Advent of Code 2018: primera semana
07/12/2018
Este año, como ya viene siendo habitual, tiene lugar la competición de programación Advent of Code. El objetivo es resolver un problema de programación al día, hasta el día de navidad, a modo de un particular calendario de adviento. Este año, como ya no viene siendo tan habitual, me he propuesto hacerlos todos y explicar mis soluciones. Esta semana todos han sido resueltos en Python.
Los programas que he usado, así como los enunciados y los datos de entrada que me han tocado (a cada uno le tocan datos diferentes) están en este repositorio de GitHub.
El primer reto que nos proponen es muy sencillo. Se nos pasa un archivo con sumas y restas y tenemos que calcular el resultado final. Pongamos un ejemplo trivial:
El procesdimiento es sencillo, leer cada operación, extraer el signo, convertir a número y aplicar la operación detectada por el signo.
La segunda parte es más interesante, ya que nos dice que tenemos que aplicar la misma cadena de operaciones de forma indefinida hasta encontrar una resultado repetido.
Aquí la clave es conocer el funcionamiento de un Set o conjunto. Se trata de una estructura de datos que no permite elementos repetidos. La idea está en ir almacenando los resultados que van saliendo hasta encontrar uno que ya esté dentro. Al encontrarlo salir e indicarlo.
Aquí viene una anécdota interesante. Estoy haciendo estos retos con unos amigos en un grupo de Telegram y al poco de yo haberlo terminado empezaron a preguntar cuánto tardaba en ejecutarse la segunda parte. Al parecer les iba muy lento, yo sorprendido les dije que había sido instantáneo y que estaba usando Python. Ellos se preguntaban como podía ser, ya que lo habían hecho en C y les estaba tardando varios minutos.
 Una representación de un set o conjunto. No puede haber elementos repetidos. No existe orden definido
Una representación de un set o conjunto. No puede haber elementos repetidos. No existe orden definido
La respuesta tiene que ver con el set. Yo sinceramente fui a él directamente pero otros compañeros no, y usaron listas y arrays. La búsqueda que realizaban para saber si el elemento estaba dentro era lineal. Comparada con la búsqueda en un set implementado con tabla hash que es constante, el rendimiento es muy inferior. He aquí un ejemplo de como lo más importante de cara a la eficiencia es el algoritmo y las estructuras de datos que usamos para resolver un problema.
El segundo día se nos propone otro problema de dificultad similar. Sobre una lista de palabras tenemos que contar cuantas palabras tienen 2 letras repetidas y 3 letras repetidas, para finalmente multiplicar ambos números.
En este caso fui bastante pragmático y opté por usar la clase Counter de Python. Counter cuenta cuantas veces aparece una letra y lo deja en un diccionario. Podemos ignorar las claves, ya que lo único que tenemos que hacer es buscar en los valores si está el 3 y el 2, y si es así, sumar uno a nuestro contador.
La segunda parte ya es más interesante. Se nos pide que la misma lista de palabras, encontremos las dos palabras que solo se diferencian en una letra (se tiene en cuenta el orden). Aquí el algoritmo es un poco más lento ya que para cada palabra la comparamos con el resto de palabras, hasta encontrar aquella que efectivamente tiene un cambio de únicamente una palabra.
Para ello hace falta una función que nos diga cuantas palabras hay de diferencia entre dos palabras, que es bastante sencillita.
Una vez tengamos las dos palabras que solo se diferencian en una letra, hacemos un bucle similar al usado para encontrarlas, solo que esta vez para formar la palabra con todas las letras que tienen en común, ignorando la diferente.
En el día 3 nos proponen un problema muy interesante. Tenemos una lista de parcelas rectangulares, definidas por la posición de su esquina superior-izquierda y su ancho y alto, todo en metros. Para la primera parte tenemos que encontrar cuantos metros cuadrados del universo ficticio están en dos o más parcelas a la vez.
Lo primero que hay que hacer es leer la entrada, que esta vez ya no es tan trivial. Un simple RegEx nos permite obtener toda la información de forma sencilla.
Para el algoritmo en sí, vamos a usar defaultdict. La idea es tener una tabla hash, cuya clave sean las coordenadas del mundo y su valor, el número de parcelas que estan sobre ella. Usamos defaultdict para que por defecto cualquier coordenada que no existiese con anterioridad tenga valor 0.
Así pues vamos a recorrer todas las parcelas y para cada parcela vamos a visitar todos los metros cuadrados que contiene en la tabla hash, sumando 1 para indicar que ese metro cuadrado pertenece a una parcela (más).
La segunda parte nos indica que solo existe una parcela que no esté invadida por otra parcela. Hay que buscar cuál es e informar del ID que tiene. Para esto he simplemente vuelto a recorrer cada parcela comprobando si tienen algún metro cuadrado con uso por más de 1 parcela. Si para una parcela no se encuentran metros compartidos, automáticamente se devuelve su ID (ya que solo hay una parcela de estas características).
El código completo es el siguiente:
En esta segunda parte, tengo la intuición de que existe una manera más eficiente de hacerlo, pero todavía no he encontrado esa solución más eficiente.
El problema del día 4, aunque aparentemente distinto al anterior, tiene muchas cosas en común y mi forma de resolverlo fue bastante parecida.
Se nos pide que sobre un registro de todas las noches identifiquemos el guardia que duerme más horas, y posteriormente su minuto preferido para quedarse dormido.
