Agregador de enlaces en la nube con AWS Lambda y Terraform
Siempre había querido hacer una especie de planeta o agregador de enlaces ya que personalmente, son sitios que visito mucho. En este post veremos como hacer un agregador de enlaces en la nube (concretamente Amazon Web Services) de forma gratuita usando los servicios Lambda, CloudWatch y S3. Todo lo juntaremos usando Terraform
El agregador de enlaces aka la lambda
El agregador de enlaces será un código que visitará diferentes fuentes, definidas en el formato estándar OPML, filtrará las noticias que son de los últimos 30 días y las combinará con una plantilla para sacar un HTML con los títulos y enlaces a las páginas originales.
AWS Lambda nos permite que este código se ejecute como máximo durante 15 minutos y nos deja varios lenguajes: Ruby, Node.js, Java, Go, C#, PowerShell y por supuesto, Python, que es el que vamos a usar. En AWS Lambda tenemos disponible Python 3.8, que será la versión que usaremos.
Para descargar los feeds usaremos aiohttp, que permite hacer requests de forma asíncrona. feedparser se encargará de leer los feeds. Las plantillas las renderizaremos con Jinja. Finalmente, subiremos el resultado de la web a S3, otro servicio de AWS.
Vamos a ir viendo el código. Primero importamos aquello que vamos a usar y ajustamos el logger a que saque eventos hasta de nivel INFO. Estos logs los podremos ver en CloudWatch más adelante.
import aiohttp
import feedparser
import boto3
from boto3.s3.transfer import S3Transfer
from jinja2 import Environment, FileSystemLoader, select_autoescape
import asyncio
import itertools
import xml.etree.ElementTree as ET
import logging
import mimetypes
import shutil
import urllib
import tempfile
from datetime import datetime
from dataclasses import dataclass
from pathlib import Path
logging.getLogger().setLevel(logging.INFO)
A continuación creamos la clase Item, que contiene cada noticia de un feed en nuestro formato. Tendrá un orden definido por la fecha, así como un constructor desde elementos item de feedparser (podría entenderse como un conversor de items de feedparser a items propios).
@dataclass
class Item:
title: str
url: str
date: datetime
source: str
def __lt__(self, other):
return self.date < other.date
@property
def readable_date(self):
return self.date.strftime("%d/%m/%Y")
@staticmethod
def from_feeditem(item, source):
try:
pdate = item["published_parsed"]
published_date = datetime(year=pdate.tm_year, month=pdate.tm_mon, day=pdate.tm_mday)
return Item(item["title"], item["link"], published_date, source)
except:
return None
def is_in_last_month(self):
return (datetime.today() - self.date).days < 30
A continuación definimos la función fetch_items, que realiza la conversión desde feed de feedparser hasta un listado de items propios. Está diseñada alrededor de map/filter.
def fetch_items(feed, source):
all_items = map(lambda x: Item.from_feeditem(x, source), feed["items"])
all_items = filter(lambda x: x is not None, all_items)
return filter(lambda x: x.is_in_last_month(), all_items)
Ahora definimos parse_source, que dado el texto de un feed, llama a feedparser y obtiene los elementos correspondientes.
def parse_source(feed_text, source):
feed = feedparser.parse(feed_text)
return fetch_items(feed, source)
Llega el turno de la función main, que será asíncrona para poder usar aiohttp. En la primera parte leemos el fichero OPML, obtenemos las URLs y vamos almacenando los items que deberán aparacer en la página web en una lista.
async def main():
tree = ET.parse("sources.opml")
body = tree.find("body")
sources = [ outline.get("title") for outline in body.iter("outline")]
feeds_url = [ outline.get("xmlUrl") for outline in body.iter("outline")]
items = list()
async with aiohttp.ClientSession() as session:
feeds = map(session.get, feeds_url)
for feed_task in asyncio.as_completed(feeds):
try:
feed = await feed_task
url = str(feed.url)
logging.info(f"Downloaded {url} with success")
feed_text = await feed.text()
i = feeds_url.index(url)
source = sources[i]
items.extend(parse_source(feed_text, source))
except:
pass
Allí en el except se podría hacer un control de errores más fino para detectar cuando una URL está caída e informar. El bucle for está gobernado por una función llamada asyncio.as_completed. Esta función pertenece al módulo estándar asyncio y permite tener un bucle que va sacando elementos asíncronos de la lista inicial según se van completando.
