Crónica Neuronal: House Prices
Bienvenidos a una sección del blog titulada Crónica Neuronal. En esta sección resolveremos problemas reales de Inteligencia Artificial de forma práctica. La estructura es la siguiente. Yo presento un problema, muchas veces sacado de Kaggle, SpainML u otro sitio y voy contando como lo voy resolviendo, escribiendo paso a paso mis pensamientos en cada momento. De hecho, yo no he resuelto estos problemas, sino que los voy resolviendo sobre la marcha mientras escribo la crónica. A los problemas les dedico un tiempo limitado y puede ser posible (como en este caso) que no llegue a resultados satisfactorios.
House Prices
Este primer problema ha sido creado por Kaggle, forma parte de la categoría de problemas para principiantes. El problema consiste en predecir el valor de venta real (es decir, por el que se ejecuta una compra-venta) de casas de Ames, Iowa. Para ello disponemos de un historial de compra-ventas en la zona de Ames, con gran cantidad de detalles:
- MSSubClass: Tipo de edificio
- MSZoning: Clasificación de la zona
- LotFrontage: Linear feet of street connected to property
- LotArea: Lot size in square feet
- Street: Tipo de acceso por carretera
- Alley: Tipo de acceso por callejón
- LotShape: Forma de la propiedad
- LandContour: Rugosidad de la propiedad
- Utilities: Tipo de utilidades disponibles
- LotConfig: Configuración de la parcela
- LandSlope: Inclinación de la parcela
- Neighborhood: Barroi
- Condition1: Proximidad a carretera principal o ferrocarril
- Condition2: Proximidad a carretera principal o ferrocarril (si hubiese un segundo)
- BldgType: Tipo de vivienda
- HouseStyle: Estilo de la vivienda
- OverallQual: Calidad de materiales y construcción
- OverallCond: Calidad de la casa en general
- YearBuilt: Fecha original de construcción
- YearRemodAdd: Fecha de remodelación
- RoofStyle: Tipo de techo
- RoofMatl: Material del techo
- Exterior1st: Material del exterior de la casa
- Exterior2nd: Material del exterior de la casa
- MasVnrType: Recubrimiento exterior decorativo
- MasVnrArea: Área del recubrimiento exterior decorativo
- ExterQual: Calidad del material exterior
- ExterCond: Condiciones actuales del material exterior
- Foundation: Tipo de pilares
- BsmtQual: Altura del sótano
- BsmtCond: Condiciones del sótano
- BsmtExposure: Exposición del sótano al exterior
- BsmtFinType1: Calidad del primer área acabada del sótano
- BsmtFinSF1: Tipo del primer área acabada
- BsmtFinType2: Calidad del segundo área acabada del sótano
- BsmtFinSF2: Tipo del segundo área acabada
- BsmtUnfSF: Área sin acabar del sótano
- TotalBsmtSF: Área del sótano
- Heating: Tipo de calefacción
- HeatingQC: Calidad de la calefacción
- CentralAir: Sistema de aire acondicionado centralizado
- Electrical: Sistema eléctrico
- 1stFlrSF: Área primera planta
- 2ndFlrSF: Área segunda planta
- LowQualFinSF: Área finalizada de baja calidad
- GrLivArea: Área habitable sobre el suelo
- BsmtFullBath: Sótano con baño completo
- BsmtHalfBath: Sótano con baño incompleto
- FullBath: Baños completos sobre el suelo
- HalfBath: Baños incompletos sobre el suelo
- Bedroom: Dormitorios sobre el suelo
- Kitchen: Cocinas
- KitchenQual: Calidad cocinas
- TotRmsAbvGrd: Habitaciones sobre el suelo (sin baños)
- Functional: Rating de funcionalidad
- Fireplaces: Número de chimeneas
- FireplaceQu: Calidad chimeneas
- GarageType: Tipo garaje
- GarageYrBlt: Año del garaje
- GarageFinish: Calidad interior del garaje
- GarageCars: Número de coches en el garaje
- GarageArea: Área del garaje
- GarageQual: Calidad del garaje
- GarageCond: Condiciones actuales del garaje
- PavedDrive: Entrada al garaje asfaltada
- WoodDeckSF: Área exterior recubierta de madera
- OpenPorchSF: Área de porche abierto
- EnclosedPorch: Área de porche cerrado
- 3SsnPorch: Área de porche tres-estaciones
- ScreenPorch: Área de porche pantalla
- PoolArea: Área de la piscina
- PoolQC: Calidad de la piscina
- Fence: Calidad de la valla
- MiscFeature: Miscelánea
- MiscVal: Valor de la miscelánea
- MoSold: Mes de venta
- YrSold: Año de venta
- SaleType: Tipo de venta
- SaleCondition: Condición de la venta
Como vemos, el número de variables es enorme. Hay que tener en cuenta que muchas propiedades pueden no influir o influir de forma poco significativa. En caso de detectarlo puede ser convenientes eliminarlas, ya que pueden añadir ruido innecesario.