En primer lugar, la entrada de texto ya es bastante más compleja, pero con unos simples regex se puede analizar rápidamente, al menos para extraer la información que necesitamos. Aquí conviene prestar atención a que los registros de dormirse y despertarse ya que todos ocurren a la misma hora, luego lo único importante son los minutos. Otro detalle respecto a la entrada es que nos indican que está desordenada, sin embargo el formato de representación de la fecha que nos dan (parecido al ISO), se ordena cronológicamente simplemente con una ordenación alfabética.
La idea es muy similar a la del algoritmo anterior, primero tenemos una tabla hash con todos los guardias. Allí almacenamos otra tabla hash con los minutos de la hora y ponemos un cero si nunca se han dormido en ese minuto. Si usamos defaultdict, como en el código anterior, el código se simplifica bastante. En definitiva estamos usando dos tablas hash en vez de una y aplicar la misma idea de sumar 1, salvo que esta vez con el tiempo en vez del espacio (aunque Einstein vino a decir que eran cosas muy parecidas).
Posteriormente se recorren estas tablas hash para calcular lo pedido.
La segunda parte nos pide algo similar pero no idéntico, el guardia que se ha quedado dormido más veces en el mismo minuto (e indicar que minuto es).
La estructura de datos es exactamente la misma y solamente añadimos otro bucle para que busque este otro dato:
En este caso, la segunda parte apenas ha implicado modificaciones, siendo la estructura de datos subyacente intacta.
Este día se nos propone un reto aparentemente sencillo, pero cuya resolución puede ser muy lenta o rápida dependiendo de como lo hagamos. He de decir, que mi solución era muy lenta, extremadamente y tuve que mirar como lo habían hecho otras personas para entender como se podía optimizar.
La primera tarea consiste en reducir unas cadenas de reactivos. La norma es que si hay una letra minúscula y una mayúscula al lado, se pueden quitar. Se nos pide la longitud de la cadena de reactivos después de reducirlo al máximo.
La versión original consistía en ir realizando elimaciones sobre la propia lista. Todo ello en un bucle que para cuando en una iteración no se modifica la cadena. Esto es extremadamente ineficiente. Tomando el código de Peter Tseng, existe una opción mejor. Se puede ir haciendo un string nuevo poco a poco comprobando si la nueva letra reacciona con la última del string nuevo. Esto tiene la ventaja de que solo hace falta una iteración para cubrir todas las reacciones. La versión mejorada es la siguiente:
Para la segunda parte se nos pida que encontremos la letra, que si eliminamos del compuesto antes de empezar la reacción, genera la cadena más pequeña. Hay que probar con todas las letras, mención especial a string.ascii_lowercase que tiene un iterador con todas las letras minúsculas del alfabeto inglés. Y posteriormente, encontrar la que de resultado inferior. Como no nos pide la letra, solamente la longitud que tendría esa cadena, no tenemos que pasar información extra.
Esto se empieza a complicar. El día 6 nos pide que sobre una cuadrícula encontremos qué punto de control está más cercano a esa posición. De los puntos de control que un número de cuadrículas cercanas finitas, encontrar cuántas cuadrículas tiene el punto de control con más cuadrículas asociadas. Para saber la distancia de una cuadrícula al punto de control se usa la distancia de Manhattan.
Lo primero es reconocer que puntos de control tienen áreas infinitas, para no tenerlos en cuenta.
Para ello, voy a calcular dos puntos extremos (esquina superior izquierda y esquina inferior derecha), dentro del rectángulo que forman estos puntos están contenidos todos los puntos de control. El objetivo es calcular las distancias de las cuadrículas justo por fuera de este rectángulo. Las cuadrículas que estén más lejos de eso no van a cambiar de punto de control, ya que el más cercano en el borde seguirá siendo el más cercano en el borde + N, ya que no hay más puntos de control fuera.
Posteriormente, empezamos a calcular las distancias de todos los puntos de la cuadrícula. Para almacenar los datos vuelvo a usar una tabla hash (defaultdict de Python), donde la clave es la coordenada X,Y y el valor es el punto de control más cercano a esa cuadrícula. Si dos puntos de control están a la misma distancia o no se ha calculado, se usa -1.
Cuando se ha calculado el punto de control más cercano, se revisa si ese punto estaba fuera del rectángulo que contiene a los puntos de control. Si está fuera, el punto de control pasa a un conjunto de puntos con infinitas cuadrículas cercanas.
Para el conteo de cuántas cuadrículas tiene un punto de control que sabemos que es finito, uso otra tabla hash, inicializada por defecto a 0, cuya clave es el identificador de punto de control y su valor, el número de cuadrículas. Después, de los valores almacenados se calcula el máximo.
En la segunda parte nos dicen que hay una región de puntos cuya suma de distancias a todos los puntos de control es menor a 10000. ¿Cuántos puntos forman esta región? Aquí creo que el enunciado no fue demasiado claro, ya que en un principio pensé que podría haber varias áreas, o que podría haber puntos sueltos, no conectados a la región. Sin embargo eso no pasa. Yo diseñé un algoritmo que iba visitando las celdas adyacentes, pero en realidad no hacía falta, simplemente se puede contar cuantos puntos cumplen la condición. Y se puede hacer en el mismo bucle que la primera parte.
El día 7 se nos propone un reto muy interesante. En primer lugar, tenemos una lista de tareas que hacer en orden. Cada tarea depende de que otras hayan finalizado. Se nos pide el orden en el que se deberán hacer. Para resolver esto vamos a usar una estructura de datos nueva, el grafo dirigido. No voy a implementarlo yo, sino que voy a usar la magnífica librería networkx.
La idea es construir un grafo dirigido, con las tareas. Un nodo dirigido de C a A significa que antes de hacer la tarea A, C tiene que estar completado. Por supuesto puede darse el caso de que antes de hacer A haya que hacer C y otras tareas.
