Analizando estadísticas web con bajo costo
Si tienes una página web es bastante probable que te interese saber ciertos datos de tus usuarios. Algunos de ellos son verdaderamente legítimos, como por ejemplo saber que páginas son más populares o qué tipo de software usan los usuarios para conectarse. Mucha gente utiliza herramientas como Google Analytics para obtener esta información. Es un método sencillo y eficaz, pero donde no solo recopilas los datos tú, también Google, y ellos recopilan bastante más datos. Y Google puede cruzarlos entre los muchos otros sitios que también usan Analytics, siendo terrible para la privacidad de los usuarios. Otra estrategia es analizar los logs del servidor HTTP. Esta solución no es invasiva, solo recopila un par de datos técnicos, y permite un procesamiento puramente local. En este artículo veremos como podemos hacer un sistema así.
Configurando nginx
En primer lugar tenemos que configurar el servidor web para que nos genere los logs que nosotros queramos. En mi caso voy a usar nginx, ya que es el servidor HTTP que uso siempre.
Dentro de nginx, el fichero de configuración principal está ubicado en /etc/nginx/nginx.conf. Normalmente en nginx se añade una directiva para
cargar la configuración específica de cada sitio (host) en un fichero aparte diferente. Sin embargo, esta configuración la quiero aplicar a todos los sitios por igual, así que modificaremos el fichero principal
nginx nos permite decidir donde se va a almacenar el log y con qué formato. Por defecto, nginx ya tiene un formato y una ubicación. Lo que vamos a hacer es especificar un formato de salida que sea compatible con CSV (es decir, separado por comas y entre comillas los campos que pueden tener comas) y un fichero diferente por cada host. Además modificamos la fecha a un formato más estándar.
http {
....
log_format main '$remote_addr,$remote_user,$time_iso8601,"$request",'
'$status,$body_bytes_sent,"$http_referer",'
'"$http_user_agent","$http_x_forwarded_for"';
access_log /var/log/nginx/access-$host.log main;
}
nginx soporta alguna variable más pero de momento vamos a ir con esas columnas. Es importante ver que el campo request contiene tanto el método usado (GET, POST, PUT, ...) como el path como el protocolo sobre el que se ha negociado. Esto lo separaremos en una etapa posterior de preprocesado.
Una vez tengamos los cambios y hayamos reiniciado nginx, poco a poco se irán generando los ficheros con los datos de las visitas.
Ingestando datos
Los logs se van generando poco a poco con las visitas. Ahora vamos a hacer un pequeño programa que vaya procesando cada cierto tiempo los ficheros, separe los campos de la request para mejor análisis, los deje en un fichero Parquet listo para analizar y lo suba a un sitio. En definitiva, un proceso de ingesta.
Azure
Lo primero será configurar en una plataforma, en mi caso voy a usar Microsoft Azure, un espacio de almacenamiento para dejar nuestros ficheros Parquet a salvo.
En Azure lo primero será crear un Resource Group, con el nombre que queramos, yo lo llamaré adrianistan-logs. Dentro creamos una Storage Account con el mismo nombre y en principio no necesitaremos ajustes extra. Si quieres redundancia y esas cosas, puedes activarlas. Solo nos interesa el servicio de Blob Storage básico. Ahora creamos un container nuevo, en este caso para los logs del host, blog.adrianistan.eu. La idea será un container para cada host.
Una vez lo tengamos vamos a la sección de Shared Access Tokens y generamos uno con los permisos necesarios por el tiempo necesario. Este token lo almacenamos, será un parámetro que pasaremos al script.
Script de ingesta con DuckDB
Para el script vamos a usar Python y DuckDB. Una base de datos similar a SQLite pero para cargas de trabajo analíticas. En el contenedor tendremos un fichero, con todos los logs. Si no existe lo crearemos de cero, si existe añadiremos solo los logs nuevos.
DuckDB se maneja mediante SQL, con alguna adición extra. Usaremos la función regexp_extract para extraer del campo request el método, la ruta y el protocolo de forma individual.
En el script usaremos los SAS Tokens para interactuar con Azure mediante requests sin necesidad de la librería oficial de Azure. Subimos ficheros con PUT, comprobamos su existencia con HEAD, borramos con DELETE y descargamos con GET.