Se trata de un problema de regresión, ya que se nos pide predecir un valor numérico dentro de un continuo (los precios, a efectos prácticos son continuos) y un infinito. Esto se opone a los problemas de clasificación, donde intentamos predecir algo dentro de una lista de posibles valores.
Cargando datos y Holdout
Vamos a empezar abriendo Jupyter y cargando los datos en formato CSV con Pandas. Si leemos el CSV vemos que tiene una columna extra llamada, Id. Vamos a eliminarla, ya que esta columna única para cada instancia nos provocaría sobreajuste.
Además, vamos a preparar un sistema de prueba. Me decanto por el método Holdout con 2/3-1/3. Esto es que nuestros datos de entrenamiento y de test son 2/3 y 1/3 del total respectivamente. Cuando tengamos un buen algoritmo, podremos usar todos los datos para la clasificación en Kaggle. De momento vamos a eliminar además las variables para las que existan valores desconocidos con dropna.
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
data_csv = pd.read_csv("train.csv")
data = data_csv.drop(columns=["Id"])
data.dropna(axis="columns", inplace=True)
data = pd.get_dummies(data)
x = data.drop(columns=["SalePrice"])
y = data["SalePrice"]
train_x, test_x, train_y, test_y = train_test_split(x, y, test_size=1/3)
Árboles de decisión
Siempre es recomendable probar los conjuntos de datos con algoritmos sencillos de aprendizaje automático. Los árboles de decisión son rápidos y pueden ofrecernos información sobre el conjunto de datos muy interesante. En mi caso voy a usar DecisionTreeRegressor perteneciente a sklearn. No obstante, este módulo no admite variables categóricas. Para ello podemos usar LabelEncoder o OneHotEncoder también de sklearn y poder realizar una transformación. ¿Cuál usar? La teoría dicta que LabelEncoder cuando las categorías tienen un orden y OneHotEncoder cuando no tiene sentido. Como en muchas propiedades no sabemos si es intrínsecamente mejor Ladrillo o Piedra, usaremos OneHotEncoder por defecto. En este caso no voy a usar sklearn, sino el método de Pandas get_dummies. Además creo que no va a hacer falta normalizar los datos, así que nos saltamos este paso.
from sklearn.tree import DecisionTreeRegressor
tree = DecisionTreeRegressor(criterion="mse", splitter="best", max_depth=None, min_samples_split=10, min_samples_leaf=5)
tree.fit(train_x, train_y)
predict_y = tree.predict(test_x)
1 - np.sum(abs(predict_y - test_y) < 0.1*test_y)/test_y.shape[0]
Por último, para evaluar los datos elegimos que una diferencia del 10% entre el valor real y el valor predicho nos vale. Este árbol de decisión, tiene un criterio MSE, no tiene altura máxima pero a cambio le he puesto que el tamaño de las hojas sea mínimo de 5 (es decir, una ramificación final solo lo puede ser si al menos 5 instancias de entrenamiento caen en ella) y un número de split de 10 (para crear una rama hace falta por lo menos 10 ejemplos). Los resultados son bastante mediocres: una tasa de error del 50%. Pero está suficientemente bien, como para hacer una entrega de prueba en Kaggle.
