Estadística en Python: ajustar datos a una distribución (parte VII)
- Adrián Arroyo Calle
Ya hemos visto con anterioridad que existen modelos que nos hacen la vida más sencilla. Sin embargo, en esos modelos conocíamos ciertos datos de antemano. ¿Qué pasa si tenemos datos y queremos ver si podemos estar ante un modelo de los ya definidos?
Este tipo de ajuste es muy interesante, ya que nos permite saber si los datos en bruto pueden parecerse a los modelos de Normal u otros y aprovecharlo.
Para ajustar datos a una distribución, todas las distribuciones continuas de SciPy cuentan con la función fit. Fit nos devuelve los parámetros con los que ajusta nuestros datos al modelo. ¡Ojo, no nos avisa si es un buen ajuste o no!
Vamos a ajustarlo.
En este caso nos informa de que estos datos parecen encajar con los de una distribución normal de media 160,37 y desviación típica 17,41.
Hemos hecho un ajuste, pero no sabemos qué tan bueno es. Existen varios métodos para poner a prueba los ajustes. Existen varios métodos, siendo los más populares Chi-Cuadrado y Kolmogorov-Smirnov.
Chi-Cuadrado no se puede aplicar directamente sobre distribuciones continuas, aún así voy a explicar como se haría. Sin embargo, primero vamos a probar con Kolmogorov-Smirnov, que en SciPy es ktest.
Este test nos devuelve dos valores: D y el p-valor. Yo voy a fijarme en el p-valor. El p-valor es el nivel mínimo de significación para el cual rechazaremos el ajuste. Cuanto más cerca del 1 esté, más confianza hay en el ajuste, cuanto más cerca de cero esté, menos confianza hay en el ajuste. ¿Pero cómo se interpreta exactamente?
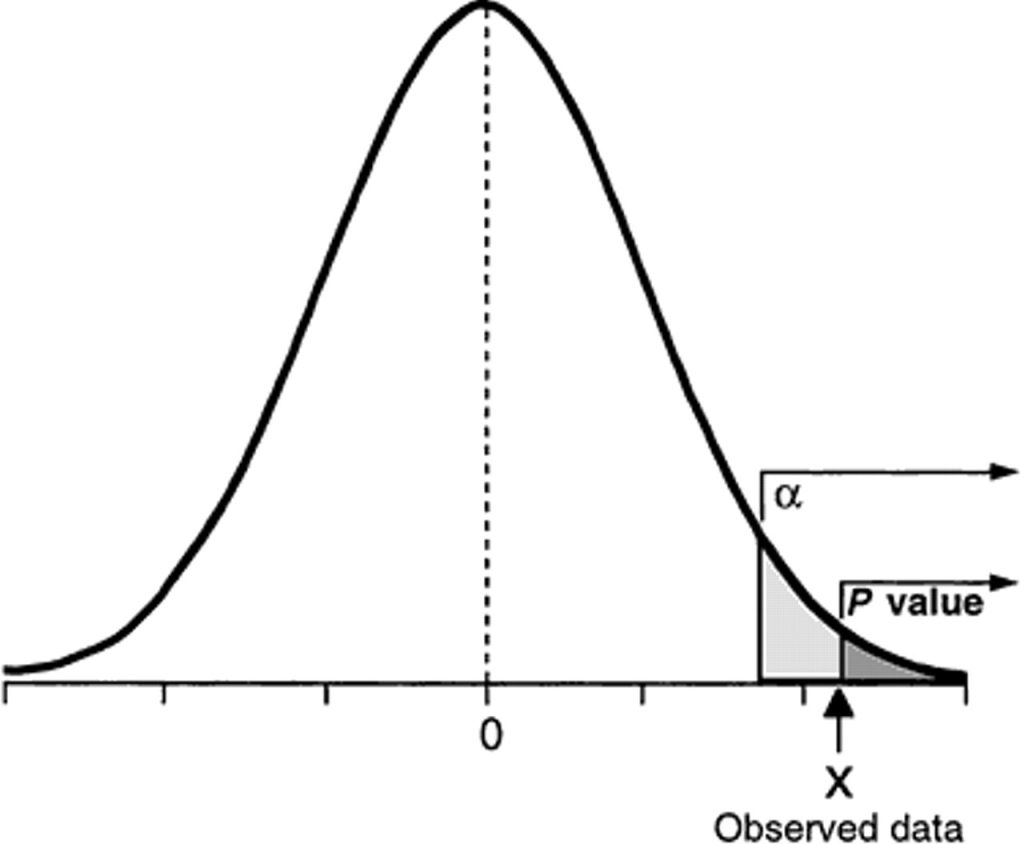
Una forma sencillo de entenderlo es hacer obtener el nivel de significación, que es 1 - NivelConfianza/100. Así para una confianza del 95%, este será de 0.05, para una confianza del 99%, el valor se reduce a 0.01. Si el p-valor es inferior a este nivel de significación, el ajuste probablemente no es correcto.