Aquí el fichero completo:
import argparse
import requests
import duckdb
from urllib.request import urlretrieve
from datetime import datetime, timedelta
# We take file logs-all.parquet
# If exists:
# - We download it and get the last date of the logs
# - We open the nginx log file and we append the logs after that date
# - We upload a new logs.parquet file
# If it doesn't
# - We open the nginx log file and append everything
# - We upload a new logs.parquet file
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--log-file", help="Location of log file to be ingested", required=True)
parser.add_argument("--blob-sas-url", help="Azure Blob URL to upload Parquet file with a SAS token attached", required=True)
args = parser.parse_args()
url = azure_url("logs.parquet", args.blob_sas_url)
response = requests.head(url)
if response.status_code != 404:
urlretrieve(url, "old-logs.parquet")
duckdb.sql(
"""
COPY
(
SELECT
remote_addr,
remote_user,
time,
status,
body_bytes_sent,
http_referer,
http_user_agent,
http_x_forwarded_for,
regexp_extract(request, '(.+) (.+) (.+)', 1) AS method,
regexp_extract(request, '(.+) (.+) (.+)', 2) AS path,
regexp_extract(request, '(.+) (.+) (.+)', 3) AS protocol,
FROM read_csv('%s', columns = {
'remote_addr': 'VARCHAR',
'remote_user': 'VARCHAR',
'time': 'TIMESTAMPTZ',
'request': 'VARCHAR',
'status': 'SMALLINT',
'body_bytes_sent': 'INTEGER',
'http_referer': 'VARCHAR',
'http_user_agent': 'VARCHAR',
'http_x_forwarded_for': 'VARCHAR',
})
WHERE
time > ( SELECT MAX(time) FROM read_parquet('old-logs.parquet'))
UNION
SELECT * FROM read_parquet('old-logs.parquet')
)
TO 'logs.parquet'
(FORMAT 'parquet', COMPRESSION 'zstd')
""" % args.log_file )
requests.delete(url)
else:
duckdb.sql(
"""
COPY
(
SELECT
remote_addr,
remote_user,
time,
status,
body_bytes_sent,
http_referer,
http_user_agent,
http_x_forwarded_for,
regexp_extract(request, '(.+) (.+) (.+)', 1) AS method,
regexp_extract(request, '(.+) (.+) (.+)', 2) AS path,
regexp_extract(request, '(.+) (.+) (.+)', 3) AS protocol,
FROM read_csv('%s', columns = {
'remote_addr': 'VARCHAR',
'remote_user': 'VARCHAR',
'time': 'TIMESTAMPTZ',
'request': 'VARCHAR',
'status': 'SMALLINT',
'body_bytes_sent': 'INTEGER',
'http_referer': 'VARCHAR',
'http_user_agent': 'VARCHAR',
'http_x_forwarded_for': 'VARCHAR',
})
)
TO 'logs.parquet'
(FORMAT 'parquet', COMPRESSION 'zstd')
""" % args.log_file )
requests.put(url, headers={
"Content-Type": "application/vnd.apache.parquet",
"x-ms-blob-type": "BlockBlob"
}, data=open("logs.parquet", "rb"))
def azure_url(filename, blob_sas_url):
blob_split_url = blob_sas_url.split("?")
return f"{blob_split_url[0]}/{filename}?{blob_split_url[1]}"
if __name__ == "__main__":
main()
La forma de ejecutarlo será:
python ingest.py --log-file /var/log/nginx/access-blog.adrianistan.eu.log --blob-sas-url "https://adrianistanlogs.blob.core.windows.net/blog-adrianistan-eu?SAS_TOKEN"
Configuración systemd
Para que se ejecute de forma automatizada lo ideal es tener un servicio con timer asociado en systemd.
Los timers en systemd se componen de mínimo dos ficheros: un servicio que define lo que se ejecuta y un timer que define cuando se va a ejecutar. Ambos archivos pueden alojarse en /etc/systemd/system/ ya que van a ser servicios de sistema.
El fichero logs-blog-adrianistan.timer tendrá un contenido similar a este:
[Unit]
Description=Timer activation of log ingestion for blog.adrianistan.eu
[Timer]
OnCalendar=4:00
[Install]
WantedBy=timers.target
El fichero logs-blog-adrianistan.service tiene el mismo nombre salvo la extensión por lo que no necesitamos especificarlo.
Su contenido es el siguiente:
[Unit]
Description=Ingest blog.adrianistan.eu logs from nginx to Azure
Wants=network-online.target
After=network-online.target
[Service]
Type=simple
User=USER
ExecStart=/usr/bin/poetry run python ingest.py --log-file /var/log/nginx/access-blog.adrianistan.eu.log --blob-sas-url "https://adrianistanlogs.blob.core.windows.net/blog-adrianistan-eu?SAS_TOKEN"
WorkingDirectory=/home/user/webstats
En la parte de SAS_TOKEN deberemos tener cuidado y si nos aparecen %, espacarlos con otro % para que no de error.
Finalmente activamos el timer con:
$ systemctl enable --now logs-blog-adrianistan.timer
Podemos revisar que se ha activado correctamente con:
$ systemctl list-timers
Y finalmente si queremos probar una ejecución del servicio fuera del timer, simplemente con un start al servicio podremos probarlo.