El siguiente paso es construir el código HTML con Jinja. No tiene mucho misterio salvo que es importante usar directorios temporales, ya que no podemos escribir en otras carpetas que no sean esas en AWS Lambda.
env = Environment(
loader=FileSystemLoader("templates"),
autoescape=select_autoescape(["html"])
)
items.sort(reverse=True)
temp_dir = tempfile.mktemp()
output_folder = Path(temp_dir) / "_site"
if not output_folder.exists():
output_folder.mkdir(parents=True)
output_file = output_folder / "index.html"
static_folder = Path.cwd() / "static"
shutil.copytree(static_folder, output_folder, dirs_exist_ok=True)
with open(output_file, "w") as f:
f.write(env.get_template("index.html").render(items=items))
print(f"OK: {output_folder}")
Finalmente subimos el resultado a S3. No hay que preocuparse por credenciales, ya que la Lambda tendrá credenciales automáticas en su entorno de ejecución. Si quieres hacer pruebas deberás exportar unas variables de entorno eso sí. Importante: marcamos la ACL como public-read para que se pueda leer desde fuera y asignamos mime types a mano, ya que de otro modo, S3 tendrá problemas en servir el HTML. Esto será lo último del main.
s3 = boto3.client("s3")
transfer = S3Transfer(s3)
for path in output_folder.iterdir():
transfer.upload_file(str(path), "lector.adrianistan.eu", path.name, extra_args={
"ACL": "public-read",
"ContentType": mimetypes.guess_type(path.name)[0]
})
Finalmente, definimos una función que será el punto de entrada de la Lambda, en este caso llamará a main a través de asyncio, para que la asincronía funcione.
def handler(event, context):
asyncio.run(main())
Con esto ya tendríamos la lambda, pero falta la configuración de AWS
Infraestructura en Terraform
Vamos a crear un fichero amazon.tf en la misma carpeta. Contendrá la infraestructura en AWS como código. Primero definimos que vamos a usar AWS y seleccionamos una región (yo uso eu-west-3, París). También podemos crear un resource group. No es más que una forma de agrupar recursos que contengan el mismo tag, no tiene ningún coste. Vamos a poner que sean recursos del grupo todos los recursos de AWS que tengan el tag app con valor "lector".
provider "aws" {
region = "eu-west-3"
version = "2.60.0"
}
resource "aws_resourcegroups_group" "lector" {
name = "lector"
resource_query {
query = <<JSON
{
"ResourceTypeFilters": [
"AWS::AllSupported"
],
"TagFilters": [
{