Aquí algún estadístico más serio se tiraría de los pelos, porque en realidad lo único que se puede demostrar con seguridad es en el caso de que no se ajuste. Si salta que se puede ajustar a una normal, simplemente querría decir que no se puede rechazar la hipótesis de partida (que sea normal), pero no confirma que sea normal.
Esto es algo común en el contraste de hipótesis y con los p-valores en particular y ha suscitado crítica, hasta tal punto que en 2016, la American Statistical Association publicó una serie de consejos para tratar con p-valores. El p-valor en este caso solo puede demostrar que no se ajusta a una normal. No obstante, para ir poco a poco, podemos simplificar esto un poco.
Para hacer el test de Chi-Cuadrado primero hay que dividir los datos continuos. Para uso podemos usar la función de NumPy, histogram o la de SciPy binned_statistic. Tenemos que construir una lista con las frecuencias esperadas si siguiéramos al 100% la distribución a la que queremos ajustarnos.
Una vez tengamos una lista con los valores esperados, simplemente podemos comparar las frecuencias reales con las esperadas con chisquare. Esto nos devolverá C y el p-valor. El significado del p-valor es exactamente igual.
Con esto ya hemos visto como empezar con estadística en Python. No sé si haré más artículos de este estilo, si no es así, espero que os hayan gustado esta serie de artículos. El mundo del data science es inmenso y os invito a seguirlo explorando.
Este tipo de ajuste es muy interesante, ya que nos permite saber si los datos en bruto pueden parecerse a los modelos de Normal u otros y aprovecharlo.
Ajuste de datos a una distribución
Para ajustar datos a una distribución, todas las distribuciones continuas de SciPy cuentan con la función fit. Fit nos devuelve los parámetros con los que ajusta nuestros datos al modelo. ¡Ojo, no nos avisa si es un buen ajuste o no!
Ejemplo: Queremos saber si la altura de los hombres adultos del pueblo de Garray sigue una distribución normal. Para ello tomamos una muestra de 80 alturas de hombres adultos en Garray.
Los datos los tenemos en este CSV, cada altura en una línea:
Altura
180.55743416791302
159.4830930711535
175.54566032406794
149.06378740901533
140.35494067172635
146.65963134242543
171.34024710764376
140.11601629465872
175.6026441151595
158.00860559393507
122.53612034588375
116.10055909040616
152.89225061770068
148.31372767763455
111.17487190927599
160.18952563680827
151.8729737480722
141.50350042949614
165.2379297612276
150.75979657877465
171.5257501059296
157.97922034080895
159.60144363114716
152.52036681430164
172.0678524550487
163.65457704485283
134.9562174388093
189.70206097599245
153.78203142905076
176.1787894042539
190.83025195589502
199.04182673196726
146.97803776211907
174.22118528139467
170.95045320552694
161.2797407784266
190.61061242859464
168.79257731811308
159.87099716863165
136.22823975268153
166.87622973701335
179.58044852016417
172.49583957582817
165.2662334997042
136.6663345224381
161.9352364324168
174.56164027542448
161.62817356012405
167.65579546297906
170.88930983697742
147.22062198310996
151.85737964663497
158.03323614736198
135.77570282853696
161.25435141827515
193.33084953437478
155.43189514766172
155.89204074847055
179.23931091736836
146.485962651657
166.61617663518228
161.70927578953211
164.89798613982495
139.18195138901498
180.30341647946335
162.4811239647979
171.1035005376699
147.01137545913147
187.03282087175134
172.2476631392949
152.9814634955974
174.43159049461713
174.83877117002814
132.66857703218636
173.98029972846837
133.5435543737402
169.62941676289472
166.4887567852903
138.1150540623029
170.52532661450618
Vamos a ajustarlo.