$ systemctl start logs-blog-adrianistan.service
$ journalctl -fu logs-blog-adrianistan.service
Análisis en Streamlit
Con lo anterior iremos recogiendo datos todos los días. Ahora hay que visualizarlos. Para ello usaremos Streamlit, y por variar, usaré Polars para analizar el fichero Parquet.
Streamlit es una herramienta que nos permite escribir interfaces de usuario similares a paneles de datos de forma extremadamente sencilla. Para ello solo tendremos que hacer un pequeño programa Python donde vamos escribiendo, de forma lineal, los datos que queremos mostrar. Existen ciertos widgets que permiten darle interactividad al asunto.
En esencia, cuando hay un cambio, Streamlit reejecuta todo el fichero. De esta forma es sencillo. Pero tiene el inconveniente de que puede tener que hacer operaciones costosas muchas veces. Para solventarlo, existe un decorador llamado cache_data que podemos añadir para indicar que ese código, para esos parámetros, solo debe ejecutarse una vez.
Widgets en Streamlit
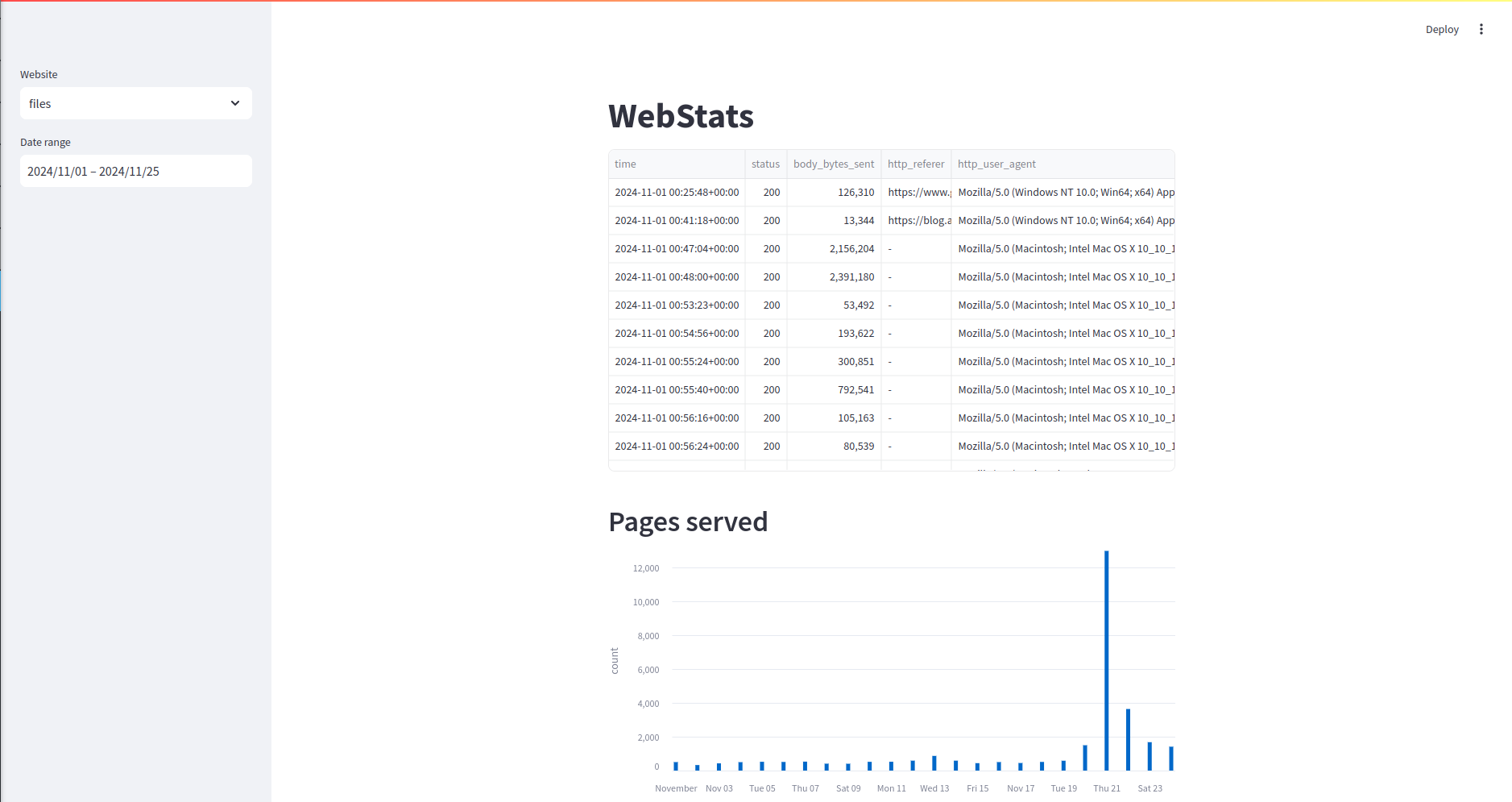
Voy a añadir dos widgets. En el primero seleccionaré el sitio web del que quiero ver las estadísticas (ya que el proceso de ingesta lo voy a hacer con varios sitios web). El segundo me permite filtrar por fecha los datos que se van a visualizar. Así podré ver un mes, una semana o lo que quiera.
