Buscando en los datos del leak de Facebook con ElasticSearch
Recientemente hemos conocido la noticia de un leak de datos de Facebook. Principalmente son nombres y números de teléfono. Se trata de una brecha grave, ya que es una fuente perfecta para phising y estafas de este tipo. En este post vamos a ver como cargar estos datos en una base de datos optimizada para búsquedas como ElasticSearch y como hacer algunas consultas. No voy a enlazar los datos originales, ya que es una información peligrosa pero no es muy difícil encontrarlos.
Instalando ElasticSearch y Kibana
El primer paso es instalar ElasticSearch, nuestra base de datos, y Kibana, una interfaz de consulta y administración de ElasticSearch. En mi caso, voy a usar Docker, así que la "instalación" es en realidad un fichero de Docker Compose. Si no sabes nada de Docker Compose te recomiendo este tutorial. El fichero se llamará docker-compose.yml:
version: "3.6"
services:
elasticsearch:
image: elasticsearch:7.12.0
ports:
- 9200:9200
- 9300:9300
environment:
discovery.type: single-node
volumes:
- data:/usr/share/elasticsearch/data
kibana:
image: kibana:7.12.0
ports:
- 5601:5601
environment:
ELASTICSEARCH_HOSTS: http://elasticsearch:9200
depends_on:
- elasticsearch
volumes:
data:
Básicamente lo que indicamos es que queremos un servicio basado en una imagen de ElasticSearch 7.12.0, donde abrimos los puertos 9200 y 9300 y lo configuramos como single-node. Además le añadimos un volumen para almacenar los datos.
Después indicamos que queremos un servicio de Kibana, que abrirá el puerto 5601 y le configuramos el servidor de ElasticSearch al que hemos definido arriba.
Para descargarlo todo, ejecutamos el comando up de docker-compose:
docker-compose up
Ingestión de los datos con Logstash
Ya tenemos ElasticSearch y Kibana levantados. Ahora hace falta ingestar los datos del leak. Para ello usaremos otra herramienta del mundo Elastic, Logstash. Logstash es una herramienta de ingesta potente, que posee varios filtros. Con esta herramienta leeremos los datos de Facebook en formato quasi-csv (está separado por : en vez de , y las comillas funcionan raro) y los dejaremos en nuevo index de ElasticSearch.
Todo esto se define con un fichero de configuración, que será parecido a este:
input {
file {
path => "/config/spain.txt"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
mutate {
gsub => ["message", "\"", ""]
}
csv {
separator => ":"
columns => ["phone_number", "facebook_id", "name", "surname", "gender", "location1", "location2", "relationship", "work", "field1", "field2", "field3"]
}
}
output {
elasticsearch {
hosts => "http://elasticsearch:9200"
index => "facebook-spain"
}
}
Se indica el fichero origen de los datos, en este caso, /config/spain.txt. Se indica que se haga una sustitución de las comillas por espacios, se usa el plugin csv para cargar los datos según las columnas que indiquemos. Y finalmente se indica donde hay que guardar los datos, en este caso en un ElasticSearch, en el index facebook-spain (se crea solo)
Una forma de ejecutar Logstash es también desde Docker Compose, usando otro fichero. Esta ha sido mi opción, pero también podríamos hacerlo desde fuera, solo hay que tener cuidado de configurar el host de ElasticSearch y la ruta al fichero de origen.
Con Docker Compose, habría que añadir este servicio y asegurarse de que tanto el fichero logstash-fb-spain.conf como el spain.txt (los datos en crudo) esten en la misma carpeta:
logstash:
image: logstash:7.12.0
command: logstash -f /config/logstash-fb-spain.conf
volumes:
- ./:/config
depends_on:
- elasticsearch
Y levanta el servicio con docker-compose up. Este proceso llevará su tiempo. Relájate, a mí me duró un par de horas.
Buscando Kibana
Si accedemos a http://localhost:5601, veremos algo similar a esto:
Se trata de la página de inicio actual de Kibana. Para consultar los datos sobre Kibana hay que crear un Index Pattern. Para hacerlo vamos a Manage. En las opciones buscamos Index Patterns y desde ahí creamos uno. Un Index Pattern es una expresión para grupar varios Index en uno. En nuestro caso solo tenemos un Index (facebook-spain). Podemos crear un Index Pattern con el patrón "facebook*", "facebook-spain*" o "facebook-spain", todos ellos y más variaciones valdrán para seleccionar nuestro Index.