"Key": "app",
"Values": ["lector"]
}
]
}
JSON
}
}
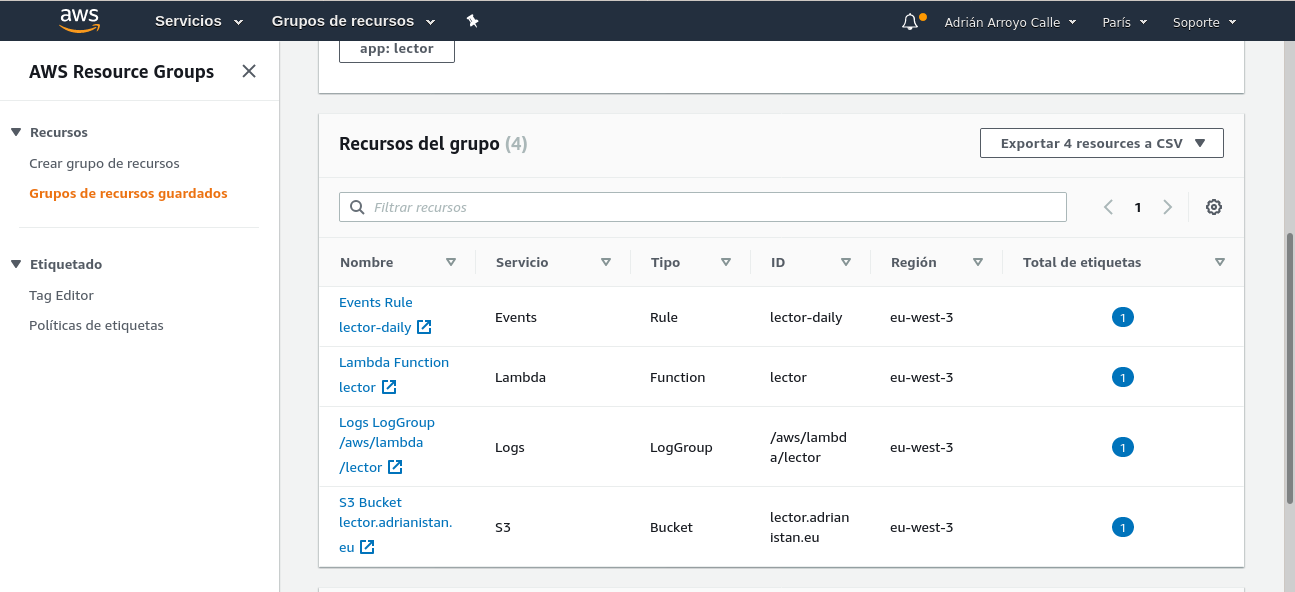
Amazon S3
S3 es el servicio de almacenamiento de "objetos" de AWS. Se diferencia de otros almacenamientos en que principalmente está diseñado para acceder mediante una API en contraste con otros almacenamientos de "bloques" que básicamente son discos duros y hay que formatear. Las ventajas de este modelo es que es muy sencillo de mantener. S3 dispone de un modo website, que permite mostrar HTML directamente y también de redirecciones CNAME, de modo que responde a peticiones DNS de dominios que se llamen igual que el bucket.
El bucket por tanto se llamará lector.adrianistan.eu, que es el dominio que voy a apuntar hacia allí. Tiene una ACL de lectura pública y el punto de entrada es "index.html". Además defino un output, para que me muestre por consola la URL del bucket. Esto hay que ponerlo en el registro CNAME del subdominio en el proveedor del dominio que tengamos. Amazon tiene uno llamado Route53, pero para este proyecto no lo he usado.
resource "aws_s3_bucket" "lector-www" {
bucket = "lector.adrianistan.eu"
acl = "public-read"
website {
index_document = "index.html"
}
tags = {
app = "lector"
}
}
output "website_cname" {
value = aws_s3_bucket.lector-www.website_endpoint
}
IAM
AWS está altamente protegido y salvo los usuarios administradores, los demás tienen que pedir permisos de forma explícita. Nuestra lambda necesita permisos, para ser Lambda, para usar S3, y para usar CloudWatch. Estos credenciales son los que usará además nuestra lambda desde el código Python.
resource "aws_iam_role" "lector" {
name = "lector"
tags = {
app = "lector"
}
assume_role_policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "sts:AssumeRole",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Effect": "Allow",
"Sid": ""
}
]
}
EOF
}
resource "aws_iam_policy" "lector" {
name = "lector"
policy = file("policy.json")
}
resource "aws_iam_role_policy_attachment" "lector" {
role = aws_iam_role.lector.name
policy_arn = aws_iam_policy.lector.arn
}
El fichero policy.json contiene los permisos de la lambda.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "s3:*",
"Resource": "*"
},
{
"Action": [
"logs:*"
],
"Effect": "Allow",
"Resource": "*"
}
]
}
En este caso son permisos bastante abiertos, ya que dentro de S3 y CloudWatch Logs pueden hacer lo que quieran sobre cualquier recurso.
