Estadística en Python: distribución binomial, normal y de Poisson (Parte VI)
- Adrián Arroyo Calle
Después del rollo del capítulo anterior, vamos a entrar en algo más práctico, modelos de probabilidad. Hemos hablado de las funciones de probabilidad y de densidad, sin embargo, nos falta algo muy importante. ¿Cuáles son esas funciones exactamente? Es donde entran los modelos de probabilidad, modelos estadísticos que se pueden ajustar a una variable aleatoria con mejor o peor precisión y que nos dan los valores de la probabilidad. Empecemos, pero antes hagamos un apunte sobre las equivalencias en SciPy:
Un ensayo de Bernouilli se define como un experimento donde puede darse un éxito o fracaso y donde cada ensayo es independiente del anterior. Por ejemplo, un ensayo de Bernoulli de parámetro 0.5 sería lanzar una moneda a cara o cruz (mitad de posibilidades de cara, mitad de posibilidades de cruz).
Si repetimos N veces los ensayos de Bernouilli tenemos una distribución binomial.
Es decir, de media habría 1 DVD defectuoso en el paquete. mean calcula la media de la distribución.
Para saber si hay que fiarse del vendedor vamos a calcular cuál era la probabilidad de que nos tocasen 4 DVDs defectuosos.
Es decir, la probabilidad que ocurriese era del 1%. Podemos sospechar del fabricante. cdf calcula las probabilidades acumuladas. En este caso tenemos que calcular la probabilidad de que hubiese 4 o más fallos, Pr{X>=4}. Una manera fácil de calcularlo es hacer 1-Pr{X<4}. cdf(n) nos permite calcular probabilidades acumuladas hasta N. Otra opción sería simplemente obtener la probabilidad de 0 DVDs defectuosos, 1 DVD defectuoso, de 2 DVDs defectuosos, de 3 DVDs defectuosos, sumarlo y restarlo de 1.
pmf(n) devuelve la probabilidad de que X=N, Pr{X=N} Esto solo tiene sentido en ciertas distribuciones, las discretas, como es el caso de la binomial.
Podemos calcular la gráfica de esta distribución binomial.
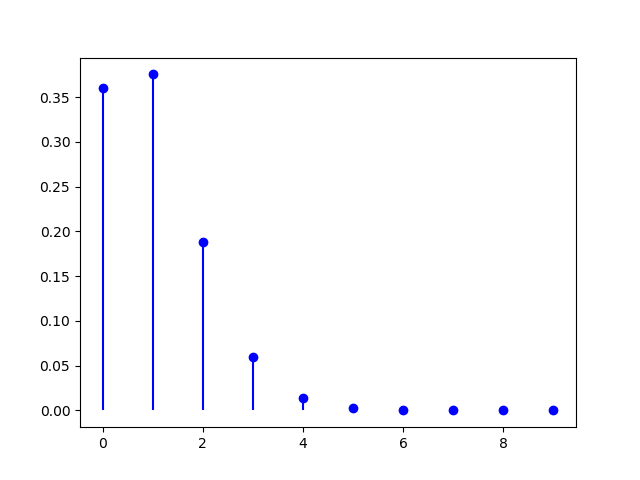 En el gráfico también se puede ver que las probabilidades de tener 4 o más DVDs defectuosos son mínimas.
En el gráfico también se puede ver que las probabilidades de tener 4 o más DVDs defectuosos son mínimas.
La distribución hipergeométrica es un modelo en el que se considera una población finita de tamaño N en la cual hay M individuos con una determinada característica y se seleccionan n y queremos saber la probabilidad de que haya cierto número de individuos con esa característica en la selección. Para trabajar con estas distribuciones, SciPy trae hypergeom.
Ejemplo: Se formó un jurado de 6 personas de un grupo de 20 posibles miembros de los cuales 8 eran mujeres y 12 hombres. El jurado seelecionó aleatoriamente, pero solamente tenía 1 mujer. ¿Hay motivos para dudarde la aletoriedad de la selección?