Realizando las predicciones
Aquí me encontré con un problema. Los datos de test tenían iferentes datos que los de entrenamiento y el OneHotEncoding con get_dummies fallaba. La solución que utilicé es cargar los datos de entrenamiento y test en un mismo DataFrame de Pandas, hacer el get_dummies y después volverlos a separar. Después de realizar esto tenemos que volver a entrenar el modelo con todos los datos posibles y realizar la predicción y guardarla en el CSV. El código completo es el siguiente:
import pandas as pd
import numpy as np
data_csv = pd.read_csv("train.csv")
test_csv = pd.read_csv("test.csv")
size = test_csv.shape
all_data = pd.concat((test_csv,data_csv),sort=False)
all_data.dropna(axis="columns",inplace=True)
all_data = pd.get_dummies(all_data,drop_first=True)
test = all_data[0:size[0]]
data = all_data[size[0]:]
x = data
y = data_csv["SalePrice"]
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = train_test_split(x,y,test_size=1/3)
# ARBOLES DE DECISION
from sklearn.tree import DecisionTreeRegressor
tree = DecisionTreeRegressor(criterion="mse",splitter="best",max_depth=None,min_samples_split=10,min_samples_leaf=5)
tree.fit(train_x,train_y)
predict_y = tree.predict(test_x)
1 - np.sum(abs(predict_y - test_y) < 0.1*test_y)/test_y.shape[0]
# PREDECIR
tree.fit(x,y)
test_out = tree.predict(test)
out = pd.DataFrame({"Id" : test_id, "SalePrice" : test_out})
out.to_csv("out.csv",index=False)
El fichero out.csv lo podemos subir a Kaggle.
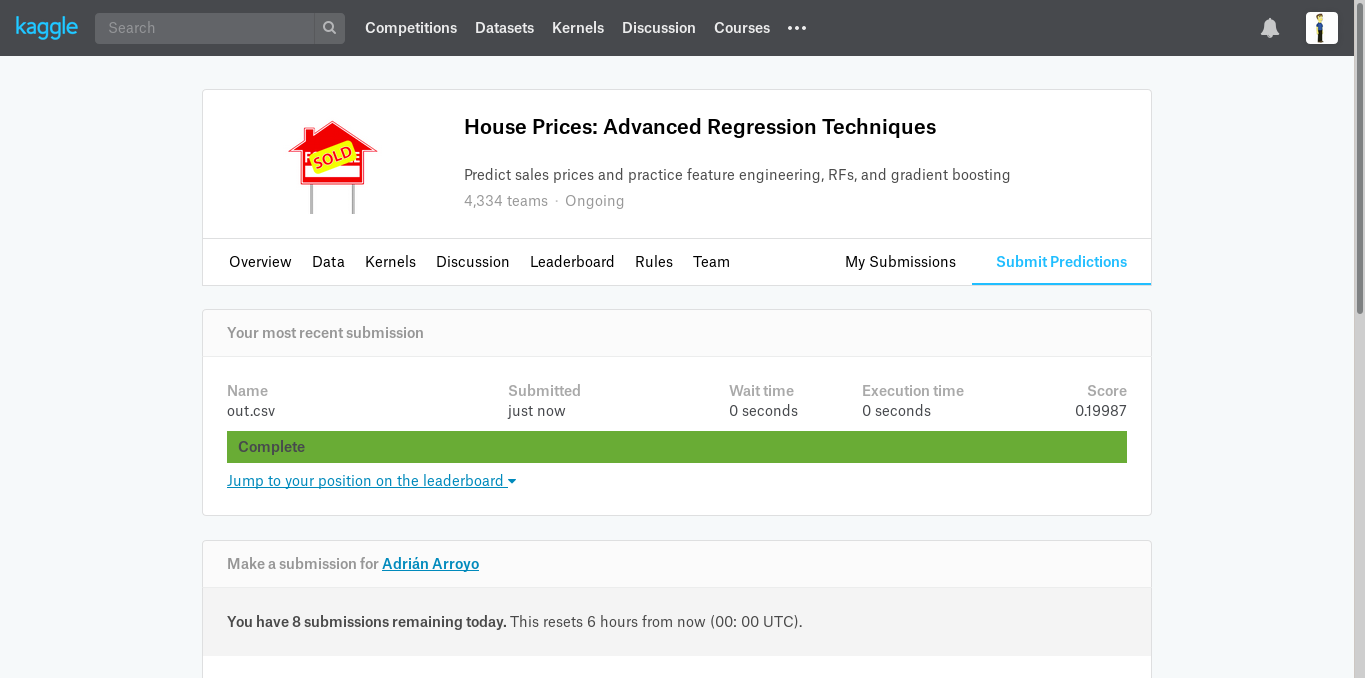
El resultado es mejor de lo esperado, quizá Kaggle usa un interavalo de admisión más alto que el mío. Igualmente, lo voy a dejar en el 10%
K-Vecinos
Voy a probar el algoritmo de K-Vecinos. No tengo muchas esperanzas en él, pero la interfaz de programación en sklearn es muy parecida a la los árboles de decisión.
from sklearn.neighbors import KNeighborsRegressor
knr = KNeighborsRegressor(n_neighbors=5,p=2,metric="minkowski")
knr.fit(train_x,train_y)
predict_y = knr.predict(test_x)