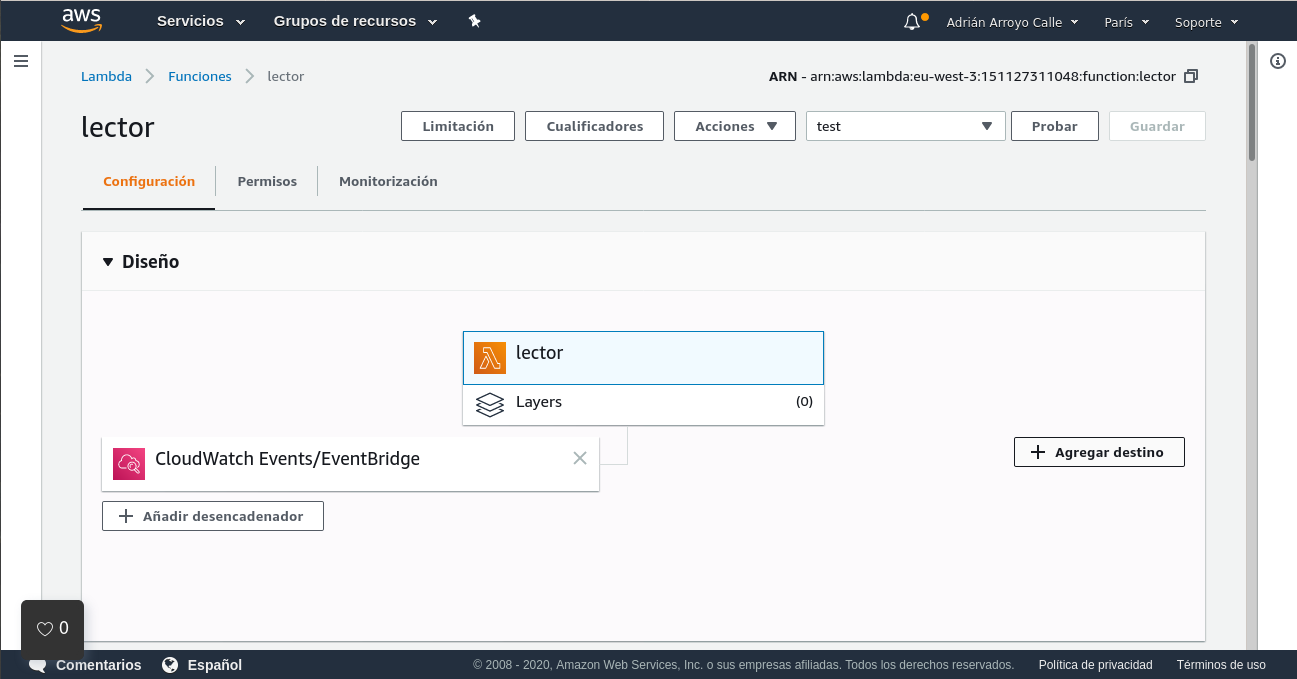
AWS Lambda
Las lambdas son programas de código pequeño sin estado que se ejecutan sin necesidad de configurar servidores por cortos periodos de tiempo (máximo 15 minutos). Para configurarlas solo tenemos que elegir permisos, subir el código (en un fichero Zip), la función de entrada, memoria RAM que podrá usar (por defecto 128 MB), timeout (por defecto son 3 segundos solo) y entorno de ejecución.
resource "aws_lambda_function" "lector" {
filename = "function.zip"
function_name = "lector"
role = aws_iam_role.lector.arn
handler = "main.handler"
source_code_hash = filebase64sha256("function.zip")
runtime = "python3.8"
memory_size = 256
timeout = 900
tags = {
app = "lector"
}
}
El código lo tenemos en el fichero function.zip. Este fichero se elabora de forma diferente según el lenguaje de programación que usemos. En el caso de Python, si queremos incluir la dependencias deberemos hacer un zip así:
pip install --target ./package -r requirements.txt
cd package
zip -r9 ../function.zip .
cd ..
zip -g function.zip static/*
zip -g function.zip templates/*
zip -g function.zip sources.opml
zip -g function.zip main.py
Básicamente instalamos los paquetes de Pip al mismo nivel que el resto de ficheros. AWS Lambda se ejecuta sobre Amazon Linux, por lo que no hay problema en usar el código nativo que se genera en las instalaciones de Pip desde Ubuntu o Debian.