La probabilidad de que ocurriese lo que ocurrió es del 18,7%, una probabilidad suficientemente alta como para pensar que no hubo manipulación. Podemos dibujar esta hipergeométrica:
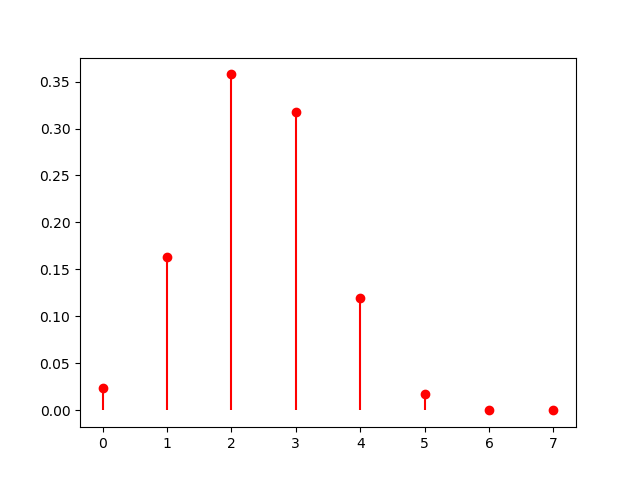 Como se puede observar en la gráfica el caso más probable, con cerca del 35% de posibilidades era que hubiese dos mujeres seleccionadas. Destacar también, que la probabilidad de que haya 7 mujeres en el jurado es cero, porque solo hay 6 plazas en el jurado.
Como se puede observar en la gráfica el caso más probable, con cerca del 35% de posibilidades era que hubiese dos mujeres seleccionadas. Destacar también, que la probabilidad de que haya 7 mujeres en el jurado es cero, porque solo hay 6 plazas en el jurado.
La distribución de Poisson recoge sucesos independientes que ocurren en un soporte continuo. El número medio de sucesos por unidad de soporte se le conoce como λ y caracteriza la distribución. poisson nos permite crear distribuciones de este tipo.
Algunos ejemplos de distribuciones de Poisson: número de clientes que llegan cada hora a cierto puesto de servicio, número de averías diarias de un sistema informático, número de vehículos que pasan diariamente por un túnel, número de defectos por kilómetro de cable, ...
Ejemplo: La impresora de una pequeña red informática recibe una media de 0.1 peticiones por segundo. Suponiendo que las peticiones a dicha impresora son independientes y a ritmo constante, ¿cuál es la probabilidad de un máximo de 2 peticiones en un segundo? Si la cola de la impresora tiene un comportamiento deficiente cuando recibe más de 10 peticiones en un minuto, ¿cuál es la probabilidad de que ocurra esto?
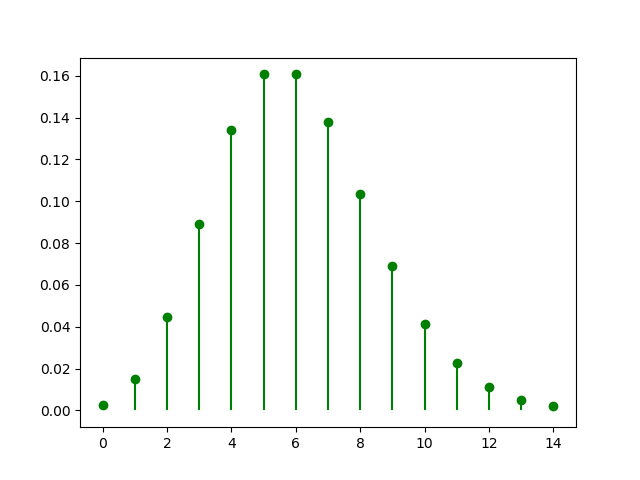 Variable Y: número de peticiones a la impresora en un minuto (y la probabilidad de que suceda)
Variable Y: número de peticiones a la impresora en un minuto (y la probabilidad de que suceda)
Para modelizar el intervalo entre dos sucesos consecutivos que siguen una distribución de Poisson se usa la distribución exponencial de parámetro λ.
Ejemplo: El proceso de accesos a una página web se produce de una forma estable e independiente, siendo el intervalo entre dos accesos consecutivos una v.a. exponencial. Sabiendo que, de media, se produce un acceso cada minuto,¿cuál es la probabilidad de que no se produzcan accesos en 4 minutos? y ¿cuál esla probabilidad de que el tiempo transcurrido entre dos accesos consecutivos sea inferior a 90 segundos?