Ya que estamos en los ajustes, podemos ir a Index Managemente y veremos el tamaño de nuestro Index creado con Logstash:
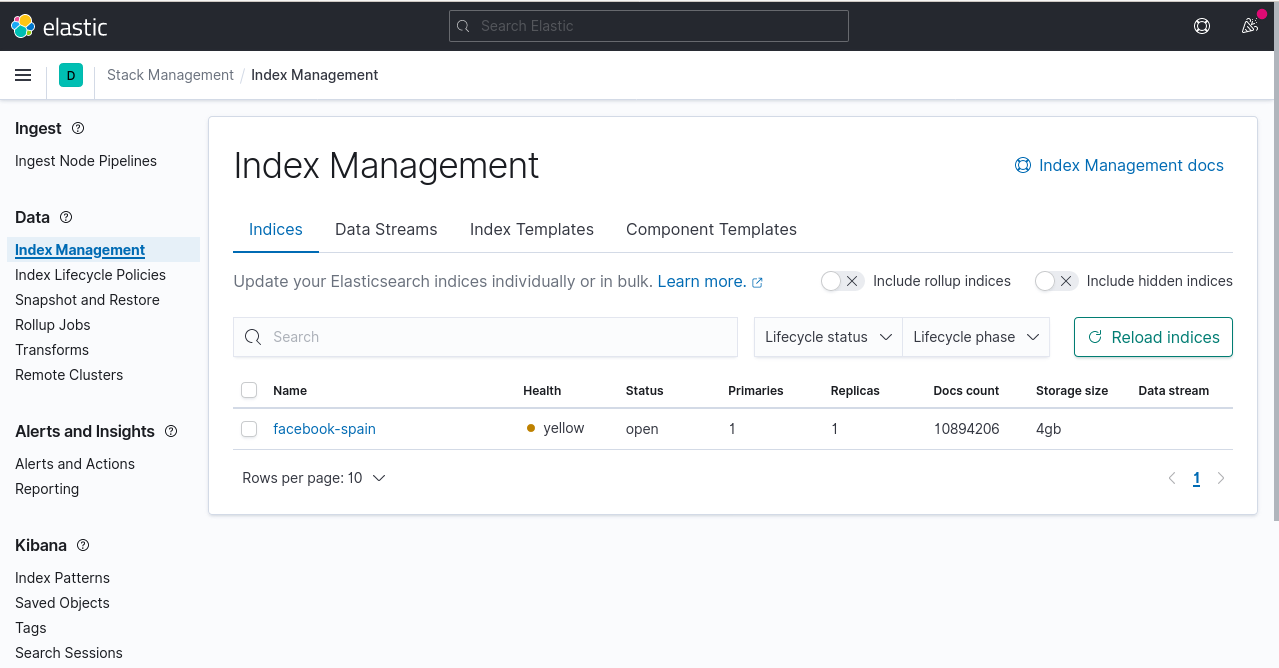
En el caso de spain.txt, son casi 11 millones de registros.
Ahora ya sí podemos ir a la sección Discover dentro del menú lateral izquierdo
Desde aquí podremos hacer consultas más o menos avanzadas usando el lenguaje KQL. Pero no te preocupes, escribir directamente lo que quieres buscar es un tipo de query KQL válido. En la imagen se puede ver una consulta en KQL algo más avanzada:
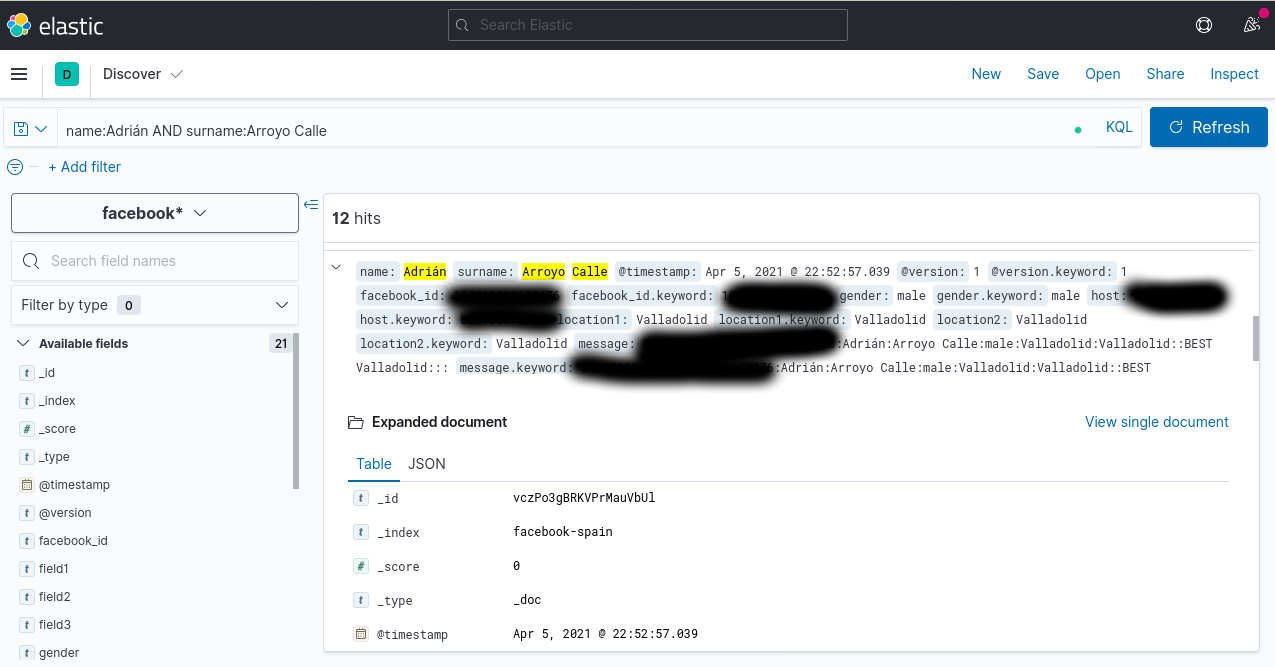
Con esto ya podemos realizar todo tipo de búsquedas. No obstante, el buscador no será capaz de distinguir mayúsculas de minúsculas y las tildes de las no tildes. Esto se puede definir con analizadores en ElasticSearch pero en este caso concreto, no creo que merezca mucho la pena. De cara a un buscador, por ejemplo, de artículos en un blog, sí sería interesante hacerlo.
Bonus: una app en FastAPI para consultar
Kibana es una mera interfaz sobre ElasticSearch. Nosotros podemos crear nuestras propias aplicaciones que usen la API REST de ElasticSearch para realizar las consultas. El endpoint para hacer búsquedas en ElasticSearch es /_search. Existen diferentes formas de buscar, mediante solo un campo, multi-campo, con y sin boosting, e incluso con KQL. Yo he elegido esta última opción.