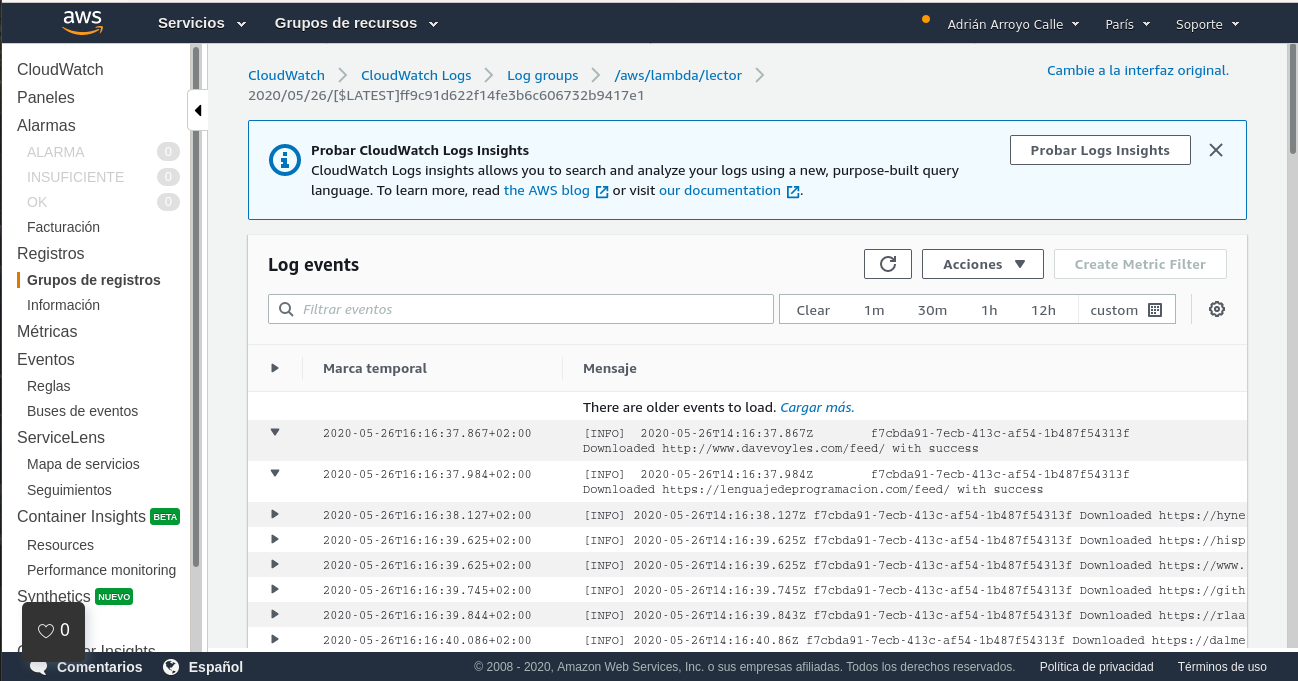
AWS CloudWatch
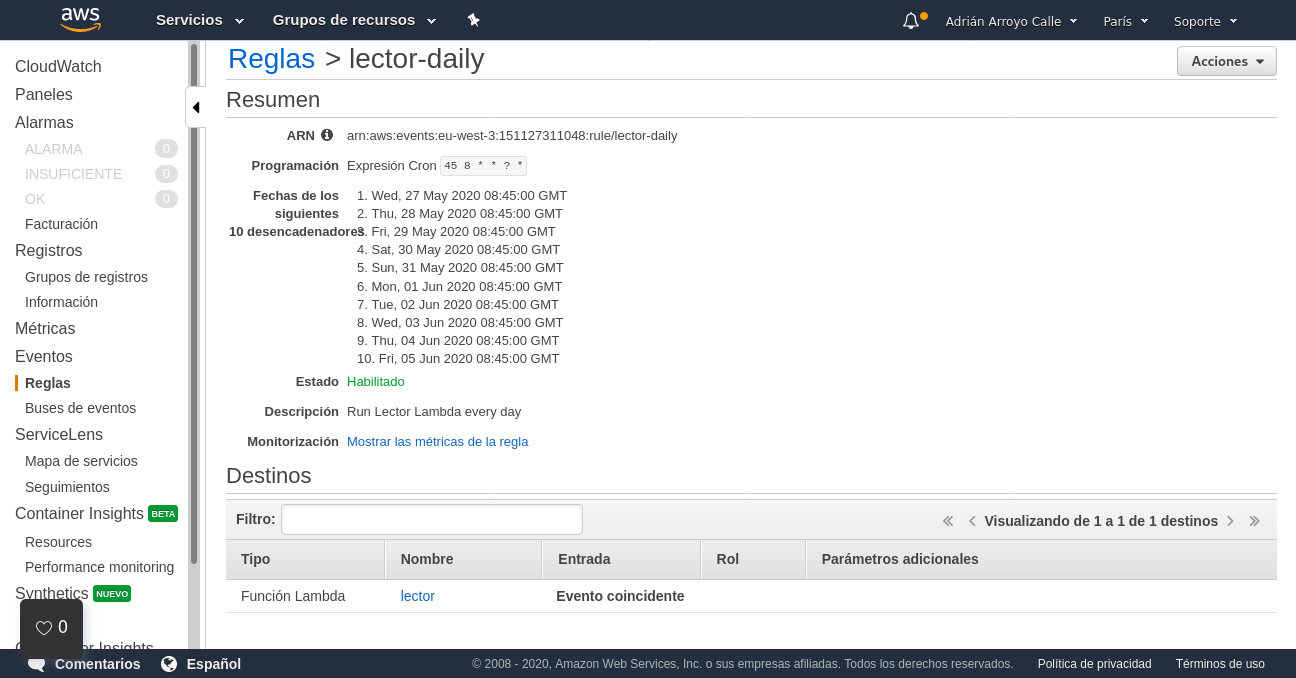
CloudWatch es un servicio de AWS con varias finalidades. Por un lado es una plataforma de recolección de logs y métricas. Por otro lado, también permite disparar eventos, por ejemplo, de tipo cron. En Terraform crearemos una regla cron, la asociaremos con la Lambda (¡hay que asignar permisos también!) y por otro lado crearemos una carpeta para los logs, con una retención de 7 días únicamente.
resource "aws_cloudwatch_event_rule" "lector-daily" {
name = "lector-daily"
description = "Run Lector Lambda every day"
schedule_expression = "cron(45 8 * * ? *)"
tags = {
app = "lector"
}
}
resource "aws_cloudwatch_event_target" "lector-daily" {
rule = aws_cloudwatch_event_rule.lector-daily.name
target_id = "lector-daily"
