Cosas que (probablemente) no sabías de Python
Python es un lenguaje muy popular hoy en día. Aunque pueda no ser el mejor, su desempeño es bueno, con mucha documentación, librerías, es cómodo y fácil de aprender. Python además sigue la filosofía de baterías incluidas, es decir, de intentar llevar de serie casi todo lo que vayas a poder necesitar. En este artículo vamos a ver algunas partes de Python no tan conocidas pero igualmente interesantes y útiles.
Frozensets y sets
Los sets y frozenset son estructuras de datos que replican el funcionamiento de los conjuntos de matemáticas. Esto quiere decir que es un contenedor de elementos, donde cada elemento solo puede aparecer una vez y no hay orden establecido entre los elementos. Los sets/frozensets tienen varias operaciones: unión, intersección, diferencia, diferencia simétrica y se puede comprobar si un conjunto es disjunto, subconjunto o superconjunto respecto a otro. La diferencia fundamental entre entre set y frozenset es que frozenset es inmutable, lo cuál puede ser mejor según nuestro problema (mejor estilo de programación y más rendimiento) pero es que además es hasheable, lo que significa que podemos usarlo en sitios donde se requiera que exista un hash, como por ejemplo, las claves de un diccionario.
a = set([27,53])
b = frozenset([27,42])
c = a | b # Unión
d = a & b # Intersección
e = a ^ b # Diferencia simétrica
f = a - b # Diferencia
print(c)
print(d)
print(e)
print(f)
if 42 in b:
print("42 dentro de B")
if a >= b:
print("A es superconjunto y B es subconjunto")
x = dict()
x[b] = 43
# x[a] = 43 daría error
Los sets además soportan set comprehensions:
a = { x for x in range(1,10)}
Statistics
Desde Python 3.4 existe un módulo llamado statistics que nos trae operaciones básicas de estadística ya implementadas. Evidentemente si vamos a hacer un uso intensivo, es mejor recurrir a las funciones de NumPy/SciPy pero en muchas ocasiones no necesitamos tanta potencia y este módulo nos viene de perlas. El módulo implementa funciones de media aritmética, media armónica, mediana, moda, varianza poblacional y varianza muestral (con sus respectivas desviaciones). Todas las funciones admiten los tipos int, float, Decimal y Fraction.
import statistics
data = [1,2,2,2,3,3,4,5,8]
a = statistics.mean(data)
b = statistics.median(data)
c = statistics.mode(data)
d = statistics.pvariance(data)
e = statistics.variance(data)
print(a)
print(b)
print(c)
print(d)
print(e)
Decimal y Fraction
Estos dos tipos sirven para representar números, pero son diferentes entre sí y también a int y float. En primer lugar veamos por qué son necesarios. En Python existe int para números enteros y float para números con parte decimal. Sin embargo, los float no son precisos. Los floats en Python son similares a los de C y usan el estándar IEEE 754. Esto está bien porque el hardware funciona así y es rápido, pero es imposible hacer cuentas de forma precisa e incluso representar algunos números es imposible. Para ello existen Decimal y Fraction que son dos maneras diferentes de conseguir precisión.
Decimal usa una precisión arbitraria para representar el número decimal como un número entero (por defecto con 28 posiciones). Decimal está especialmente recomendado para operaciones financieras, donde la precisión se conoce a priori. Fraction por otra parte usa el principio de que cualquier número racional se puede representar con una división de números enteros. Por tanto, almacena dos números, un numerador y un denominador, y los mantiene separados. Al hacer operaciones, como en cualquier otra fracción, se operan los números por separado, siempre manteniendo que tanto numerador como denominador sean enteros. De esta forma, y teniendo en cuenta que int tiene precisión arbitraria en Python, podemos representar con gran precisión todos los números racionales. Ambos métodos tienen el inconveniente de ser más lentos que float y gastar más memoria, pero son más precisos.
En este ejemplo que pongo abajo, se hace tres veces la misma operación: 0.1+0.2 que tiene que dar 0.3. Como verás si ejecutas el código, solo las versiones hechas con Decimal y Fraction hacen la operación bien, mientras que float falla.
a = 0.1
b = 0.2
c = 0.3
if a+b == c:
print("Float: operación correcta")
from decimal import Decimal
pi = Decimal('3.14159')
a = Decimal('0.1')
b = Decimal('0.2')
c = Decimal('0.3')
if a+b == c:
print("Decimal: operación correcta")
from fractions import Fraction
a = Fraction(1,10)
b = Fraction(2,10)
c = Fraction(3,10)
if a+b == c:
print("Fracion: operación correcta")
F-Strings
Las f-strings fueron añadidas en Python 3.6 y son cadenas de texto que admiten formato de forma muy sencilla y flexible. Es la opción recomendada, sustituyendo al resto de otras formas de hacerlo (aunque siguen funcionando).