Vamos a realizar una búsqueda primero en anchura (DFS en inglés). Para ello mantenemos una lista con las tareas completadas y otra lista con las tareas que podríamos empezar a hacer. Cuando completamos una tarea vemos si las tareas a las que llevan necesitan todavía más tareas por realizar o en cambio ya pueden ser añadidas a la lista de "listas para empezar". El enunciado nos indica que ante la situación de dos tareas listas para empezar, se usa el orden alfabético para determinar cuál va antes.
Hace falta además una lista de tareas iniciales, que pueden empezar sin esperar. Esto se hace con dos conjuntos según leemos el archivo. Se hace la diferencia entre ellos y esas tareas no tienen prerrequisitos.
La segunda parte también es muy interesante. Se nos indica que las tareas tienen una duración de N segundos, dependiendo del valor alfabético de la letra. Además, ahora existen 5 trabajadores que pueden ir haciendo tareas en paralelo. ¿En cuánto tiempo podemos acabar todas las tareas?
Bien, partiendo del mismo grafo dirigido ahora vamos a hacer otro tipo de recorrido, también DFS, pero no vamos a añadir nuevos elementos a la lista de forma inmediata, sino cuando hayan sido acabados de procesar. Almacenamos los trabajadores como listas dentro de una lista de trabajadores. Cada trabajador guarda la tarea que estaba haciendo y el segundo en el que acabará. Defino una función para saber si los trabajadores están todos ocupados.
Lo primero a tener en cuenta es que el tiempo no avanza hasta que la lista de tareas que se puede realizar está vacía o los trabajadores están llenos. Luego en cada iteración del bucle, analizamos a los trabajadores. Si no han acabado, no se hace nada. Si ya han acabado y estaban con una tarea, se añade la tarea a la lista de tareas finalizadas, y se analiza si se han desbloqueado nuevas tareas disponibles para realizar. Si la tarea que ha realizado es la última tarea, se acaba el programa.
Por último si hay una tareas disponible para hacer, se la añadimos al trabajador y si no, pues le indicamos que no haga nada (así no añadimos por duplicado la tarea en el futuro).
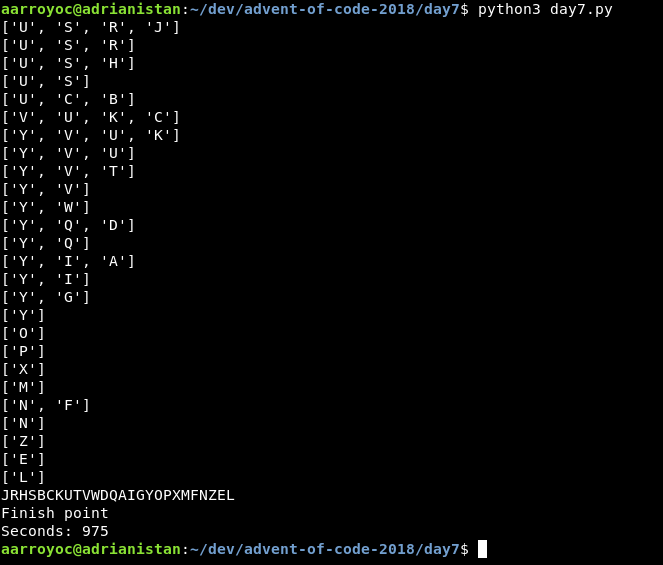 Salida de debug que saqué en el día 7
Salida de debug que saqué en el día 7
Esta ha sido la primera semana del Advent of Code 2018. Como vemos, el nivel de los problemas ha ido aumentado de forma progresiva. La próxima semana comentaré las soluciones correspondientes. Tenéis todo el código hasta ahora aquí.
Los programas que he usado, así como los enunciados y los datos de entrada que me han tocado (a cada uno le tocan datos diferentes) están en este repositorio de GitHub.
Día 1
El primer reto que nos proponen es muy sencillo. Se nos pasa un archivo con sumas y restas y tenemos que calcular el resultado final. Pongamos un ejemplo trivial:
+1, +1, -2 = 0El procesdimiento es sencillo, leer cada operación, extraer el signo, convertir a número y aplicar la operación detectada por el signo.
def apply_freq(freq):
with open("input.txt") as f:
lines = f.readlines()
for line in lines:
signo = line[0:1]
numero = int(line[1:])
if signo == "+":
freq += numero
elif signo == "-":
freq -= numero
return freq
if __name__ == "__main__":
freq = 0
freq = apply_freq(freq)
print("FREQ FINAL: %d" % freq)
La segunda parte es más interesante, ya que nos dice que tenemos que aplicar la misma cadena de operaciones de forma indefinida hasta encontrar una resultado repetido.
Aquí la clave es conocer el funcionamiento de un Set o conjunto. Se trata de una estructura de datos que no permite elementos repetidos. La idea está en ir almacenando los resultados que van saliendo hasta encontrar uno que ya esté dentro. Al encontrarlo salir e indicarlo.
FREQS = set()
def apply_freq(freq):
with open("input.txt") as f:
lines = f.readlines()
for line in lines:
signo = line[0:1]
numero = int(line[1:])
if signo == "+":
freq += numero
elif signo == "-":
freq -= numero
if freq in FREQS:
return (True,freq)
else:
FREQS.add(freq)
return (False,freq)
if __name__ == "__main__":
freq = 0
while True:
end,freq = apply_freq(freq)
if end:
break
print("FREQ FINAL: %d" % freq)
Aquí viene una anécdota interesante. Estoy haciendo estos retos con unos amigos en un grupo de Telegram y al poco de yo haberlo terminado empezaron a preguntar cuánto tardaba en ejecutarse la segunda parte. Al parecer les iba muy lento, yo sorprendido les dije que había sido instantáneo y que estaba usando Python. Ellos se preguntaban como podía ser, ya que lo habían hecho en C y les estaba tardando varios minutos.