import streamlit as st
import polars as pl
from datetime import datetime, UTC
st.title("WebStats")
website = st.sidebar.selectbox("Website", ("blog", "files", "ppt", "prologhub", "social"))
today = datetime.now(UTC)
first_day_month = datetime(today.year, today.month, 1)
dates = st.sidebar.date_input("Date range", (first_day_month, today))
A continuación tengo unos diccionarios con las cadenas de conexión y los nombres de host de cada web (necesario para una panel que veremos más adelante)
urls = {
"blog": "https://adrianistanlogs.blob.core.windows.net/blog-adrianistan-eu/logs.parquet?SAS_TOKEN",
"files": "https://adrianistanlogs.blob.core.windows.net/files-adrianistan-eu/logs.parquet?SAS_TOKEN",
"ppt": "https://adrianistanlogs.blob.core.windows.net/ppt-adrianistan-eu/logs.parquet?SAS_TOKEN",
"prologhub": "https://adrianistanlogs.blob.core.windows.net/prologhub-com/logs.parquet?SAS_TOKEN",
"social": "https://adrianistanlogs.blob.core.windows.net/social-adrianistan-eu/logs.parquet?SAS_TOKEN"
}
hosts = {
"blog": "blog.adrianistan.eu",
"files": "files.adrianistan.eu",
"ppt": "ppt.adrianistan.eu",
"prologhub": "prologhub.com",
"social": "social.adrianistan.eu"}
@st.cache_data
def download_data(url):
return pl.read_parquet(url)
host = hosts[website]
df = download_data(urls[website])
df = df.filter(pl.col("time").dt.replace_time_zone(None).is_between(dates[0], dates[1]))
Mostrando gráficas
La primera gráfica que podemos mostrar es el número de páginas servidas por día. Para ello, usando Polars y Streamlit podemos añadir el siguiente código.
st.header("Pages served")
tdf = df.with_columns(day=pl.col("time").dt.date())
tdf = tdf.group_by(pl.col("day")).agg(pl.len().alias("count")).sort("day")
st.bar_chart(tdf, x="day", y="count")
Mostrando dataframes
Personalmente hay muchas partes donde prefiero ver las tablas de datos filtrados y ordenados. En mi caso he añadido consultas para: páginas populares, datos enviados (por ruta), user agents, referrals (externos e internos) y páginas rotas.
Para mostrarlos uso el método dataframe con la propiedad use_container_width para que todos tengan el mismo ancho. Luego desde Streamlit podemos también ampliar y hacer ciertas operaciones sobre las tablas
st.header("Popular pages")
st.dataframe(df.group_by(pl.col("path")).agg(pl.len().alias("count")).sort("count", descending=True), use_container_width=True)
st.header("Data sent in MB")
bdf = df.with_columns(megabytes_sent=pl.col("body_bytes_sent") / 1000000) \
.group_by(pl.col("path")) \
.agg((pl.sum("megabytes_sent")).alias("megabytes")) \
.sort("megabytes", descending=True)
st.dataframe(bdf, use_container_width=True)
st.write(bdf.select(pl.col("megabytes").sum()))
st.header("User Agents")
st.dataframe(
df.group_by(pl.col("http_user_agent"))
.agg(pl.len().alias("count"))
.sort("count", descending=True), use_container_width=True)
st.header("Referrals")
st.subheader("External")
st.dataframe(
df.filter(pl.col("http_referer").str.contains(f"^https?://{host}") == False)
.group_by(pl.col("http_referer"))
.agg(pl.len().alias("count"))
.sort("count", descending=True), use_container_width=True)
st.subheader("Internal")
st.dataframe(
df.filter(pl.col("http_referer").str.contains(f"^https?://{host}") == True)
.group_by(pl.col("http_referer"))
.agg(pl.len().alias("count"))
.sort("count", descending=True), use_container_width=True)
st.header("Broken pages")
st.dataframe(
df.filter(pl.col("status") == 404)
.group_by(pl.col("path"))
.agg(pl.len().alias("count"))
.sort("count", descending=True), use_container_width=True)
Haciendo:
$ streamlit run webstats.py
Podemos ver el panel e interactuar con él