usuario = "Godofredo"
mensaje = f"El usuario {usuario} ha entrado al sistema"
print(mensaje)
Pathlib
En nuestro día a día es frecuenta trabajar con archivos en diferentes directorios. Pathlib (disponible desde Python 3.4) nos ayuda a manejar de forma sencilla rutas de forma multiplataforma. Pero aunque no necesitemos multiplataforma, las abtracciones de Pathlib son muy interesantes.
from pathlib import Path
root = Path('dev')
print(root)
# dev
path = root / 'pcc'
print(path.resolve())
# /home/aarroyoc/dev/pcc
Functools
El módulo functools es de los más interesantes de Python, sobre todo si vienes de la programación funcional, ya que nos permite manipular funciones. Quiero destacar tres funciones de este módulo: partial, lru_cache y reduce.
reduce nos permite reducir un iterable a un valor usando una función. Es una operación muy común en programación funcional y a partir de Python 3 hay que usarla a través de este modulo. Por ejemplo, podemos programar una función factorial de la siguiente forma:
from functools import reduce
def factorial(n):
def multiply(a,b):
return a*b
return reduce(multiply,range(1,n+1))
Otra función interesante es lru_cache, disponible a partir de Python 3.2, la cuál es una cache LRU (Last Recently Used) ya construida para nuestro uso y disfrute. Si no lo sabéis, las cachés LRU son un tipo de caché con un tamaño fijo donde el elemento que se elimina cuando falta espacio es el último en ser usado (es decir, leído o añadido a la caché). Las cachés LRU se usan en muchos sitios (como en las propias CPUs. Además, esta versión de Python dispone de tamaño infinito si se lo configuramos, lo cuál es muy interesante. La función se usa como decorador y compara los argumentos de llamada para ver si la función ya fue llamada con esos argumentos, y en ese caso devolver el valor calcualdo con anterioridad. Si no existe, lo calcula y lo almacena. Esto es lo que se llama memoización, una técnica muy usada en programación dinámica.
@lru_cache(maxsize=None)
def fib(n):
if n < 2:
return n
return fib(n-1) + fib(n-2)
Usar lru_cache en funciones recursiva aumentará el consumo de memoria, pero puede mejorar la velocidad significativamente si se llama muchas veces a una función con los mismos argumentos.
Por último, partial nos permite definir funciones parciales. ¿Asombroso eh? Si no has tocado programación funcional seguramente te parezca que no tiene sentido. Para que nos entendamos, una función parcial es una función que ya tiene algunos argumentos rellenados, pero otros no. No estamos hablando de argumentos por defecto, porque eso se define sobre la propia función, sino de una función que es una especialización de otra más genérica. Veamos un ejemplo, vamos a definir un nuevo print que no añada un salto de línea al final:
from functools import partial
printx = partial(print,end='')
printx("Hola amigos")
print(" de Adrianistán")
De este modo, printx se define como la función parcial de print con el argumento end ya configurado a caracter vacío en vez de '\n' que es que usa print por defecto.
Depuración
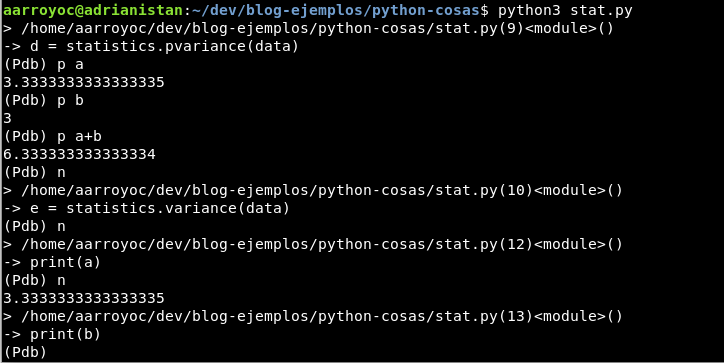
Si quieres depurar código Python, lo normal es usar pdb, el módulo con funciones de depuración. Sin embargo, su uso se hacía un poco farragoso, así que desde Python 3.7 se puede usar breakpoint. Simplemente llama a breakpoint (no hay que importar nada) y el programa entrará en modo depuración.
import statistics
data = [1,2,2,2,3,3,4,5,8]
a = statistics.mean(data)
b = statistics.median(data)
c = statistics.mode(data)
breakpoint()
d = statistics.pvariance(data)
e = statistics.variance(data)
print(a)
print(b)
print(c)
print(d)
print(e)
Otras funciones útiles de depuración son dir, vars, type y help. Dir muestra los atributos de un objeto o las variables locales, vars es similar pero más completa y difícil de leer. type devuelve el tipo de una variable y help muestra la documentación asociada a una clase o función.