arn = aws_lambda_function.lector.arn
}
resource "aws_cloudwatch_log_group" "lector" {
name = "/aws/lambda/${aws_lambda_function.lector.function_name}"
retention_in_days = 7
tags = {
app = "lector"
}
}
resource "aws_lambda_permission" "cloudwatch-call-lector" {
statement_id = "AllowExecutionFromCloudWatch"
action = "lambda:InvokeFunction"
function_name = aws_lambda_function.lector.function_name
principal = "events.amazonaws.com"
source_arn = aws_cloudwatch_event_rule.lector-daily.arn
}
Conclusión
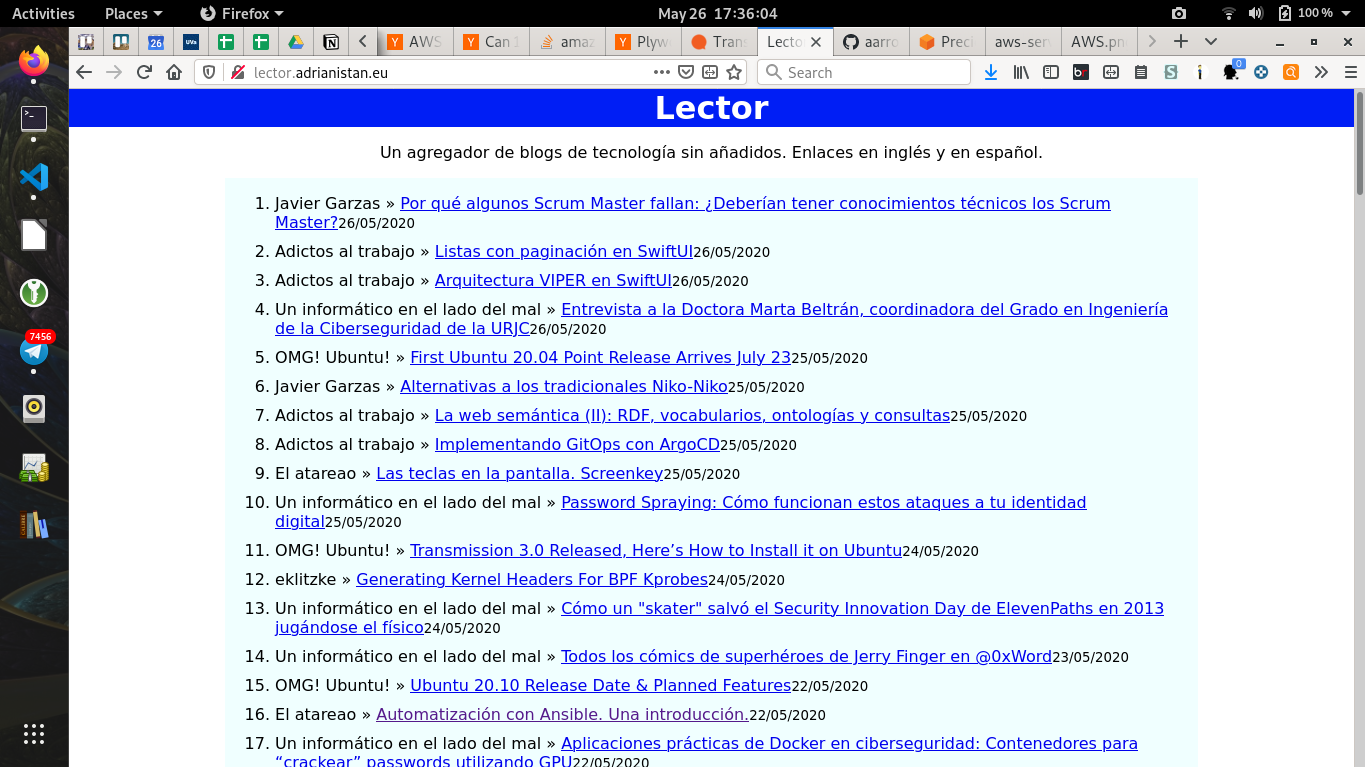
Con todo esto ya tenemos ya la aplicación acabada, un "terraform apply", nos permitirá lanzar la aplicación a la red. He de decir que a priori parece todo muy complejo. La razón es principalmente el tema de permisos de AWS, que es muy granular y restrictivo por defecto. También tenemos que considerar que una vez hecho esto, el mantenimiento de la aplicación es nulo. Esto que he hecho también se puede hacer en Microsoft Azure y en Google Cloud con Azure Functions y Google Cloud Functions respectivamente. Sin embargo, en Azure están limitadas a 10 minutos y creo que este programa puede llegar a tardar alguna vez más de 10 minutos. Finalmente el coste de todo esto. Esto que hemos hecho cuesta 0€. La capa gratuita de ejecución de Lambdas es muy elevada y ni aunque gastásemos los 15 minutos con 3GB de RAM todos los días llegaríamos a gastarlo. Lo mismo para los eventos. Los logs tienen un límite gratuito de 5GB. S3 es el único servicio que tendremos que pagar, pero si solo tenemos estos datos seguramente el redondeo sea 0€.
Puedes visitar la web final en http://lector.adrianistan.eu