Esta distribución en SciPy es un poco rara, ya que no está implementada como podría esperarse.
Probablemente el modelo de distribución más usado y conocido. Lo usamos para describir variables reales continuas.
Ejemplo: La duración de un determinado componente electrónico, en horas, es una v.a. que se distribuye según una N(2000,40). ¿Cuál es la probabilidad de que la duración de una de esas componentes sea superior a 1900 horas? ¿y de que esté entre 1850 y 1950 horas?
Podemos representar esta variable.
 Estos modelos no son perfectos, pero son lo suficientemente flexibles para ser un buen punto de partida.
Estos modelos no son perfectos, pero son lo suficientemente flexibles para ser un buen punto de partida.
- cdf(x) - Función de distribución F(X)
- sf(x) = 1 - cdf(x)
- pmf(x) - Función de probabilidad f(x) (distribuciones discretas)
- pdf(x) - Función de densidad f(x) (distribuciones continuas)
- ppf(x) - Función inversa a cdf(x). Nos permite obtener el valor correspondiente a una probabilidad.
Distribución Binomial
Un ensayo de Bernouilli se define como un experimento donde puede darse un éxito o fracaso y donde cada ensayo es independiente del anterior. Por ejemplo, un ensayo de Bernoulli de parámetro 0.5 sería lanzar una moneda a cara o cruz (mitad de posibilidades de cara, mitad de posibilidades de cruz).
Si repetimos N veces los ensayos de Bernouilli tenemos una distribución binomial.
[latex]
X \rightarrow B(N,P)
[/latex]
SciPy nos permite usar binom para trabajar con distribuciones binomiales.
Ejemplo: Un proveedor de DVDs regrabables afirma que solamente el 4 % de los
artículos suministrados son defectuosos. Si un cliente compra un lote de 25
DVDs, ¿cuál es el número esperado de DVDs defectuosos en el lote? Si el cliente
encuentra que 4 de los DVDs comprados son defectuosos, ¿debe dudar de la
afirmación del vendedor?
El número de DVDs defectuosos esperados es el equivalente a decir el número medio de DVDs defectuosos.
import scipy.stats as ss
X = ss.binom(25,0.04)
X.mean() # 1.0
Es decir, de media habría 1 DVD defectuoso en el paquete. mean calcula la media de la distribución.
Para saber si hay que fiarse del vendedor vamos a calcular cuál era la probabilidad de que nos tocasen 4 DVDs defectuosos.
import scipy.stats as ss
X = ss.binom(25,0.04)
pr = X.sf(3) # 0.016521575032415914
Es decir, la probabilidad que ocurriese era del 1%. Podemos sospechar del fabricante. cdf calcula las probabilidades acumuladas. En este caso tenemos que calcular la probabilidad de que hubiese 4 o más fallos, Pr{X>=4}. Una manera fácil de calcularlo es hacer 1-Pr{X<4}. cdf(n) nos permite calcular probabilidades acumuladas hasta N. Otra opción sería simplemente obtener la probabilidad de 0 DVDs defectuosos, 1 DVD defectuoso, de 2 DVDs defectuosos, de 3 DVDs defectuosos, sumarlo y restarlo de 1.
import scipy.stats as ss
X = ss.binom(25,0.04)
pr = 1 - sum(X.pmf(x) for x in range(4))
pmf(n) devuelve la probabilidad de que X=N, Pr{X=N} Esto solo tiene sentido en ciertas distribuciones, las discretas, como es el caso de la binomial.
Podemos calcular la gráfica de esta distribución binomial.
import scipy.stats as ss
import matplotlib.pyplot as plt
X = ss.binom(25,0.04)
x = np.arange(10)
plt.plot(x,X.pmf(x),"bo")
plt.vlines(x,0,X.pmf(x),"b")
plt.show()
En el gráfico también se puede ver que las probabilidades de tener 4 o más DVDs defectuosos son mínimas.Distribución hipergeométrica
La distribución hipergeométrica es un modelo en el que se considera una población finita de tamaño N en la cual hay M individuos con una determinada característica y se seleccionan n y queremos saber la probabilidad de que haya cierto número de individuos con esa característica en la selección. Para trabajar con estas distribuciones, SciPy trae hypergeom.