Enums
En algunos lenguajes de programación existe un tipo llamado enum o enumeration, que suele ser un tipo que admite únicamente un conjunto finito de valores (normalmente pequeño y mapeadas a un número entero, pero con la seguridad del tipado extra). Python no disponía de esta funcionalidad (como muchos lenguajes de script) hasta Python 3.4, donde podemos crear clases que sean enumeraciones.
from enum import Enum, auto
class OperatingSystem(Enum):
LINUX = auto()
MACOSX = auto()
WINDOWSNT = auto()
HAIKU = auto()
SOLARIS = auto()
print(OperatingSystem.HAIKU)
Data classes
En la programación orientada a objetos es habitual a veces encontrarnos con clases donde la mayor parte de las líneas las perdemos en definir el constructor con datos, getters y setters. Las data classes, disponibles a partir de Python 3.7 nos permiten ahorrarnos todo este trabajo.
from dataclasses import dataclass
@dataclass
class PC:
cpu: str
freq: int
price: int = 1000
def discount(self):
return self.price*0.8
pc = PC("Intel Core i7",4000,2000)
print(pc.discount())
print(pc)
Tipado
Al usar data classes te habrás dado cuenta que hay que poner tipos. Esto se llama type hints y no son tipos como en otros lenguajes. Me explico. En Python existen tipos, pero no existe forma de forzar a que un argumento de una función sea de un tipo o de otro. Los type hints no son más que indicaciones que Python sabe como ignorar, el intérprete de Python no les hace caso. Son los IDEs, los linters como mypy y algunas librerías como pydantic los que en todo caso realizan la verificación de tipos. Los tipados tal y como se conocen ahora se añadieron en Python 3.5 y en el módulo typing hay muchos tipos avanzados.
from typing import Dict
Options = Dict[str,str]
def add_option(options: Options, key: str, content: str) -> None:
options[key] = content
a = dict()
add_option(a,"b","c")
Collections
El módulo collections tiene numerosas estructuras de datos más avanzadas para mayor comodidad o mejor rendimiento. Voy a comentar tres: defaultdict, Counter y deque.
defaultdict es una estructura de datos que particularmente encuentro muy interesante. Se trata de diccionarios con valor por defecto. Muy simple de entender y más útil de lo que parece. Por ejemplo, en una cuadrícula bidimensional de todo ceros salvo unos pocos elementos que queremos que sean uno. Luego al analizar si se nos pregunta por una coordenada siempre podremos devolver el valor del diccionario (sin realizar ninguna comprobación).
from collections import defaultdict
mapa = defaultdict(lambda: 0)
mapa[(0,0)] += 1
mapa[(15,67)] += 1
Counter es un contador, simple y llanamente, pero extremadamente cómodo y sorprendentemente útil. Existen dos formas básicas de crear un contador, una es pasando un iterable y Counter se encargará de ir contando todos los elementos y otra es pasar ya un diccionario de las cuentas hechas. Los contadores tienen operaciones especiales como la suma, la resta, la unión y la intersección de contadores.
from collections import Counter
c = Counter("Rodrigo Diaz de Vivar")
print(c)
d = Counter({"d": 6, "i": 8})
e = c + d
print(e)
Por último, deque es una lista doblemente enlazada. Esto puede ser mucho más interesante que list para ciertas operaciones. List es un simple array, con acceso aleatorio muy rápido, pero las modificaciones pueden ser lentas. En deque las modificaciones son rápidas pero el acceso aleatorio es muy lento. Las operaciones son prácticamente las mismas que en list, así que no voy a poner código.
Itertools
El módulo itertools de Python es otro gran módulo lleno de funcionalidad interesante, en este caso para trabajar con iteradores, basado en los lenguajes APL, Haskell y SML.
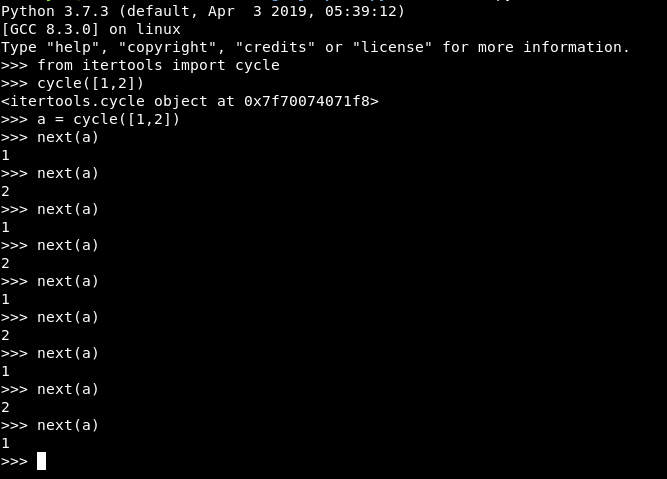
Lo primero a mencionar son los iteradores infinitos: count, cycle y repeat. Por ejemplo, cycle es un iterador que toma un iterador y cuando este se acaba lo vuelve a repetir, así hasta el infinito.
