.