import pandas as pd
import scipy.stats as ss
df = pd.read_csv("alturas.csv")
media, desviacion = ss.norm.fit(df["Altura"])
print(media) # media = 160,37
print(desviacion) # desviacion = 17,41
En este caso nos informa de que estos datos parecen encajar con los de una distribución normal de media 160,37 y desviación típica 17,41.
¿Cómo de bueno es el ajuste? Kolmogorov
Hemos hecho un ajuste, pero no sabemos qué tan bueno es. Existen varios métodos para poner a prueba los ajustes. Existen varios métodos, siendo los más populares Chi-Cuadrado y Kolmogorov-Smirnov.
Chi-Cuadrado no se puede aplicar directamente sobre distribuciones continuas, aún así voy a explicar como se haría. Sin embargo, primero vamos a probar con Kolmogorov-Smirnov, que en SciPy es ktest.
import pandas as pd
import scipy.stats as ss
df = pd.read_csv("altura.csv")
media, desviacion = ss.norm.fit(df["Altura"])
d, pvalor = ss.ktest(df["Altura"],"norm",args=(media,desviacion))
# o alternativamente
d, pvalor = ss.ktest(df["Altura"],lambda x: ss.norm.cdf(x,media,desviacion))
Este test nos devuelve dos valores: D y el p-valor. Yo voy a fijarme en el p-valor. El p-valor es el nivel mínimo de significación para el cual rechazaremos el ajuste. Cuanto más cerca del 1 esté, más confianza hay en el ajuste, cuanto más cerca de cero esté, menos confianza hay en el ajuste. ¿Pero cómo se interpreta exactamente?
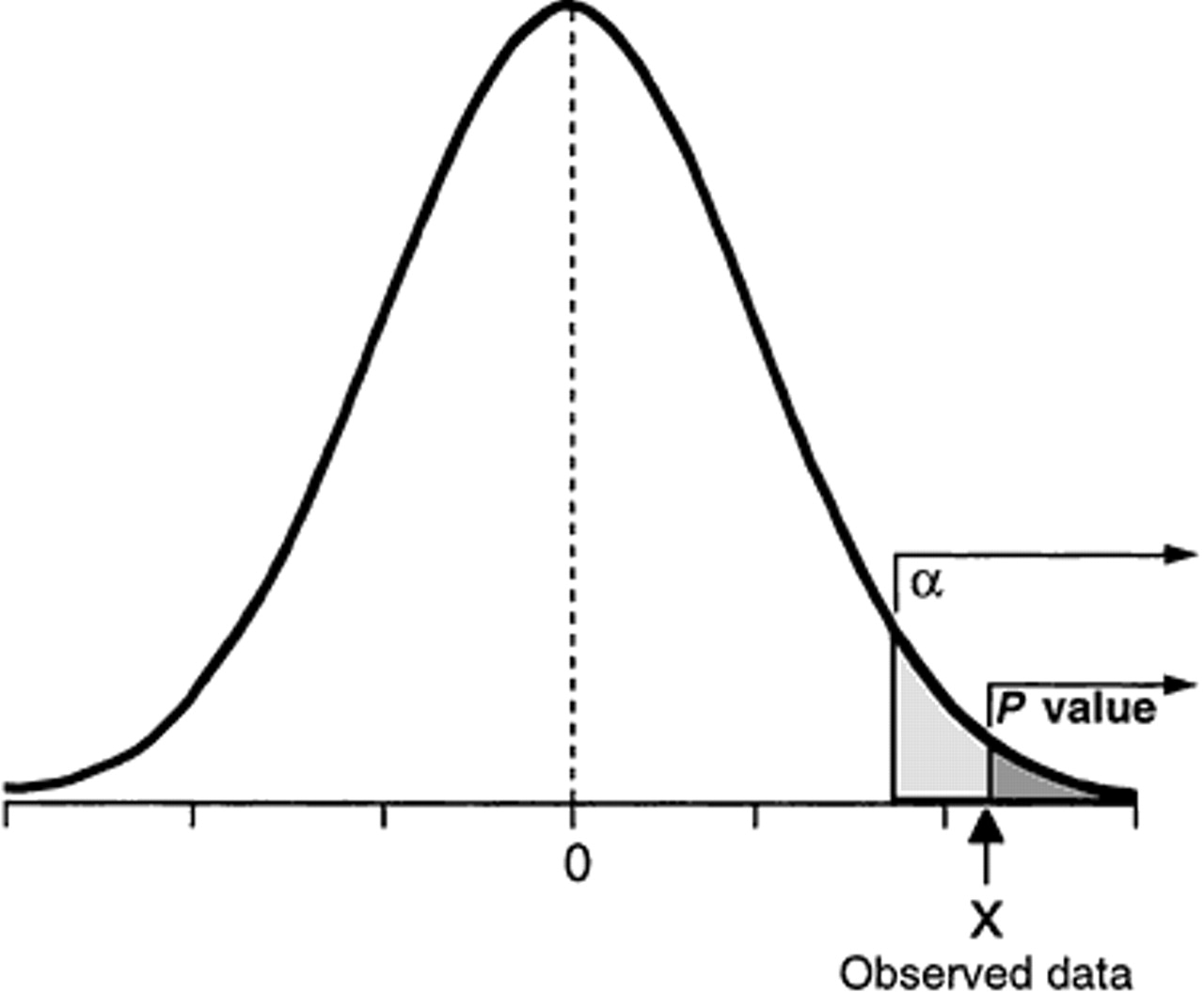
Una forma sencillo de entenderlo es hacer obtener el nivel de significación, que es 1 - NivelConfianza/100. Así para una confianza del 95%, este será de 0.05, para una confianza del 99%, el valor se reduce a 0.01. Si el p-valor es inferior a este nivel de significación, el ajuste probablemente no es correcto.
import pandas as pd
import scipy.stats as ss
df = pd.read_csv("altura.csv")
media, desviacion = ss.norm.fit(df["Altura"])
d, pvalor = ss.ktest(df["Altura"],"norm",args=(media,desviacion))