1 - np.sum(abs(predict_y - test_y) < 0.1*test_y)/test_y.shape[0]
Y efectivamente, el resultado es horrible. K-Vecinos tiene una tasa de error del 60%. No creo que merezca la pena insistir mucho en este algoritmo. Lo he configurado con distancia de Minkowski y P=2 (lo que equivale a la distancia euclídea).
Regresión Lineal
La regresión lineal en cambio sí que creo que puede ser interesante probarla.
from sklearn.linear_model import LinearRegression
reg = LinearRegression()
reg.fit(train_x,train_y)
predict_y = reg.predict(test_x)
1 - np.sum(abs(predict_y - test_y) < 0.1*test_y)/test_y.shape[0]
Los resultados son los mejores hasta ahora: 43%. Pero podría ser mejor. Decido probar con máquinas de vector soporte.
SVM
Si la regresión lineal ha obtenido los mejores resultados, con una SVM seríamos capaces de llegar a ese mismo valor y posiblemente mejorarlo. Sin embargo, con un SVR lineal no pude llegar a replicarlo
from sklearn.svm import SVR
svr = SVR(kernel="linear", max_iter=-1)
svr.fit(train_x,train_y)
predict_y = svr.predict(test_x)
1 - np.sum(abs(predict_y - test_y) < 0.1*test_y)/test_y.shape[0]
Y conseguí un mísero 51% de error. Y este era el kernel que mejor funcionaba, el lineal. Probé poly con diferentes grados, rbf y sigmoid y todos ellos daban un resultado peor. Es hora de sacar la maquinaria pesada y entrar a tope con redes neuronales.
Perceptrón multicapa
He decidido saltarme directamente el Adaline y otros modelos más simples ya que no creo que mejoren la regresión lineal. Al perceptrón multicapa al principio le quise dar un gran número de neuronas (150 al principio) en una capa oculta, con una función de activación RELU y un solver de tipo ADAM. Como el resultado era muy parecido al de la SVM. Empecé a hacer cambios. LBFGS es bueno en datasets pequeños y efectivamente, los resultados mejoraron. Modifiqué a geometría de la red. Con 3 capas de 100 y RELU empecé a obtener resultados mucho mejores que con cualquier método, pero muy sensibles a variaciones aleatorias.