Para crear el proyyecto FastAPI uso Poetry, un gestor de paquetes y entornos virtuales de Python.
poetry init
poetry add fastapi aiohttp jinja2 uvicorn
poetry shell
El código de la aplicación es muy simple. Hay dos rutas, una de inicio y otra para realizar una búsqueda en ElasticSearch mediante REST. Ambas usano la misma plantilla HTML para mostrar resultado.
from fastapi import FastAPI, Request
from fastapi.templating import Jinja2Templates
import aiohttp
app = FastAPI()
templates = Jinja2Templates(directory="templates")
session = aiohttp.ClientSession()
@app.get("/")
def index(request: Request):
return templates.TemplateResponse("search.html", {"request": request, "hits": []})
@app.get("/search")
async def search(request: Request, name: str, surname: str):
query = {
"size": 100,
"query": {
"query_string": {
"query": f"(name:{name} AND surname:{surname})",
}
}
}
async with session.get("http://localhost:9200/_search", json=query) as response:
result = await response.json()
return templates.TemplateResponse("search.html", {"request": request, "hits": result["hits"]["hits"]})
La plantilla está disponible aquí. Esta app podemos ejecutarla con el comando
.
uvicorn main:app
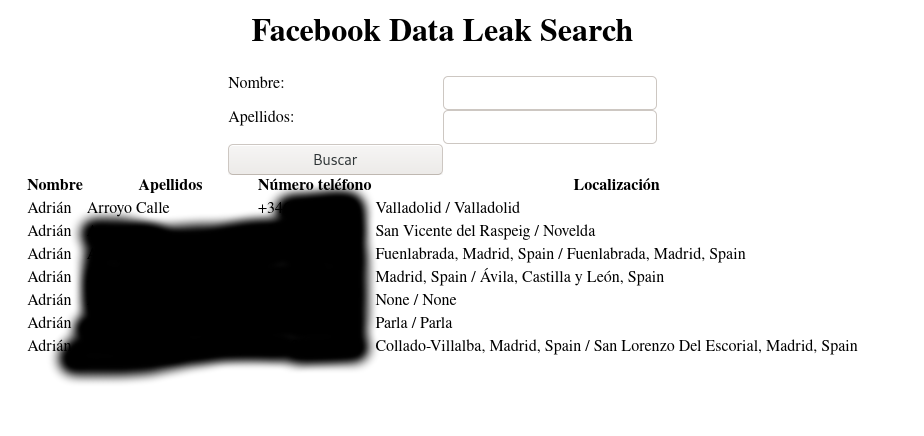
¡Y ya podremos hacer búsquedas de forma más amigable!
Todo el código usado aquí, salvo los datos del leak, están en el repositorio de GitHub de ejemplos del blog.