Una representación de un set o conjunto. No puede haber elementos repetidos. No existe orden definidoLa respuesta tiene que ver con el set. Yo sinceramente fui a él directamente pero otros compañeros no, y usaron listas y arrays. La búsqueda que realizaban para saber si el elemento estaba dentro era lineal. Comparada con la búsqueda en un set implementado con tabla hash que es constante, el rendimiento es muy inferior. He aquí un ejemplo de como lo más importante de cara a la eficiencia es el algoritmo y las estructuras de datos que usamos para resolver un problema.
Día 2
El segundo día se nos propone otro problema de dificultad similar. Sobre una lista de palabras tenemos que contar cuantas palabras tienen 2 letras repetidas y 3 letras repetidas, para finalmente multiplicar ambos números.
En este caso fui bastante pragmático y opté por usar la clase Counter de Python. Counter cuenta cuantas veces aparece una letra y lo deja en un diccionario. Podemos ignorar las claves, ya que lo único que tenemos que hacer es buscar en los valores si está el 3 y el 2, y si es así, sumar uno a nuestro contador.
from collections import Counter
twice = 0
triple = 0
with open("input.txt") as f:
lines = f.readlines()
for line in lines:
c = Counter(line)
if 3 in c.values():
triple += 1
if 2 in c.values():
twice += 1
total = twice*triple
print("CHECKSUM: %d" % total)
La segunda parte ya es más interesante. Se nos pide que la misma lista de palabras, encontremos las dos palabras que solo se diferencian en una letra (se tiene en cuenta el orden). Aquí el algoritmo es un poco más lento ya que para cada palabra la comparamos con el resto de palabras, hasta encontrar aquella que efectivamente tiene un cambio de únicamente una palabra.
Para ello hace falta una función que nos diga cuantas palabras hay de diferencia entre dos palabras, que es bastante sencillita.
def changes(base,word):
changes = 0
for i,letter in enumerate(base.strip()):
if not letter == word[i]:
changes += 1
return changes
def find_similar(lines):
for base in lines:
for word in lines:
if changes(base,word) == 1:
return (base,word)
with open("input.txt") as f:
lines = f.readlines()
base,word = find_similar(lines)
final = str()
for i,letter in enumerate(base.strip()):
if letter == word[i]:
final += letter
print("FINAL %s"%final)
Una vez tengamos las dos palabras que solo se diferencian en una letra, hacemos un bucle similar al usado para encontrarlas, solo que esta vez para formar la palabra con todas las letras que tienen en común, ignorando la diferente.
Día 3
En el día 3 nos proponen un problema muy interesante. Tenemos una lista de parcelas rectangulares, definidas por la posición de su esquina superior-izquierda y su ancho y alto, todo en metros. Para la primera parte tenemos que encontrar cuantos metros cuadrados del universo ficticio están en dos o más parcelas a la vez.
Lo primero que hay que hacer es leer la entrada, que esta vez ya no es tan trivial. Un simple RegEx nos permite obtener toda la información de forma sencilla.
from dataclasses import dataclass
import re
@dataclass
class Claim():
id: int
x: int
y: int
width: int
height: int
def read_file():
claims = []
with open("input.txt") as f:
lines = f.readlines()
prog = re.compile(r"#([0-9]+) @ ([0-9]+),([0-9]+): ([0-9]+)x([0-9]+)");
for line in lines:
result = prog.match(line.strip())
claim = Claim(
id=int(result.group(1)),
x=int(result.group(2)),
y=int(result.group(3)),
width=int(result.group(4)),
height=int(result.group(5))
)
claims.append(claim)
return claims
Para el algoritmo en sí, vamos a usar defaultdict. La idea es tener una tabla hash, cuya clave sean las coordenadas del mundo y su valor, el número de parcelas que estan sobre ella. Usamos defaultdict para que por defecto cualquier coordenada que no existiese con anterioridad tenga valor 0.
Así pues vamos a recorrer todas las parcelas y para cada parcela vamos a visitar todos los metros cuadrados que contiene en la tabla hash, sumando 1 para indicar que ese metro cuadrado pertenece a una parcela (más).
if __name__ == "__main__":
claims = read_file()
area = defaultdict(lambda: 0)
for claim in claims:
for i in range(claim.x,claim.x+claim.width):
for j in range(claim.y,claim.y+claim.height):
area[(i,j)] += 1
overlaps = count_overlaps(area)
print("Overlaps: %d" % overlaps)
La segunda parte nos indica que solo existe una parcela que no esté invadida por otra parcela. Hay que buscar cuál es e informar del ID que tiene. Para esto he simplemente vuelto a recorrer cada parcela comprobando si tienen algún metro cuadrado con uso por más de 1 parcela. Si para una parcela no se encuentran metros compartidos, automáticamente se devuelve su ID (ya que solo hay una parcela de estas características).