Aquí apliqué normalización con StandardScaler, pero no cambió demasiado el resultado.
# Perceptron Multicapa
from sklearn.neural_network import MLPRegressor
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_x)
train_x_ss = ss.transform(train_x)
test_x_ss = ss.transform(test_x)
mlp = MLPRegressor(hidden_layer_sizes=(100,100,100),activation="relu",solver="lbfgs",max_iter=50000)
mlp.fit(train_x_ss, train_y)
predict_y = mlp.predict(test_x_ss)
1 - np.sum(abs(predict_y - test_y) < 0.1*test_y)/test_y.shape[0]
Segundo test
Vuelvo a subir a Kaggle. Esta vez obtengo una tasa de error de 0.17975. Ha mejorado, pero bastante poco.
Random Forest
Los árboles parecieron ir bien, pruebo los Random Forest, con buenos resultados. Tasa de error en local del 39% y 0.17223 en Kaggle. No obstante, en Kaggle parezco haberme quedado estancado.
from sklearn.ensemble import RandomForestRegressor
rand = RandomForestRegressor()
rand.fit(train_x,train_y)
predict_y = rand.predict(test_x)
1 - np.sum(abs(predict_y - test_y) < 0.1*test_y)/test_y.shape[0]
Limpiando datos
Aquí empecé a buscar ayuda en Internet. Algo que no había realizado y que es muy interesante, es limpiar los datos. Eliminar algunas columnas específicamente y rellenar otras con valores faltantes con otros valores. Volví a ejecutar el Random Forest obteniendo un 38% en local pero un 0.14754 en Kaggle.
Conclusión
No he conseguido mi objetivo de llegar al top 25% de Kaggle. Todavía me quedan muchas cosas por aprender. Para próximos problemas debo realizar un análisis exploratorio de los datos más avanzado (aquí casi no lo he realizado) y debo entender otras técnicas de regresión (he de decir que prefiero problemas de clasificación a día de hoy). ¿Vosotros tenéis alguna idea de como mejorar los resultados, os escucho en los comentarios? Además, os dejo el código final.
import pandas as pd
import numpy as np
data_csv = pd.read_csv("train.csv")
test_csv = pd.read_csv("test.csv")
test_id = test_csv["Id"]
size = test_csv.shape
all_data = pd.concat((test_csv,data_csv),sort=False)
all_data.drop(['SalePrice','Utilities', 'RoofMatl', 'MasVnrArea', 'BsmtFinSF1', 'BsmtFinSF2', 'BsmtUnfSF', 'Heating', 'LowQualFinSF',
'BsmtFullBath', 'BsmtHalfBath', 'Functional', 'GarageYrBlt', 'GarageArea', 'GarageCond', 'WoodDeckSF',
'OpenPorchSF', 'EnclosedPorch', '3SsnPorch', 'ScreenPorch', 'PoolArea', 'PoolQC', 'Fence', 'MiscFeature', 'MiscVal'],
axis=1, inplace=True)
all_data['MSSubClass'] = all_data['MSSubClass'].astype(str)
all_data['MSZoning'] = all_data['MSZoning'].fillna(all_data['MSZoning'].mode()[0])
all_data['LotFrontage'] = all_data['LotFrontage'].fillna(all_data['LotFrontage'].mean())
all_data['Alley'] = all_data['Alley'].fillna('NOACCESS')
all_data.OverallCond = all_data.OverallCond.astype(str)
all_data['MasVnrType'] = all_data['MasVnrType'].fillna(all_data['MasVnrType'].mode()[0])
for col in ('BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2'):
all_data[col] = all_data[col].fillna('NoBSMT')
all_data['TotalBsmtSF'] = all_data['TotalBsmtSF'].fillna(0)