# queremos confianza al 99%
if pvalor < 0.01:
print("No se ajusta a una normal")
else:
print("Se puede ajustar a una normal")
Aquí algún estadístico más serio se tiraría de los pelos, porque en realidad lo único que se puede demostrar con seguridad es en el caso de que no se ajuste. Si salta que se puede ajustar a una normal, simplemente querría decir que no se puede rechazar la hipótesis de partida (que sea normal), pero no confirma que sea normal.
Esto es algo común en el contraste de hipótesis y con los p-valores en particular y ha suscitado crítica, hasta tal punto que en 2016, la American Statistical Association publicó una serie de consejos para tratar con p-valores. El p-valor en este caso solo puede demostrar que no se ajusta a una normal. No obstante, para ir poco a poco, podemos simplificar esto un poco.
Chi-Cuadrado
Para hacer el test de Chi-Cuadrado primero hay que dividir los datos continuos. Para uso podemos usar la función de NumPy, histogram o la de SciPy binned_statistic. Tenemos que construir una lista con las frecuencias esperadas si siguiéramos al 100% la distribución a la que queremos ajustarnos.
def test_chicuadrado(data,N):
n = data.count()
freqs, edges, _ = ss.binned_statistic(data,data,statistic="count")
def ei(i):
return n*(N.cdf(edges[i])- N.cdf(edges[i-1]))
expected = [ei(i) for i in range(1,len(edges))]
return ss.chisquare(freqs,expected)
Una vez tengamos una lista con los valores esperados, simplemente podemos comparar las frecuencias reales con las esperadas con chisquare. Esto nos devolverá C y el p-valor. El significado del p-valor es exactamente igual.
Con esto ya hemos visto como empezar con estadística en Python. No sé si haré más artículos de este estilo, si no es así, espero que os hayan gustado esta serie de artículos. El mundo del data science es inmenso y os invito a seguirlo explorando.
Comentarios