El código completo es el siguiente:
from dataclasses import dataclass
from collections import defaultdict
import re
@dataclass
class Claim():
id: int
x: int
y: int
width: int
height: int
def read_file():
claims = []
with open("input.txt") as f:
lines = f.readlines()
prog = re.compile(r"#([0-9]+) @ ([0-9]+),([0-9]+): ([0-9]+)x([0-9]+)");
for line in lines:
result = prog.match(line.strip())
claim = Claim(
id=int(result.group(1)),
x=int(result.group(2)),
y=int(result.group(3)),
width=int(result.group(4)),
height=int(result.group(5))
)
claims.append(claim)
return claims
def count_overlaps(area):
overlaps = 0
for overlap in area.values():
if overlap > 1:
overlaps += 1
return overlaps
def find_nonoverlaping(claims,area):
for claim in claims:
overlaps = False
for i in range(claim.x,claim.x+claim.width):
for j in range(claim.y,claim.y+claim.height):
if area[(i,j)] > 1:
overlaps = True
if not overlaps:
return claim.id
if __name__ == "__main__":
claims = read_file()
area = defaultdict(lambda: 0)
for claim in claims:
for i in range(claim.x,claim.x+claim.width):
for j in range(claim.y,claim.y+claim.height):
area[(i,j)] += 1
overlaps = count_overlaps(area)
print("Overlaps: %d" % overlaps)
non_overlaping = find_nonoverlaping(claims,area)
print("ID: %d" % non_overlaping)
En esta segunda parte, tengo la intuición de que existe una manera más eficiente de hacerlo, pero todavía no he encontrado esa solución más eficiente.
Día 4
El problema del día 4, aunque aparentemente distinto al anterior, tiene muchas cosas en común y mi forma de resolverlo fue bastante parecida.
Se nos pide que sobre un registro de todas las noches identifiquemos el guardia que duerme más horas, y posteriormente su minuto preferido para quedarse dormido.
En primer lugar, la entrada de texto ya es bastante más compleja, pero con unos simples regex se puede analizar rápidamente, al menos para extraer la información que necesitamos. Aquí conviene prestar atención a que los registros de dormirse y despertarse ya que todos ocurren a la misma hora, luego lo único importante son los minutos. Otro detalle respecto a la entrada es que nos indican que está desordenada, sin embargo el formato de representación de la fecha que nos dan (parecido al ISO), se ordena cronológicamente simplemente con una ordenación alfabética.
La idea es muy similar a la del algoritmo anterior, primero tenemos una tabla hash con todos los guardias. Allí almacenamos otra tabla hash con los minutos de la hora y ponemos un cero si nunca se han dormido en ese minuto. Si usamos defaultdict, como en el código anterior, el código se simplifica bastante. En definitiva estamos usando dos tablas hash en vez de una y aplicar la misma idea de sumar 1, salvo que esta vez con el tiempo en vez del espacio (aunque Einstein vino a decir que eran cosas muy parecidas).
import re
from collections import defaultdict
def read_file():
with open("input.txt") as f:
lines = f.readlines()
lines.sort()
return lines
if __name__ == "__main__":
lines = read_file()
guard_prog = re.compile(r"[* ]+Guard #([0-9]+)")
time_prog = re.compile(r"\[([0-9]+)-([0-9]+)-([0-9]+) ([0-9]+):([0-9]+)")
current_guard = 0
start_time = 0
end_time = 0
timetable = defaultdict(lambda: defaultdict(lambda: 0))
for line in lines:
# Hay tres tipos de líneas
# Guardia, Sleep, Wake
a = guard_prog.match(line.split("]")[1])
if a != None:
current_guard = a.group(1)
elif "falls" in line:
t = time_prog.match(line.split("]")[0])
start_time = int(t.group(5))
elif "wakes" in line:
t = time_prog.match(line.split("]")[0])
end_time = int(t.group(5))
for i in range(start_time,end_time):
timetable[current_guard][i] += 1
# Calcular horas dormido
max_guard = ""
max_guard_sleeptime = 0
for guard in timetable:
s = sum(timetable[guard].values())
if s > max_guard_sleeptime:
max_guard_sleeptime = s
max_guard = guard
print("El guardia que más duerme es el %s con %d minutos" % (max_guard,max_guard_sleeptime))
#Calcular minuto ideal
max_minute = 0
max_minute_times = 0
for minute in timetable[max_guard]:
if timetable[max_guard][minute] > max_minute_times:
max_minute = minute
max_minute_times = timetable[max_guard][minute]
print("El guardia duerme más en el minuto %d (%d veces)" % (max_minute,max_minute_times))
print("CHECKSUM %d" % (max_minute*int(max_guard)))
Posteriormente se recorren estas tablas hash para calcular lo pedido.
La segunda parte nos pide algo similar pero no idéntico, el guardia que se ha quedado dormido más veces en el mismo minuto (e indicar que minuto es).