Luego tenemos otras funciones como takewhile (genera un iterador a partir de otro iterador mientras se cumpla una condición), chain (que une iteradores), groupby (genera subiteradores según un atributo de agrupamiento) y tee (que genera N subiteradores).
from itertools import *
a = range(1,100)
b = takewhile(lambda x: x<50,a)
c = dropwhile(lambda x: x<50,a)
d = chain(b,c)
e = sorted(d,key=lambda x: x%2 == 0)
for k, g in groupby(e,key=lambda x: x%2==0):
print(k)
for x in g:
print(x,end=' ')
print("")

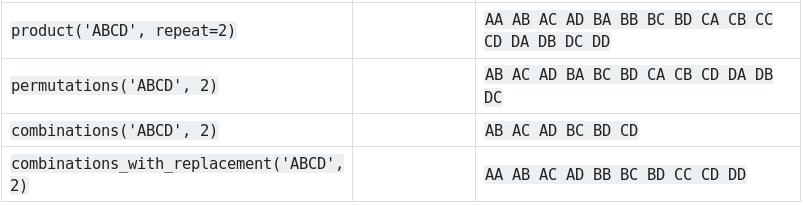
Por último, el módulo tiene funciones muy útiles de combinatoria como el producto cartesiano, las permutaciones, las combinaciones (con y sin repetición).
Zip, reversed y enumerate
La función zip es un builtin, es decir, no hay que importar nada. La función zip junta dos iteradores en uno y un iterador de tuplas. Zip tiene la longitud del iterador más corto, si necesitas que tome la longitud del más largo, la función zip_longest de itertools hace justamente eso.
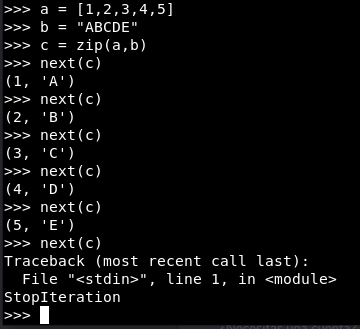
La función reversed recorre el iterador en orden inverso y enumerate proporciona una tupla con el elemento y su posición en el iterador.
Any y all
Any y all son otros dos builtins de Python. Devuelven true cuando algún elemento del iterador cumple la condición (any) o todos la cumplen (all). Usando estas expresiones podemos comprobar que una palabra es palindrómico de la siguiente forma:
def palindromic(sequence):
return all(
n == m
for n, m in zip(sequence, reversed(sequence))
)
print(palindromic("abba"))
property
Cuando trabajamos con código orientado a objeto en Python, es recomendable usar propiedades, en vez de funciones manuales de getters y setters.
class P:
def __init__(self,x):
self.x = x
@property
def x(self):
return self.__x
@x.setter
def x(self, x):
if x < 0:
self.__x = 0
elif x > 1000:
self.__x = 1000
else:
self.__x = x
staticmethod y classmethod
Estas funciones también son decoradores de funciones dentro de una clase. Su uso es similar es parecido. classmethod es para métodos que pueden llamarse tanto de forma estática como con un objeto instanciado, un ejemplo típico son los métodos factoría. staticmethod sin embargo se refiere a métodos estáticos dentro de una clase, aunque en Python tampoco se usan demasiado.
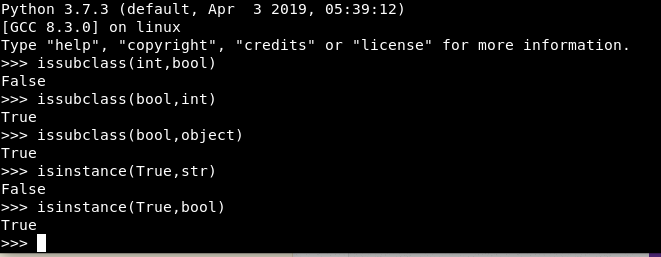
isinstance e issubclass
Para acabar con las funciones propias de la orientación a objetos, estas dos funciones nos permiten comprobar si un objeto es instancia de una clase y si una clase es subclase de otra.
Conclusiones
Como veis, Python tiene muchas cosas interesantes. Espero que en esta lista haya al menos alguna cosa que no conociéseis. Si además conoces alguna otra cosa no tan conocida pero que consideras útil dentro de Python, puedes ponerla en los comentarios.