Ejemplo: Se formó un jurado de 6 personas de un grupo de 20 posibles miembros de los cuales 8 eran mujeres y 12 hombres. El jurado seelecionó aleatoriamente, pero solamente tenía 1 mujer. ¿Hay motivos para dudarde la aletoriedad de la selección?
import scipy.stats as ss
X = ss.hypergeom(20,6,8)
X.cdf(1) # 0.18730650154798736
La probabilidad de que ocurriese lo que ocurrió es del 18,7%, una probabilidad suficientemente alta como para pensar que no hubo manipulación. Podemos dibujar esta hipergeométrica:
Como se puede observar en la gráfica el caso más probable, con cerca del 35% de posibilidades era que hubiese dos mujeres seleccionadas. Destacar también, que la probabilidad de que haya 7 mujeres en el jurado es cero, porque solo hay 6 plazas en el jurado.Distribución de Poisson
La distribución de Poisson recoge sucesos independientes que ocurren en un soporte continuo. El número medio de sucesos por unidad de soporte se le conoce como λ y caracteriza la distribución. poisson nos permite crear distribuciones de este tipo.
Algunos ejemplos de distribuciones de Poisson: número de clientes que llegan cada hora a cierto puesto de servicio, número de averías diarias de un sistema informático, número de vehículos que pasan diariamente por un túnel, número de defectos por kilómetro de cable, ...
Ejemplo: La impresora de una pequeña red informática recibe una media de 0.1 peticiones por segundo. Suponiendo que las peticiones a dicha impresora son independientes y a ritmo constante, ¿cuál es la probabilidad de un máximo de 2 peticiones en un segundo? Si la cola de la impresora tiene un comportamiento deficiente cuando recibe más de 10 peticiones en un minuto, ¿cuál es la probabilidad de que ocurra esto?
import scipy.stats as ss
X = ss.poisson(0.1)
X.cdf(2) # 0.99984534692973537
Y = ss.poisson(6)
Y.sf(10) # 0.042620923582537995
Variable Y: número de peticiones a la impresora en un minuto (y la probabilidad de que suceda)Distribución exponencial
Para modelizar el intervalo entre dos sucesos consecutivos que siguen una distribución de Poisson se usa la distribución exponencial de parámetro λ.
Ejemplo: El proceso de accesos a una página web se produce de una forma estable e independiente, siendo el intervalo entre dos accesos consecutivos una v.a. exponencial. Sabiendo que, de media, se produce un acceso cada minuto,¿cuál es la probabilidad de que no se produzcan accesos en 4 minutos? y ¿cuál esla probabilidad de que el tiempo transcurrido entre dos accesos consecutivos sea inferior a 90 segundos?
Esta distribución en SciPy es un poco rara, ya que no está implementada como podría esperarse.
import scipy.stats as ss
ss.expon.sf(4,loc=0,scale=1) # 0.018315638888734179
ss.expon.cdf(1.5,loc=0,scale=1) # 0.77686983985157021
Distribución normal
Probablemente el modelo de distribución más usado y conocido. Lo usamos para describir variables reales continuas.
Ejemplo: La duración de un determinado componente electrónico, en horas, es una v.a. que se distribuye según una N(2000,40). ¿Cuál es la probabilidad de que la duración de una de esas componentes sea superior a 1900 horas? ¿y de que esté entre 1850 y 1950 horas?
import scipy.stats as ss
X = ss.norm(2000,40)
X.sf(1900) # 0.99379033467422384
X.cdf(1950) - X.cdf(1850) # 0.10556135638165455
Podemos representar esta variable.
import scipy.stats as ss
import numpy as np
import matplotlib.pyplot as plt
X = ss.norm(2000,40)
x = np.arange(X.ppf(0.01),X.ppf(0.99))
plt.plot(x,X.pdf(x),"r")
plt.show()
Estos modelos no son perfectos, pero son lo suficientemente flexibles para ser un buen punto de partida.
Comentarios