La estructura de datos es exactamente la misma y solamente añadimos otro bucle para que busque este otro dato:
import re
from collections import defaultdict
def read_file():
with open("input.txt") as f:
lines = f.readlines()
lines.sort()
return lines
if __name__ == "__main__":
lines = read_file()
guard_prog = re.compile(r"[* ]+Guard #([0-9]+)")
time_prog = re.compile(r"\[([0-9]+)-([0-9]+)-([0-9]+) ([0-9]+):([0-9]+)")
current_guard = 0
start_time = 0
end_time = 0
timetable = defaultdict(lambda: defaultdict(lambda: 0))
for line in lines:
# Hay tres tipos de líneas
# Guardia, Sleep, Wake
a = guard_prog.match(line.split("]")[1])
if a != None:
current_guard = a.group(1)
elif "falls" in line:
t = time_prog.match(line.split("]")[0])
start_time = int(t.group(5))
elif "wakes" in line:
t = time_prog.match(line.split("]")[0])
end_time = int(t.group(5))
for i in range(start_time,end_time):
timetable[current_guard][i] += 1
# Calcular horas dormido
max_guard = ""
max_guard_sleeptime = 0
for guard in timetable:
s = sum(timetable[guard].values())
if s > max_guard_sleeptime:
max_guard_sleeptime = s
max_guard = guard
print("El guardia que más duerme es el %s con %d minutos" % (max_guard,max_guard_sleeptime))
#Calcular minuto ideal
max_minute = 0
max_minute_times = 0
for minute in timetable[max_guard]:
if timetable[max_guard][minute] > max_minute_times:
max_minute = minute
max_minute_times = timetable[max_guard][minute]
print("El guardia duerme más en el minuto %d (%d veces)" % (max_minute,max_minute_times))
print("CHECKSUM %d" % (max_minute*int(max_guard)))
# El guardia que ha estado un minuto concreto mas veces dormido
max_guard = ""
guard_minute = 0
guard_minutes = 0
for guard in timetable:
for minute in timetable[guard]:
if timetable[guard][minute] > guard_minutes:
max_guard = guard
guard_minute = minute
guard_minutes = timetable[guard][minute]
print("El guardia %s se ha dormido en el minuto %d (%d veces)" % (max_guard,guard_minute,guard_minutes))
print("CHECKSUM %d" % (guard_minute*int(max_guard)))
En este caso, la segunda parte apenas ha implicado modificaciones, siendo la estructura de datos subyacente intacta.
Día 5
Este día se nos propone un reto aparentemente sencillo, pero cuya resolución puede ser muy lenta o rápida dependiendo de como lo hagamos. He de decir, que mi solución era muy lenta, extremadamente y tuve que mirar como lo habían hecho otras personas para entender como se podía optimizar.
La primera tarea consiste en reducir unas cadenas de reactivos. La norma es que si hay una letra minúscula y una mayúscula al lado, se pueden quitar. Se nos pide la longitud de la cadena de reactivos después de reducirlo al máximo.
if __name__ == "__main__":
with open("input.txt") as f:
line = f.readline()
line = list(line.strip())
end = False
while not end:
end = True
for i in range(1,len(line)):
if line[i-1] != line[i] and line[i-1].lower() == line[i].lower():
end = False
del line[i-1]
del line[i-1]
break
print("Units: %d" % (len(line)))
La versión original consistía en ir realizando elimaciones sobre la propia lista. Todo ello en un bucle que para cuando en una iteración no se modifica la cadena. Esto es extremadamente ineficiente. Tomando el código de Peter Tseng, existe una opción mejor. Se puede ir haciendo un string nuevo poco a poco comprobando si la nueva letra reacciona con la última del string nuevo. Esto tiene la ventaja de que solo hace falta una iteración para cubrir todas las reacciones. La versión mejorada es la siguiente:
def react(line):
new = list()
for c in line.strip():
if len(new) > 0 and c != new[-1] and c.lower() == new[-1].lower():
del new[-1]
else:
new += c
return new
if __name__ == "__main__":
with open("input.txt") as f:
line = f.readline()
line = react(line)
print("Units: %d" % (len(line)))
Para la segunda parte se nos pida que encontremos la letra, que si eliminamos del compuesto antes de empezar la reacción, genera la cadena más pequeña. Hay que probar con todas las letras, mención especial a string.ascii_lowercase que tiene un iterador con todas las letras minúsculas del alfabeto inglés. Y posteriormente, encontrar la que de resultado inferior. Como no nos pide la letra, solamente la longitud que tendría esa cadena, no tenemos que pasar información extra.
import string
def react(line):
new = list()
for c in line:
if len(new) > 0 and c != new[-1] and c.lower() == new[-1].lower():
del new[-1]
else:
new += c
return new
def min_react(line,letter):
line = [c for c in line if c.lower() != letter]
return len(react(line))
if __name__ == "__main__":
with open("input.txt") as f:
line = f.readline()
l = react(line)
print("Units: %d" % (len(l)))
m = min([min_react(line,char) for char in string.ascii_lowercase])
print("Minimum length: %d" % (m))
Día 6
Esto se empieza a complicar. El día 6 nos pide que sobre una cuadrícula encontremos qué punto de control está más cercano a esa posición. De los puntos de control que un número de cuadrículas cercanas finitas, encontrar cuántas cuadrículas tiene el punto de control con más cuadrículas asociadas. Para saber la distancia de una cuadrícula al punto de control se usa la distancia de Manhattan.
Lo primero es reconocer que puntos de control tienen áreas infinitas, para no tenerlos en cuenta.
Para ello, voy a calcular dos puntos extremos (esquina superior izquierda y esquina inferior derecha), dentro del rectángulo que forman estos puntos están contenidos todos los puntos de control. El objetivo es calcular las distancias de las cuadrículas justo por fuera de este rectángulo. Las cuadrículas que estén más lejos de eso no van a cambiar de punto de control, ya que el más cercano en el borde seguirá siendo el más cercano en el borde + N, ya que no hay más puntos de control fuera.
Posteriormente, empezamos a calcular las distancias de todos los puntos de la cuadrícula. Para almacenar los datos vuelvo a usar una tabla hash (defaultdict de Python), donde la clave es la coordenada X,Y y el valor es el punto de control más cercano a esa cuadrícula. Si dos puntos de control están a la misma distancia o no se ha calculado, se usa -1.
Cuando se ha calculado el punto de control más cercano, se revisa si ese punto estaba fuera del rectángulo que contiene a los puntos de control. Si está fuera, el punto de control pasa a un conjunto de puntos con infinitas cuadrículas cercanas.