all_data['Electrical'] = all_data['Electrical'].fillna(all_data['Electrical'].mode()[0])
all_data['KitchenAbvGr'] = all_data['KitchenAbvGr'].astype(str)
all_data['KitchenQual'] = all_data['KitchenQual'].fillna(all_data['KitchenQual'].mode()[0])
all_data['FireplaceQu'] = all_data['FireplaceQu'].fillna('NoFP')
for col in ('GarageType', 'GarageFinish', 'GarageQual'):
all_data[col] = all_data[col].fillna('NoGRG')
means 0
all_data['GarageCars'] = all_data['GarageCars'].fillna(0.0)
popular values
all_data['SaleType'] = all_data['SaleType'].fillna(all_data['SaleType'].mode()[0])
all_data['YrSold'] = all_data['YrSold'].astype(str)
all_data['MoSold'] = all_data['MoSold'].astype(str)
all_data
all_data['TotalSF'] = all_data['TotalBsmtSF'] + all_data['1stFlrSF'] + all_data['2ndFlrSF']
all_data.drop(['TotalBsmtSF', '1stFlrSF', '2ndFlrSF'], axis=1, inplace=True)
all_data = pd.get_dummies(all_data,drop_first=True)
test = all_data[0:size[0]]
data = all_data[size[0]:]
x = data
y = data_csv["SalePrice"]
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, OneHotEncoder, LabelBinarizer
train_x, test_x, train_y, test_y = train_test_split(x,y,test_size=1/3)
# ARBOLES DE DECISION
from sklearn.tree import DecisionTreeRegressor
tree = DecisionTreeRegressor(criterion="mse",splitter="best",max_depth=None,min_samples_split=10,min_samples_leaf=5)
tree.fit(train_x,train_y)
predict_y = tree.predict(test_x)
1-np.sum(abs(predict_y - test_y) < 0.1*test_y)/test_y.shape[0]
# K-MEDIAS
from sklearn.neighbors import KNeighborsRegressor
knr = KNeighborsRegressor(n_neighbors=7,p=1,metric="minkowski")
knr.fit(train_x,train_y)
predict_y = knr.predict(test_x)
1- np.sum(abs(predict_y - test_y) < 0.1*test_y)/test_y.shape[0]
# Regresion Lineal
from sklearn.linear_model import LinearRegression
reg = LinearRegression()
reg.fit(train_x,train_y)
predict_y = reg.predict(test_x)
1 - np.sum(abs(predict_y - test_y) < 0.1*test_y)/test_y.shape[0]
# SVM
from sklearn.svm import SVR
from sklearn.preprocessing import MinMaxScaler
svr = SVR(kernel="linear", degree=3, gamma="scale", max_iter=-1)
svr.fit(train_x,train_y)
predict_y = svr.predict(test_x)
1 - np.sum(abs(predict_y - test_y) < 0.1*test_y)/test_y.shape[0]
# Perceptron Multicapa
from sklearn.neural_network import MLPRegressor
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_x)
train_x_ss = ss.transform(train_x)
test_x_ss = ss.transform(test_x)
mlp = MLPRegressor(hidden_layer_sizes=(100,100,100),activation="relu",solver="lbfgs",max_iter=50000)
mlp.fit(train_x_ss, train_y)
predict_y = mlp.predict(test_x_ss)
1 - np.sum(abs(predict_y - test_y) < 0.1*test_y)/test_y.shape[0]
# Random Forest
from sklearn.ensemble import RandomForestRegressor
rand = RandomForestRegressor(n_estimators=100)
rand.fit(train_x,train_y)
predict_y = rand.predict(test_x)
1 - np.sum(abs(predict_y - test_y) < 0.1*test_y)/test_y.shape[0]
# PREDECIR
rand.fit(x,y)
test_out = rand.predict(test)
out = pd.DataFrame({"Id" : test_id, "SalePrice" : test_out})
out.to_csv("out.csv",index=False)