Para el conteo de cuántas cuadrículas tiene un punto de control que sabemos que es finito, uso otra tabla hash, inicializada por defecto a 0, cuya clave es el identificador de punto de control y su valor, el número de cuadrículas. Después, de los valores almacenados se calcula el máximo.
from dataclasses import dataclass
from collections import defaultdict
import math
@dataclass
class Punto:
x: int
y: int
owner: int
def distancia(p1,p2):
return abs(p1.x-p2.x)+abs(p1.y-p2.y)
if __name__ == "__main__":
with open("input.txt") as f:
lines = f.readlines()
puntosControl = list()
xlist = list()
ylist = list()
for i,line in enumerate(lines):
l = line.split(",")
xlist.append(int(l[0]))
ylist.append(int(l[1]))
puntosControl.append(Punto(x=int(l[0]),y=int(l[1]),owner=i))
esquinaSuperiorIzquierda = Punto(x=min(xlist),y=min(ylist),owner=-1)
esquinaInferiorDerecha = Punto(x=max(xlist),y=max(ylist),owner=-1)
# Los que están fuera del rango esquinaSuperiorIzquierdaxesquinaInferiorDerecha se excluyen automáticamente
excluidos = set()
world = defaultdict(lambda: -1)
for i in range(esquinaSuperiorIzquierda.x-1,esquinaInferiorDerecha.x+2):
for j in range(esquinaSuperiorIzquierda.y-1,esquinaInferiorDerecha.y+2):
punto = Punto(x=i,y=j,owner=-1)
distanciaMin = math.inf
total = 0
for p in puntosControl:
if distancia(punto,p) == distanciaMin:
punto.owner = -1
if distancia(punto,p) < distanciaMin:
distanciaMin = distancia(punto,p)
punto.owner = p.owner
if i == esquinaSuperiorIzquierda.x-1 or i == esquinaInferiorDerecha.x+1 or j == esquinaSuperiorIzquierda.y-1 or j == esquinaInferiorDerecha.y+1:
excluidos.add(punto.owner)
if punto.owner > -1:
world[(i,j)] = punto.owner
conteo = defaultdict(lambda: 0)
for p in world:
if not world[p] in excluidos:
conteo[world[p]] += 1
print("Maximum finite area: %d" % max(conteo.values()))
En la segunda parte nos dicen que hay una región de puntos cuya suma de distancias a todos los puntos de control es menor a 10000. ¿Cuántos puntos forman esta región? Aquí creo que el enunciado no fue demasiado claro, ya que en un principio pensé que podría haber varias áreas, o que podría haber puntos sueltos, no conectados a la región. Sin embargo eso no pasa. Yo diseñé un algoritmo que iba visitando las celdas adyacentes, pero en realidad no hacía falta, simplemente se puede contar cuantos puntos cumplen la condición. Y se puede hacer en el mismo bucle que la primera parte.
from dataclasses import dataclass
from collections import defaultdict
import math
@dataclass
class Punto:
x: int
y: int
owner: int
def distancia(p1,p2):
return abs(p1.x-p2.x)+abs(p1.y-p2.y)
if __name__ == "__main__":
with open("input.txt") as f:
lines = f.readlines()
puntosControl = list()
xlist = list()
ylist = list()
for i,line in enumerate(lines):
l = line.split(",")
xlist.append(int(l[0]))
ylist.append(int(l[1]))
puntosControl.append(Punto(x=int(l[0]),y=int(l[1]),owner=i))
esquinaSuperiorIzquierda = Punto(x=min(xlist),y=min(ylist),owner=-1)
esquinaInferiorDerecha = Punto(x=max(xlist),y=max(ylist),owner=-1)
# Los que están fuera del rango esquinaSuperiorIzquierdaxesquinaInferiorDerecha se excluyen automáticamente
excluidos = set()
world = defaultdict(lambda: -1)
world_total = 0
for i in range(esquinaSuperiorIzquierda.x-1,esquinaInferiorDerecha.x+2):
for j in range(esquinaSuperiorIzquierda.y-1,esquinaInferiorDerecha.y+2):
punto = Punto(x=i,y=j,owner=-1)
distanciaMin = math.inf
total = 0
for p in puntosControl:
if distancia(punto,p) == distanciaMin:
punto.owner = -1
if distancia(punto,p) < distanciaMin:
distanciaMin = distancia(punto,p)
punto.owner = p.owner
total += distancia(punto,p)
if total < 10000:
world_total += 1
if i == esquinaSuperiorIzquierda.x-1 or i == esquinaInferiorDerecha.x+1 or j == esquinaSuperiorIzquierda.y-1 or j == esquinaInferiorDerecha.y+1:
excluidos.add(punto.owner)
if punto.owner > -1:
world[(i,j)] = punto.owner
conteo = defaultdict(lambda: 0)
for p in world:
if not world[p] in excluidos:
conteo[world[p]] += 1
print("Maximum finite area: %d" % max(conteo.values()))
print("Region size: %d" % world_total)
Día 7
El día 7 se nos propone un reto muy interesante. En primer lugar, tenemos una lista de tareas que hacer en orden. Cada tarea depende de que otras hayan finalizado. Se nos pide el orden en el que se deberán hacer. Para resolver esto vamos a usar una estructura de datos nueva, el grafo dirigido. No voy a implementarlo yo, sino que voy a usar la magnífica librería networkx.
La idea es construir un grafo dirigido, con las tareas. Un nodo dirigido de C a A significa que antes de hacer la tarea A, C tiene que estar completado. Por supuesto puede darse el caso de que antes de hacer A haya que hacer C y otras tareas.
Vamos a realizar una búsqueda primero en anchura (DFS en inglés). Para ello mantenemos una lista con las tareas completadas y otra lista con las tareas que podríamos empezar a hacer. Cuando completamos una tarea vemos si las tareas a las que llevan necesitan todavía más tareas por realizar o en cambio ya pueden ser añadidas a la lista de "listas para empezar". El enunciado nos indica que ante la situación de dos tareas listas para empezar, se usa el orden alfabético para determinar cuál va antes.
Hace falta además una lista de tareas iniciales, que pueden empezar sin esperar. Esto se hace con dos conjuntos según leemos el archivo. Se hace la diferencia entre ellos y esas tareas no tienen prerrequisitos.
import networkx as nx
import re
def read_file():
first = set()
second = set()
G = nx.DiGraph()
prog = re.compile("Step ([A-Z]) must be finished before step ([A-Z]) can begin.")
with open("input.txt") as f:
lines = f.readlines()
for line in lines:
r = prog.match(line.strip())
if not r.group(1) in G:
G.add_node(r.group(1))
if not r.group(2) in G:
G.add_node(r.group(2))
if not G.has_edge(r.group(1),r.group(2)):
G.add_edge(r.group(1),r.group(2))
first.add(r.group(1))
second.add(r.group(2))
return (G,first- second)
if __name__ == "__main__":
G,starter = read_file()
path = list()
to_visit = sorted(starter,reverse=True)
while len(to_visit) > 0:
node = to_visit.pop()
path.append(node)
neighbours = G[node]
for n in neighbours:
if not n in to_visit and not n in path:
allCompleted = True
for u,v in G.in_edges(nbunch=n):
if not u in path:
allCompleted = False
if allCompleted:
to_visit.append(n)
to_visit = sorted(to_visit,reverse=True)
print("".join(path))
La segunda parte también es muy interesante. Se nos indica que las tareas tienen una duración de N segundos, dependiendo del valor alfabético de la letra. Además, ahora existen 5 trabajadores que pueden ir haciendo tareas en paralelo. ¿En cuánto tiempo podemos acabar todas las tareas?
import networkx as nx
import re
def read_file():
first = set()
second = set()
G = nx.DiGraph()
prog = re.compile("Step ([A-Z]) must be finished before step ([A-Z]) can begin.")
with open("input.txt") as f:
lines = f.readlines()
for line in lines:
r = prog.match(line.strip())
if not r.group(1) in G:
G.add_node(r.group(1))
if not r.group(2) in G:
G.add_node(r.group(2))
if not G.has_edge(r.group(1),r.group(2)):
G.add_edge(r.group(1),r.group(2))
first.add(r.group(1))
second.add(r.group(2))
return (G,first- second)
def duration(step):
return 60+ord(step)-64
if __name__ == "__main__":
G,starter = read_file()
path = list()
to_visit = sorted(starter,reverse=True)
while len(to_visit) > 0:
node = to_visit.pop()
path.append(node)
neighbours = G[node]
for n in neighbours:
if not n in to_visit and not n in path:
allCompleted = True
for u,v in G.in_edges(nbunch=n):
if not u in path:
allCompleted = False
if allCompleted:
to_visit.append(n)
to_visit = sorted(to_visit,reverse=True)
print("".join(path))
end_letter = path[-1]
path = list()
to_visit = sorted(starter,reverse=True)
second = 0
workers = list()
# Trabajo Actual, segundo que termina
workers.append(['.',0])
workers.append(['.',0])
workers.append(['.',0])
workers.append(['.',0])
workers.append(['.',0])
def full_workers(workers):
full = True
for w in workers:
if w[0] == ".":
full = False
return full
end = False
while not end:
if len(to_visit) == 0 or full_workers(workers):
second += 1
for i in range(0,len(workers)):
if workers[i][1] <= second:
if workers[i][0] != ".":
path.append(workers[i][0])
neighbours = G[workers[i][0]]
for n in neighbours:
if not n in to_visit and not n in path:
allCompleted = True
for u,v in G.in_edges(nbunch=n):
if not u in path:
allCompleted = False
if allCompleted:
to_visit.append(n)
to_visit = sorted(to_visit,reverse=True)
if workers[i][0] == end_letter:
print("Finish point")
print("Seconds: %d" % second)
end = True
if len(to_visit) > 0:
node = to_visit.pop()
workers[i][1] = second+duration(node)
workers[i][0] = node
else:
workers[i][0] = "."
Bien, partiendo del mismo grafo dirigido ahora vamos a hacer otro tipo de recorrido, también DFS, pero no vamos a añadir nuevos elementos a la lista de forma inmediata, sino cuando hayan sido acabados de procesar. Almacenamos los trabajadores como listas dentro de una lista de trabajadores. Cada trabajador guarda la tarea que estaba haciendo y el segundo en el que acabará. Defino una función para saber si los trabajadores están todos ocupados.
Lo primero a tener en cuenta es que el tiempo no avanza hasta que la lista de tareas que se puede realizar está vacía o los trabajadores están llenos. Luego en cada iteración del bucle, analizamos a los trabajadores. Si no han acabado, no se hace nada. Si ya han acabado y estaban con una tarea, se añade la tarea a la lista de tareas finalizadas, y se analiza si se han desbloqueado nuevas tareas disponibles para realizar. Si la tarea que ha realizado es la última tarea, se acaba el programa.
Por último si hay una tareas disponible para hacer, se la añadimos al trabajador y si no, pues le indicamos que no haga nada (así no añadimos por duplicado la tarea en el futuro).
Salida de debug que saqué en el día 7Conclusión
Esta ha sido la primera semana del Advent of Code 2018. Como vemos, el nivel de los problemas ha ido aumentado de forma progresiva. La próxima semana comentaré las soluciones correspondientes. Tenéis todo el código hasta ahora aquí.